Redis机器性能那么强,到底有哪些让人惊喜的优点和效率优势呢?

(来源:基于Redis官方文档、技术社区共识及行业应用实践总结)
Redis之所以让人感觉性能强大,并不仅仅是因为它“快”,更在于它为了实现这种极致的效率,在设计上做出的一系列巧妙选择,这些选择共同作用,带来了许多令人惊喜的优点和效率优势。
第一,数据直接在内存中操作,这是速度的基石。 绝大多数传统数据库(比如MySQL)在更新数据时,需要先把数据写入磁盘,这个过程涉及到慢速的I/O操作,是性能的主要瓶颈,而Redis选择将所有数据都放在服务器的内存(RAM)里,内存的读写速度是硬盘的几十甚至上百倍,这就好比从你手边的桌子上拿一本书,和从远处图书馆的书架上找一本书的差别,所有对数据的增、删、改、查操作都在内存中完成,这使得Redis能够轻松应对每秒数十万甚至上百万次的请求,为了防止服务器重启或断电导致数据丢失,Redis也提供了可选的持久化机制(如RDB快照和AOF日志),但这是在后台异步完成的,不影响前台处理命令的速度。
第二,单线程架构避免了多线程的烦恼,简化了设计。 你可能会疑惑,现在CPU都是多核的,为什么Redis还坚持用单线程模型来处理网络请求和键值操作?这恰恰是Redis设计的高明之处,多线程虽然能利用多核,但会引入复杂的锁机制和线程切换的开销,当多个线程同时竞争修改同一块数据时,管理不好就容易导致性能下降甚至死锁,Redis的单线程模型意味着,它在任何时刻都只用一个CPU核心来处理一个命令,完全避免了锁的竞争和线程上下文切换的消耗,这使得Redis的内部实现变得非常简单和可预测,代码更健壮,对于绝大多数操作都是极快的内存访问来说,单线程的处理能力已经足够强大,瓶颈往往在网络带宽和内存大小,而不是CPU。
第三,高效的数据结构是它的“秘密武器”。 Redis不仅仅是简单的键值存储,它的“值”可以是多种高级数据结构,如列表(List)、集合(Set)、有序集合(Sorted Set)、哈希(Hash)等,这些都不是简单的封装,而是Redis针对每种数据结构的特点,在底层用C语言精心设计和优化的,它的字符串类型采用类似数组的简单结构;列表在元素较少时使用一种叫“压缩列表”的紧凑存储方式,节省内存;哈希表在扩容时采用了“渐进式rehash”策略,避免一次性迁移所有数据导致的服务器停顿,这些精心打磨的数据结构,使得在使用Redis完成复杂业务逻辑时(比如计算共同好友、维护排行榜),其内置的操作命令本身就极其高效,你不需要在应用层写复杂的代码,直接调用Redis命令就能完成,效率自然远超自己在程序里处理。
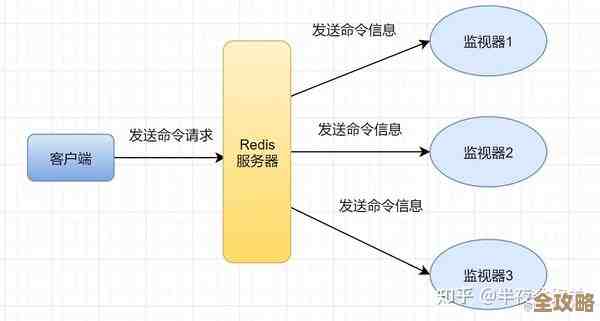
第四,非阻塞I/O多路复用,高并发的关键。 虽然处理命令是单线程,但Redis却能同时处理成千上万个客户端的连接请求,这得益于它使用的I/O多路复用技术(如Linux上的epoll),可以把它想象成一个高效的餐厅服务员,传统的一个线程服务一个客户的模式,就像每个顾客配一个服务员,人多了就需要大量服务员,成本高且管理混乱,而I/O多路复用则像一个超级服务员,他同时照看所有餐桌(网络连接),当某张桌子的客人点好菜(数据准备好)时,他就过去下单(处理命令),这个服务员(单线程)一直在忙碌,但不会因为等待某个客人慢慢看菜单(网络延迟)而阻塞,从而最大限度地利用CPU时间,实现了极高的并发连接处理能力。
第五,无与伦比的实用性与丰富的功能场景。 Redis的强大性能直接催生了其在现代应用中的广泛用途,这些用途本身就体现了其效率优势,用它做缓存,能极大减轻后端数据库的压力,让网站响应快如闪电;用它的过期(expire)特性可以实现高效的短信验证码缓存;用它的原子性自增(INCR)命令可以做秒杀场景的库存计数,避免超卖;用它的有序集合(ZSET)可以轻松实现实时排行榜,性能远超数据库的ORDER BY;用它的发布订阅(Pub/Sub)功能可以构建简单的实时消息系统,这些功能因为Redis的高性能而变得可行和高效,直接提升了整个应用的响应能力和用户体验。
Redis的强性能是一个系统工程的结果:内存存储带来了基础速度,单线程模型保证了简单与稳定,精妙的数据结构提供了操作效率,I/O多路复用支撑了海量并发,而最终这些优势共同转化为解决实际业务问题的强大能力。 它就像一个高度专业化的工具,在它擅长的领域内,通过极简、专注的设计,达到了令人惊喜的效率高度。

本文由邝冷亦于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/67318.html