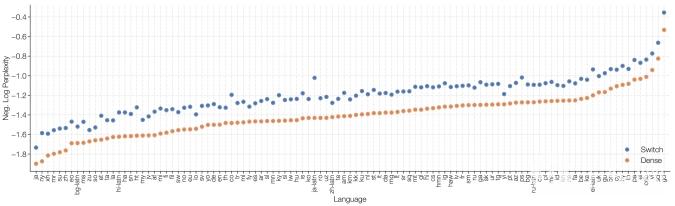
Redis读取慢了咋办,优化性能提升耗时别慌着急试试这些方法

别一发现Redis慢了就急着去改配置或者重启服务器,慌慌张张最容易出错,咱们得像个侦探一样,一步步排查,找到真正的“元凶”,核心思路就一个:先找到慢在哪,再对症下药。
第一步:拿出“测速仪”,看看究竟有多慢
你自己感觉慢不行,得用数据说话,Redis自带了一个超级好用的工具,叫慢查询日志(Slow Log),它就像个黑匣子,会记录下所有执行时间超过你设定阈值的命令。
怎么用呢?通过命令 CONFIG SET slowlog-log-slower-than 10000 来设置阈值,单位是微秒(10000微秒 = 10毫秒),意思是,超过10毫秒的命令都会被记录下来,你可以先设成10毫秒,如果日志太多,再适当调小,设置完后,用 SLOWLOG GET 命令就能查看具体的慢查询记录了,记录里会清清楚楚地告诉你:是哪个命令慢了(比如一个复杂的 HGETALL),是什么时候执行的,具体花了多长时间,这是所有优化的起点,这个方法是Redis官方文档里明确说明的。
第二步:分析慢查询日志,揪出“捣蛋鬼”
拿到慢查询日志后,重点看这几类常见问题:
-
是否使用了“重量级”命令? 比如一次性获取一个包含几万甚至几十万元素的Set集合(
SMEMBERS),或者对一个超大的Hash键使用HGETALL把所有数据都取出来,这种操作会一次性占用大量CPU和网络带宽,不慢才怪。- 怎么办? 优化业务代码,如果真想获取大量数据,试试用
SSCAN、HSCAN这类游标方式的命令分批获取,虽然可能会多几次请求,但对Redis服务端的压力小得多,整体稳定性更高,这个优化思路在众多数据库性能优化实践中是相通的。
- 怎么办? 优化业务代码,如果真想获取大量数据,试试用
-
是不是某个Key太大了? 一个Key对应的Value值特别大(比如一个String类型的Value有好几百KB),读取和传输它自然就费时间,你可以用
redis-cli --bigkeys这个命令来扫描一下数据库,找出哪些Key是“大块头”。
- 怎么办? 考虑拆分大Key,比如一个大的Hash,可以按业务维度拆分成多个小的Hash,或者检查业务逻辑,是不是真的需要存储这么大的数据,有没有压缩的可能性。
-
是不是命令数量太多了? 有些时候,慢不是因为单个命令慢,而是应用程序在循环里发了成千上万的
GET命令,每个命令都产生一次网络往返。- 怎么办? 使用管道(Pipeline) 技术,把多个命令打包成一个请求发送给Redis,Redis处理完后再一次性返回结果,这能极大地减少网络往返次数,提升效率,这就像是把一件件快递分开寄送改成用一个大箱子打包寄送,省下了大量的路上时间,这也是Redis官方推荐的最佳实践。
第三步:检查Redis本身的状态和运行环境
如果慢查询日志里没发现明显问题,或者问题比较普遍,那就要看看Redis的“健康状况”和它的“居住环境”了。
-
内存不够用了? 通过
INFO memory命令查看内存使用情况,如果内存快用满了,Redis可能会触发淘汰机制(如果设置了淘汰策略),甚至开始和磁盘交换(Swap),一旦发生Swap,速度会呈指数级下降。- 怎么办? 要么增加服务器内存,要么优化数据,删除不用的Key,或者调整内存淘汰策略(通过
maxmemory-policy配置)。
- 怎么办? 要么增加服务器内存,要么优化数据,删除不用的Key,或者调整内存淘汰策略(通过
-
CPU扛不住了吗? 使用
INFO cpu命令观察CPU使用率,如果持续很高,可能是Redis实例的负担确实太重了。
- 怎么办? 检查是否有持久化操作(如RDB快照或AOF重写)在后台运行,它们会消耗CPU和磁盘IO,可以考虑在从库上做持久化,减轻主库压力,如果业务量确实大,就要考虑升级硬件或者搭建Redis集群,把压力分散开。
-
网络出问题了? 网络延迟高或者带宽被打满,也会导致读取变慢,这尤其容易发生在Redis服务器和应用程序服务器不在同一个机房或者网络环境复杂的情况下。
- 怎么办? 用
ping和traceroute等网络工具检查延迟和路由,确保Redis服务器和应用服务器在同一个局域网内,或者使用高质量的内网通信。
- 怎么办? 用
-
被其他进程“抢资源”了? 检查一下Redis服务器上是否还运行着其他耗CPU、耗内存、耗磁盘IO的进程,比如一些监控脚本、日志处理工具甚至其他应用服务。
- 怎么办? 遵循一个基本原则:Redis服务器最好单独部署,不要和别的应用挤在一起,给它一个清净的环境,它才能跑得快。
第四步:考虑一些进阶的架构优化
如果上述基础检查都做了,还是慢,可能就得从架构层面想想了。
- 热点Key问题: 如果某一个Key被超高并发地访问,它可能会成为瓶颈,对于这种场景,可以在应用层使用本地缓存(如Guava Cache、Caffeine),先查本地缓存,没有再查Redis,减轻Redis压力。
- 数据分片(集群): 如果数据量巨大,单个Redis实例无论如何也扛不住,就应该使用Redis Cluster集群模式,将数据自动分布到多个节点上,实现水平扩展。
当你发现Redis读取变慢时,别慌:
- 先查慢日志(Slow Log),定位是哪些命令慢。
- 优化慢命令,避免大Key,多用Pipeline。
- 检查服务器状态,看内存、CPU、网络、磁盘是否正常。
- 清理运行环境,确保Redis独占资源。
- 最后考虑架构升级,如引入本地缓存、搭建集群。
耐心和细致是解决性能问题的关键,从最简单、最可能的地方入手,一步步排除,总能找到问题的根源。
本文由召安青于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/67348.html