火力全开用Redis搞缓存,海量数据存取速度杠杠的,性能提升真明显

“火力全开用Redis搞缓存,海量数据存取速度杠杠的,性能提升真明显”这个说法,说白了就是把Redis这个内存数据库当成一个超级快的临时仓库,把那些经常要查、但又不需要每次都去翻底层大库(比如MySQL)的数据先搬过来放着,这样一来,应用程序想用这些数据的时候,就不用吭哧吭哧地去绕远路访问速度相对较慢的硬盘数据库了,直接从这个内存仓库里拿,速度自然就飞起来了,这就像是把常用的工具从地下室工具箱里拿出来,直接放在手边的桌面上,用的时候随手一拿,省去了上下楼的时间,效率能不高吗?

那具体是怎么个“火力全开”法呢?首先得搞清楚什么样的数据适合往Redis这个“桌面”上放,就是那些读的次数远远多于写的、对实时性要求比较高、但本身变化又不是特别频繁的数据,电商网站里商品的详情信息(像名称、价格、图片链接,价格可能变,但不会一秒变好几次)、新闻网站的热点文章列表、社交媒体的用户最新动态、还有那个让人又爱又恨的验证码等等,把这些数据在Redis里存一份副本,当用户请求过来时,程序先奔着Redis去查,如果Redis里有(这叫缓存命中),立马返回,用户感觉就是“秒开”;如果Redis里没有(这叫缓存未命中),再去查主数据库,拿到数据后,除了返回给用户,还不忘在Redis里也存一份,方便下一个用户来查,这个过程,就像是给慢速的主数据库前面加了一道闪电般的屏障。
光知道存什么还不够,怎么存也是个技术活,Redis支持好几种数据结构,不只是简单的键值对,可以用字符串类型存单个对象,比如一个用户的完整信息打包成JSON字符串存起来;用哈希类型来存一个对象的多个字段,比如一个商品的各种属性,可以分别更新,更节省空间;用列表或有序集合来存排行榜、最新评论列表这种带顺序的数据;用集合来存好友关系、标签这类需要判断是否存在、需要求交集并集的数据,选对了数据结构,不仅能存得下,查起来也更高效,这才是真正的“物尽其用”。

用Redis也不是说把数据往里一扔就万事大吉了,有几个关键点不注意,反而会惹出麻烦,第一个就是缓存和底层数据库的数据一致性问题,后台管理员修改了某个商品的价格,数据库里的价格更新了,但如果Redis里的缓存还没更新或者过期,用户看到的就是旧价格,这就出错了,所以得有策略来保证两边数据尽量一样,常见的办法有:更新数据库的同时,也直接更新缓存(写穿透),或者让对应的缓存失效(写失效),等下次读取时再重新加载,这里面的选择要看具体业务对一致性的要求有多高。
第二个头疼的问题是缓存穿透,想象一下,如果有人使坏,一直用一个根本不存在的数据ID来疯狂查询,比如查一个不存在的商品详情,每次请求在Redis里都找不到(未命中),然后都会去查数据库,数据库也查不到,这样大量的无效请求就直接压到了数据库上,缓存形同虚设,数据库可能就被压垮了,解决办法通常是在Redis里也缓存一下这种“空结果”,比如把这个不存在的商品ID作为key,值设成一个特殊的标记(如null),并设置一个较短的过期时间,这样下次再有人用这个ID来查,在Redis层面就直接返回空结果了,保护了数据库,或者,在程序逻辑里先做一层参数校验,把明显无效的请求直接拦掉。
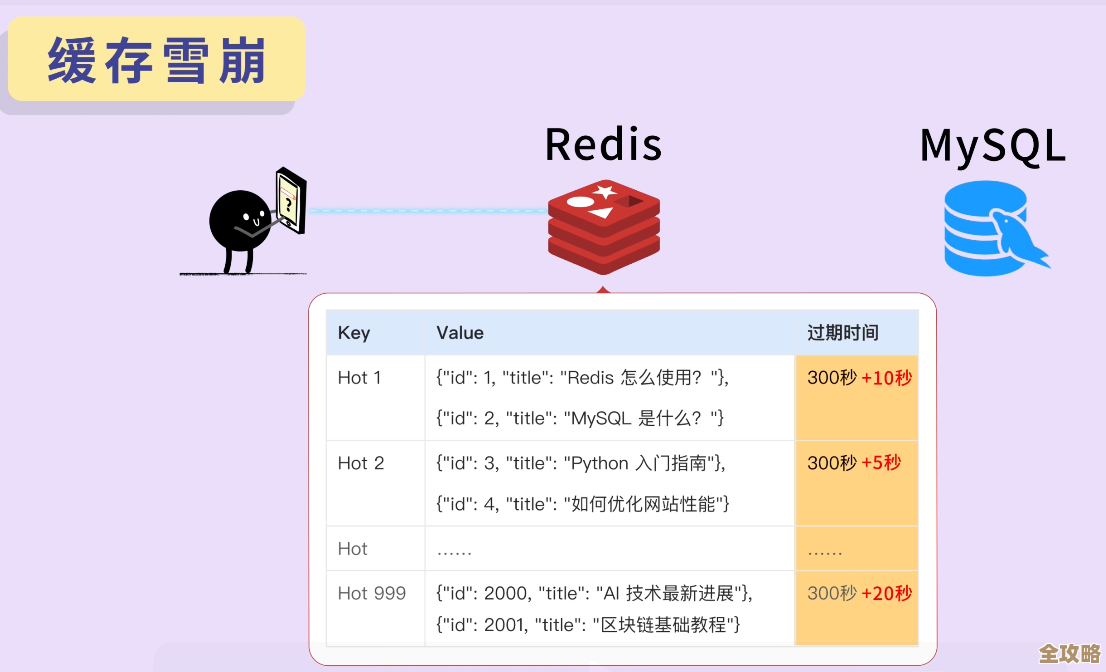
第三个是缓存雪崩,这指的是Redis里大量的缓存数据在同一时间段集体失效了,或者Redis服务本身挂掉了,导致所有的请求一下子全都涌向数据库,数据库肯定承受不住,整个系统就可能崩溃,避免雪崩,可以给不同的缓存数据设置随机的过期时间,让它们别在同一时刻失效;或者采用高可用的Redis集群方案,即使一台Redis机器宕机,其他的还能顶上;也可以让一些热点数据永不过期,通过后台程序定时去更新它。
缓存也不是越大越好,内存毕竟比硬盘贵,当Redis内存快满了的时候,它需要有策略淘汰掉一些数据,常见的策略有LRU(最近最少使用),就是把最久没被访问过的数据踢出去;或者LFU(最不经常使用),踢掉访问次数最少的数据,根据业务特点选对淘汰策略,才能让有限的内存空间缓存最有价值的数据。
“火力全开用Redis搞缓存”绝不是简单地把数据往里一塞,而是一个系统工程,需要仔细规划缓存什么数据、用什么结构存、如何处理数据更新、如何防止各种异常情况,只要把这些环节都考虑周到,配置得当,Redis就能真正发挥出它内存速度的优势,让海量数据的存取变得“杠杠的”,用户体验和系统性能的提升,那绝对是实实在在、非常明显的,它就像给应用程序装上了火箭助推器,尤其是在高并发、大数据量的场景下,效果尤为突出。

本文由称怜于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/67663.html