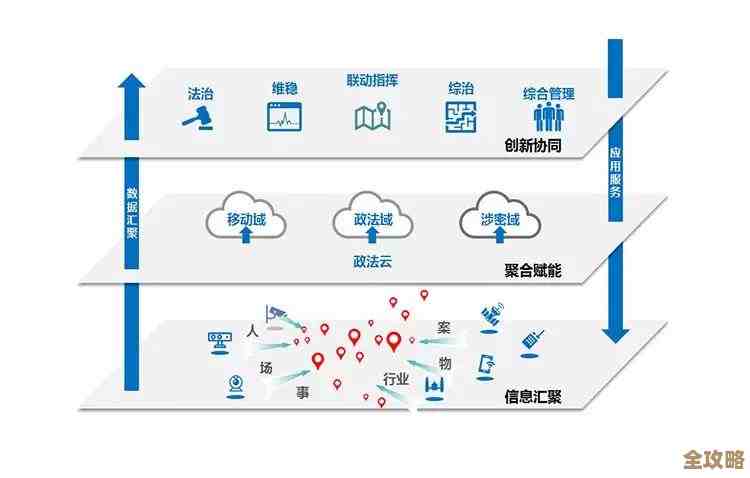
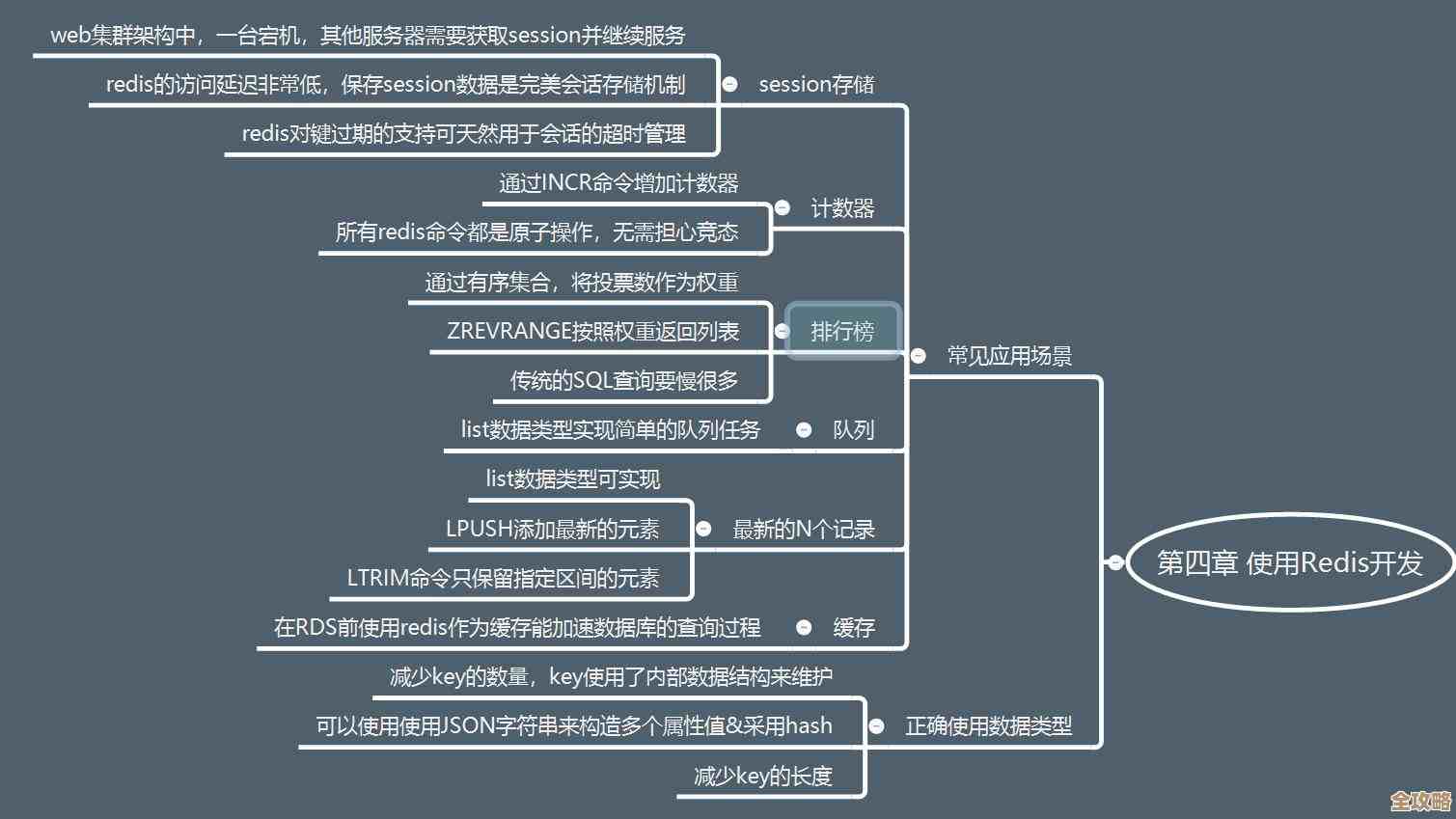
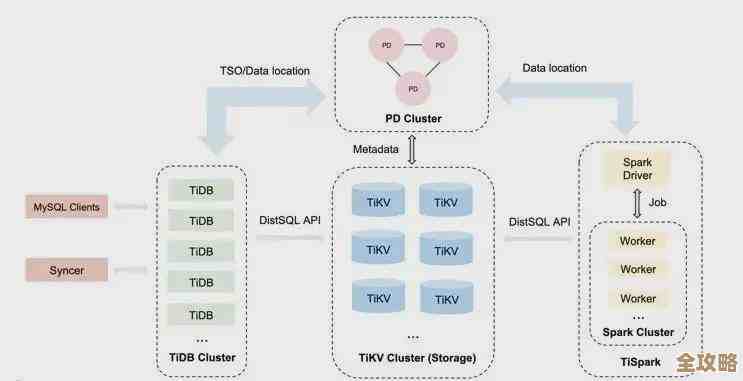
其实就是想说PostgreSQL里那个checkpoint到底是啥,怎么用,有啥讲究

其实你想问的PostgreSQL里的checkpoint(检查点),可以把它想象成游戏里的“存档点”,你玩一个很长的RPG游戏,不可能每打一个怪、每说一句话都立刻保存到硬盘上,那样游戏会卡得没法玩,你通常是玩一段时间,到了一个安全的地方,手动或者等游戏自动帮你存个档,PostgreSQL的checkpoint干的就是这个“存档”的活儿。
它到底是啥?
简单说,checkpoint是PostgreSQL将内存中所有被修改过的数据(我们叫“脏数据”),安全地、批量地同步到硬盘数据文件中的过程。
我们来拆解一下这个过程:
- 内存 vs. 硬盘:PostgreSQL运行的时候,数据主要待在内存的一个叫“共享缓冲区”的地方,你增删改查数据,其实大部分时候都是在和内存打交道,因为操作内存的速度比直接读写硬盘快成千上万倍,为了提高性能,数据修改后不会立刻写回硬盘。
- 脏数据:内存里的数据被修改了,但硬盘上的老数据还没更新,这时候内存里这个“新版”数据就是“脏数据”,它和硬盘上的数据不一致。
- 存档点:checkpoint发生时,PostgreSQL会做一个标记,然后说:“好了,从现在开始,我要把此时此刻内存里所有‘脏数据’都给我老老实实地写到硬盘上去!” 写完之后,硬盘上的数据就和checkpoint那个时间点的内存数据完全一致了。
checkpoint的核心作用就是在内存的高性能和硬盘的数据持久化之间找一个平衡点,它定期把内存里的变化“固化”到硬盘上,确保数据不会因为突然断电等意外而大量丢失。

它怎么工作?有啥用?
理解了它是存档点,它的作用和用法就很好懂了。
-
主要作用:崩溃恢复的起点 这是checkpoint最重要的价值,万一数据库服务器突然断电崩溃了,重启的时候怎么办?它不可能从最后一次操作开始恢复,因为很多操作还在内存里,没写进硬盘,丢了。 这时候,数据库会从最后一个成功的checkpoint 开始恢复,它会读取一种叫“WAL(预写式日志)”的文件(这个日志文件记录了所有修改操作),从checkpoint之后的位置开始,把那些已经发生但还没写入数据文件的操作重新做一遍,这样,数据库就能恢复到崩溃之前的状态。 你可以这么想:checkpoint就是那个完整的存档,WAL日志是存档之后你玩的每一个操作记录,崩溃就像游戏死机,重启后游戏先读取你的最新存档,然后根据操作记录快进到你死机前的那一刻,显然,存档点越近,需要“回放”的日志就越少,恢复时间就越短。
-
触发方式 checkpoint的触发主要有两种:

- 自动触发:这是最常见的,由几个参数控制,最主要的是
checkpoint_timeout(每隔多久强制触发一次,默认5分钟)和max_wal_size(WAL日志总大小达到多少时触发),可以理解为“定时存档”和“日志快满了就存档”。 - 手动触发:你可以在数据库里执行一个SQL命令:
CHECKPOINT;,这就像你马上要关服务器了,或者要做一些重要的维护操作之前,手动强制存个档,让恢复起点更新一点,平时一般不用管它。
- 自动触发:这是最常见的,由几个参数控制,最主要的是
使用它有啥讲究?(调优和注意事项)
“存档”这个操作本身是好事,但存档的过程是有代价的,你正在激烈打BOSS,游戏突然卡住不动了,屏幕上出现“正在保存...”,你烦不烦?数据库也一样,checkpoint会集中进行大量的硬盘写入(I/O)操作,如果这个I/O冲击太大,就会影响同时进行的正常查询性能。
对checkpoint的“讲究”主要就是如何平滑I/O,减少对系统性能的冲击。
-
关键参数:
checkpoint_completion_target这个参数非常重要,它控制了checkpoint的“速度”,它表示在一次checkpoint间隔(由checkpoint_timeout决定)内,用多长的时间来完成脏数据的写入,默认是0.5(即50%的时间)。
- 举个例子:如果
checkpoint_timeout是5分钟,那么默认情况下,PostgreSQL会试图在2.5分钟内慢慢悠悠地把脏数据写完。 - 调优:如果你的硬盘是机械硬盘(I/O能力差),或者数据库写操作非常频繁,你可以把这个值设得大一些,比如0.9,这意味着系统会在4.5分钟内更平缓地完成写入,大大减轻了I/O的瞬间压力,但设得太接近1.0也不好,可能导致上个checkpoint刚结束下个又马上开始。
- 举个例子:如果
-
平衡
checkpoint_timeout和max_wal_size- 缩短
checkpoint_timeout(比如从5分钟调到1分钟):好处是崩溃恢复更快,因为存档点很密集,坏处是checkpoint变得更频繁,虽然每次写的量少了,但频繁的I/O峰值也可能影响性能。 - 增大
max_wal_size:允许系统积累更多的WAL日志,从而减少checkpoint频率,这适合写操作非常猛的系统,让系统有机会在后台更平滑地写入,但副作用是崩溃恢复时间会变长,因为需要回放的日志量变大了,你需要确保硬盘有足够的空间存放这些WAL日志。
- 缩短
-
硬件是基础 所有的调优都建立在硬件基础上,如果可能,使用SSD固态硬盘是解决checkpoint I/O瓶颈最有效的方法,SSD的随机读写能力远超机械硬盘,能极大地缓解集中写入带来的性能抖动。
PostgreSQL的checkpoint就是一个为了兼顾性能和可靠性而设计的“存档机制”,它定期把内存里的数据变动批量同步到硬盘,是崩溃恢复的基石,你用的时候,主要就是通过调整几个参数(特别是checkpoint_completion_target),来控制这个“存档”行为的激烈程度,让它既不会太频繁影响你“打游戏”(正常业务),又能保证“存档点”不至于太旧,导致“游戏重启”(崩溃恢复)时等太久。
(参考资料:PostgreSQL官方文档中关于“Write-Ahead Logging (WAL)”和“Resource Consumption”的章节,以及《PostgreSQL修炼之道:从小工到专家》等书籍中对checkpoint原理的通俗解释。)
本文由钊智敏于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/67851.html