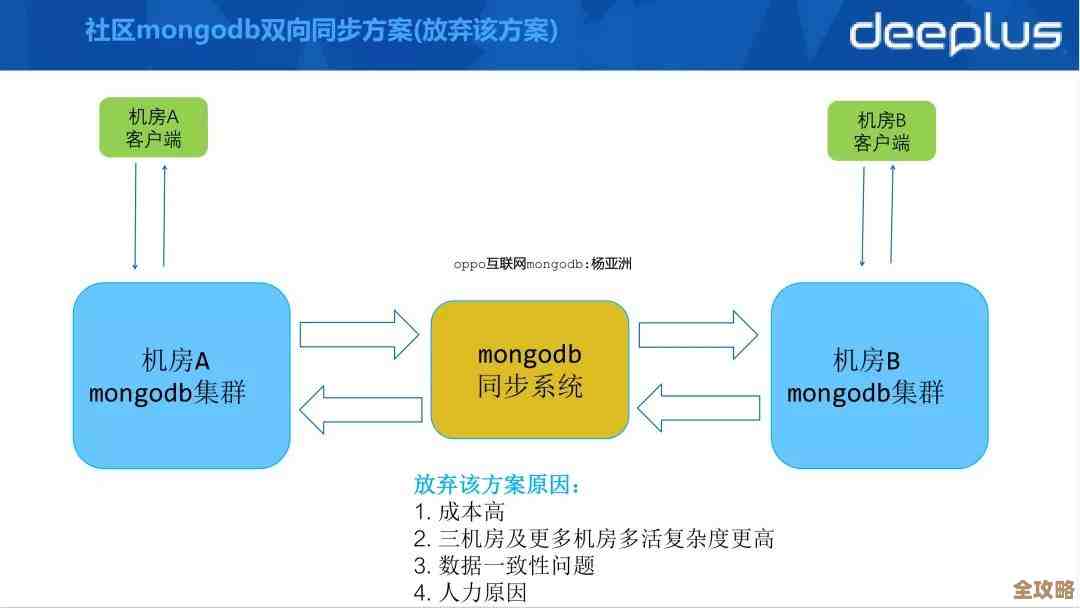
看着redis源码,感觉它里面的设计真是妙不可言,视频里慢慢讲解那些细节

我记得当时看的是黄健宏老师讲解Redis源码的视频,他讲的是Redis的字符串实现,叫SDS,就是Simple Dynamic String,一开始我以为字符串嘛,不就是C语言里那个char*吗,结尾加个\0,但Redis自己搞了一套,我当时还想这不是多此一举吗?结果一听讲解,才发现里面的设计真是妙不可言。
视频里说,C语言的字符串有个大问题,就是你想知道它多长,你得从头开始数,一直数到\0,这个操作的时间复杂度是O(n),如果字符串特别长,你又要频繁地获取它的长度,那就很浪费CPU,Redis是怎么做的呢?它在自己定义的SDS结构体里,直接存了一个len字段,用来记录字符串的当前长度,这样,无论字符串多长,我获取长度就是一个直接读这个len值的操作,是O(1)的,瞬间完成,这个设计思想就特别直接,用一点点的空间(就是多存了一个len整数),换来了巨大的性能提升,因为对于数据库来说,获取键值对的键名长度是非常非常频繁的操作,这个优化一下子就打到了痛点上。
这还没完,视频里接着讲,SDS结构里除了len,还存了一个free字段,这个free是干嘛的呢?它表示这个字符串后面预分配了多少空闲的空间,比如说,一个字符串"hello",长度len是5,但可能实际分配的内存空间是10个字节,那么free就是5,这个设计又是妙在哪儿呢?它是为了应对字符串增长的情况,如果我用C语言的strcat函数拼接字符串,如果目标空间不够,就得重新分配一块更大的内存,然后把原来的数据拷贝过去,这个操作很耗时,而Redis的SDS,在拼接之前,会先检查free空间够不够,如果够,就直接在后面追加,不用重新分配内存,如果不够,它也不是需要多少就分配多少,而是会多分配一些,比如采用类似加倍这样的策略,这样,下次再追加内容的时候,很大概率就不需要再次分配了,这个策略用空间换时间,减少了内存重分配的次数,对于追求高性能的数据库来说,简直是必杀技。
视频里还提到了一个我从来没想过的点,就是二进制安全,C语言的字符串因为用\0作为结束符,所以字符串中间就不能包含\0这个字符,但Redis是数据库,它要存储的可能不仅仅是文本,也可能是图片、序列化后的数据等二进制数据,这些数据里很可能就包含\0字节,如果用C语言的字符串函数来处理,一遇到\0就以为结束了,那数据就截断了,肯定不行,而SDS怎么解决的呢?它不依赖\0来判断结束,它靠的是len字段。len是多少,就读多少字节,管你中间有没有\0呢,所以SDS可以安全地存储任何二进制数据,这个设计就让Redis的适用场景大大拓宽了,不仅仅是个缓存,还能当简单的消息队列什么的。
听着视频里一步步分析这些细节,我真的有种豁然开朗的感觉,原来一个看似简单的字符串实现,背后竟然考虑了这么多:有对性能的极致追求(O(1)复杂度取长度),有对常见操作的优化(空间预分配减少内存分配),还有对数据类型的包容性(二进制安全),每一个设计点都不是凭空想象的,都是针对实际应用场景中的痛点来的,这种看着源码,听人把设计意图一层层剥开的感觉,比单纯看一本设计模式的书要深刻得多,它让你看到,优秀的软件就是这样一点点打磨出来的,每一个细节都透着巧思。

本文由雪和泽于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/68229.html