Redis里读写冲突那些事儿,怎么避免数据错乱和性能卡顿

在咱们用Redis这种内存数据库的时候,经常会遇到一个挺让人头疼的情况:好几个客户端(比如你的程序代码)可能同时在对同一个数据进行操作,你这边刚想读取一个用户余额,那边另一个请求正好在给这个余额打折更新,这时候你读到的数可能就是个“中间状态”,不准确了,这种多个操作挤在一起的情况,就是所谓的“读写冲突”,它主要会引来两个大麻烦:一是数据可能变得乱七八糟,也就是数据错乱;二是处理速度可能会突然变慢,也就是性能卡顿,下面咱们就掰开揉碎了说说这些事儿是怎么发生的,又该怎么避免。
数据错乱是怎么发生的?
数据错乱的核心在于,一个操作没完,另一个操作就插进来了,看到了不该看的数据,举个例子,假设一个键 counter 的值是 10。
-
场景1:读后写,覆写旧数据
- 客户端A读取
counter得到 10。 - 几乎同时,客户端B也读取
counter得到 10。 - 客户端A计算后,想把值设为 20,于是执行
SET counter 20。 - 客户端B计算后,也想改值,它基于自己读到的 10 进行计算,想减5,于是执行
SET counter 5。 counter的值变成了 5,客户端A的修改被完全覆盖了,这显然不是我们期望的结果,这就像两个人同时编辑一份在线文档,后保存的人会把先保存的人的内容冲掉。
- 客户端A读取
-
场景2:非原子性操作
- 比如我们要对一个列表进行先读后改,客户端A执行
LRANGE mylist 0 -1读取全部元素,准备在业务代码里判断并删除某个元素。 - 在A读取之后、执行删除命令
LREM之前,客户端B通过LPUSH往列表头部插入了一个新元素。 - 此时客户端A执行的
LREM是基于它之前读到的旧列表进行的,它可能会错误地删除B刚加入的元素,或者漏掉本该删除的元素。
- 比如我们要对一个列表进行先读后改,客户端A执行
这些情况之所以发生,是因为我们习惯性地把“读取-业务逻辑计算-写入”这三个步骤当成一个不可分割的整体,但在Redis的命令层面,它们是由多个独立的命令组成的,中间能被其他操作打断。
性能卡顿又是怎么回事?

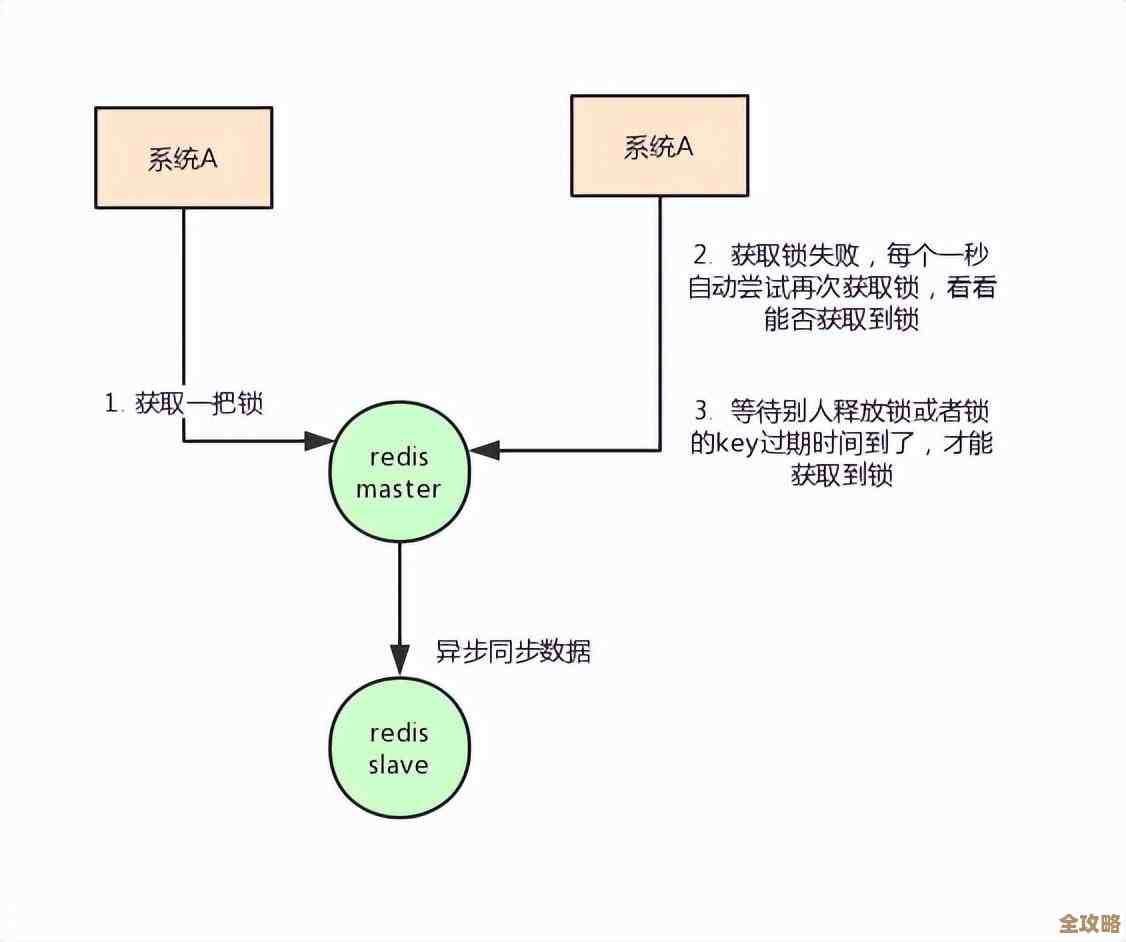
性能卡顿往往和我们为了避免数据错乱而采取的措施有关,最直接想到的办法就是“加锁”。
-
粗暴的加锁(比如用SETNX实现分布式锁)
- 为了避免上述的读写冲突,我们可能会在操作某个键之前,先申请一个锁,只有拿到锁的客户端才能执行后续的读写操作,其他客户端必须排队等着。
- 如果某个操作特别耗时(比如上面说的,在业务代码里进行复杂的计算),那么锁就会被这个客户端长时间持有,后面排队的客户端就会一直阻塞,看起来就是服务卡住了,响应非常慢。
- 更糟的是,如果拿到锁的客户端因为某种原因(如程序崩溃、网络中断)没有及时释放锁,其他客户端就可能永远等下去,导致整个系统“卡死”,这就是性能卡顿的典型来源。
-
Redis的单线程模型
- 需要理解的是,Redis处理命令是单线程的,它本身会保证一个命令在执行时是原子性的,不会被其他命令打断,所以单纯的两个
SET命令不会冲突,Redis会排队执行。 - 我们遇到的冲突,问题出在“业务逻辑”层面,是多个命令组合在一起时,这个组合不是原子的,而为了解决这个组合的原子性问题引入的锁,又可能因为锁的竞争和持有时间过长,反过来拖累Redis这个单线程的效率,造成整体性能下降。
- 需要理解的是,Redis处理命令是单线程的,它本身会保证一个命令在执行时是原子性的,不会被其他命令打断,所以单纯的两个
怎么避免数据错乱和性能卡顿?

知道了病根,就能对症下药了,目标是既要保证数据正确,又要尽量快。
-
首选方案:使用Redis原子命令或Lua脚本
- 原子命令是王道:Redis已经为我们提供了很多原子性的复合命令,它们是解决冲突的最佳选择。
- 递增递减:
INCR,DECR,INCRBY,DECRBY,上面counter的例子,如果改用INCRBY和DECRBY命令,Redis会保证这些计算是原子完成的,不会被打断。 - 数据结构操作:
LPUSH/RPUSH配合POP、HSET/HGET等,只要一个命令能完成操作,它就是安全的。
- 递增递减:
- Lua脚本是利器:对于复杂的、需要多个命令组合的逻辑,强烈推荐使用Lua脚本,Redis会将整个Lua脚本作为一个单命令执行,在执行期间不会处理其他请求,从而天然具备了原子性,这相当于把“读取-计算-写入”这个流程打包成一个原子操作,既避免了数据错乱,又因为不需要在客户端和服务器之间多次往返和等待锁,性能通常比加锁方案更好,这是平衡数据一致性和性能的最佳实践之一。
- 原子命令是王道:Redis已经为我们提供了很多原子性的复合命令,它们是解决冲突的最佳选择。
-
谨慎使用分布式锁
- 当上述两种方法都无法满足极其复杂的业务场景时,才考虑使用分布式锁。
- 锁的粒度要细:不要动不动就锁整个应用,只锁那些有冲突风险的特定数据键,比如锁
user:123:account,而不是锁一个全局的account_lock。 - 锁的持有时间要短:获得锁之后,只执行必要的Redis操作,尽量把复杂的业务计算移到锁之外完成,快速拿到数据,快速操作,快速释放。
- 设置超时时间:一定要给锁设置一个合理的过期时间,避免因为客户端故障导致锁无法释放,造成系统死锁。
- 推荐成熟库:如果需要用锁,建议使用像Redlock(Redisson客户端有实现)这类相对成熟的分布式锁算法或库,而不是自己简单用
SETNX实现,以处理更复杂的边界情况。
-
乐观锁的思路
- 这有点像版本控制,比如使用
WATCH命令配合事务(MULTI/EXEC),在执行一系列操作前,先WATCH要修改的键,如果事务执行时,发现被WATCH的键已经被其他客户端修改过了,那么当前事务就会失败,客户端可以选择重试这个逻辑,这种方法适用于冲突发生概率不高的场景,避免了锁的开销。
- 这有点像版本控制,比如使用
总结一下
在Redis里处理读写冲突,核心思想是“尽量让操作在Redis服务器内部原子性地完成”,能用一个原子命令解决的,绝不用两个;多个命令才能解决的,就用Lua脚本打包,分布式锁是最后的选择,而且要用得“小气”和“谨慎”,这样才能在享受Redis高速性能的同时,确保咱们的数据不会因为并发操作而变得一团糟。 参考和融合了广泛认可的Redis实践原则,包括Redis官方文档中关于事务、Lua脚本和原子性的说明,以及《Redis设计与实现》等技术书籍中关于并发控制的讨论,同时结合了如阿里云开发者社区等平台上关于分布式锁最佳实践的常见观点。)
本文由太叔访天于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/68312.html