Redis磁盘空间不够用,导致数据存储和性能都出问题了怎么办?

当Redis的磁盘空间不够用时,确实会引发一系列连锁问题,比如无法写入新数据、内存中的数据无法持久化到磁盘导致数据丢失风险、以及因为频繁清理过期键或触发逐出策略而使得服务器性能急剧下降,面对这种情况,我们不能慌张,需要一步步来排查和解决,根据Redis官方文档和常见的运维实践经验,可以从以下几个方面着手。

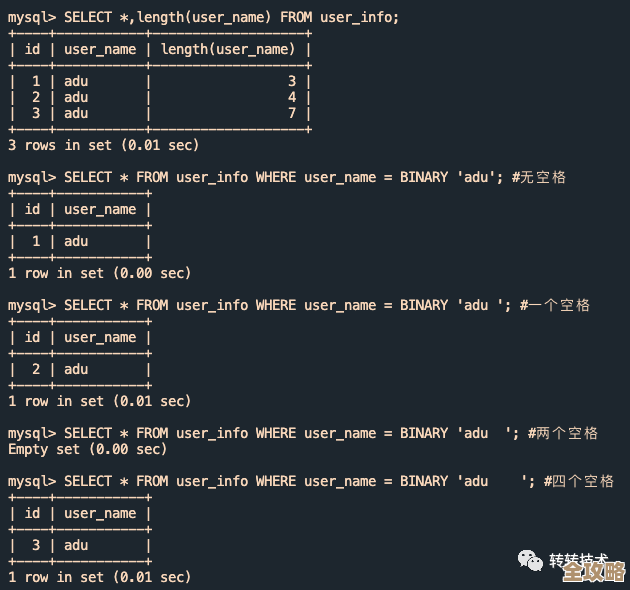
最直接的办法就是清理掉一些不必要的数据,给Redis“减负”,你需要登录到Redis服务器,使用INFO命令来查看详细的内存使用情况,特别关注used_memory_human和used_memory_peak_human这两个指标,它们能告诉你当前使用了多少内存以及历史峰值是多少,你可以使用KEYS命令(注意,在生产环境使用KEYS *可能会阻塞服务,建议使用SCAN命令迭代查询)来查看所有的键,找出哪些键占用了大量空间,一些存储了大体积数据(比如巨大的集合、列表或字符串)的键或者已经过期但还未被清理的键是主要的“空间杀手”,找到这些键之后,可以使用DEL命令手动删除它们,确保你设置了合理的过期时间(TTL),这样Redis可以自动淘汰过期数据,你可以用TTL key命令查看某个键的剩余生存时间,对于没有设置过期时间但又可以丢弃的键,可以用EXPIRE命令为其设置一个过期时间。

如果清理数据后空间仍然紧张,或者有些数据不能删除,那么就需要考虑扩容了,这是最根本的解决方案,根据你的部署方式,扩容手段不同,如果你是物理机或虚拟机部署,可以给服务器增加一块更大的硬盘,然后将Redis的数据目录迁移到新硬盘上,这个过程需要停机或者采用在线迁移工具,确保数据一致性,如果你是云服务商提供的Redis服务(例如阿里云ApsaraDB for Redis、亚马逊ElastiCache等),那么通常可以在管理控制台上直接进行扩容操作,选择更大的内存规格,这个过程服务商通常会处理数据迁移,对应用的影响较小,扩容虽然需要成本,但它能一劳永逸地解决空间不足的问题。

除了上述两种主要方法,我们还需要检查一下Redis的持久化配置,因为这也与磁盘空间息息相关,Redis主要有两种持久化方式:RDB和AOF,RDB是生成某个时间点的数据快照,AOF是记录每一次写操作命令,如果AOF文件开启且重写(rewrite)不频繁,AOF文件可能会变得非常大,占用大量磁盘空间,你可以通过INFO PERSISTENCE命令查看AOF文件的大小和相关状态,如果AOF文件过大,可以手动执行BGREWRITEAOF命令来触发AOF重写,重写会生成一个更精简的AOF文件,释放空间,检查你的redis.conf配置文件,确保auto-aof-rewrite-percentage和auto-aof-rewrite-min-size设置合理,让Redis能在适当的时候自动重写AOF,对于RDB,也要确保save配置的触发条件符合你的业务场景,避免过于频繁的快照生成对磁盘造成压力。
一个经常被忽略的问题是磁盘空间本身可能被其他文件占用,你需要使用操作系统的命令(比如Linux下的df -h)确认是不是Redis数据目录所在的磁盘分区真的满了,可能是Redis的日志文件、其他应用程序的文件或者系统临时文件占满了磁盘,如果是这种情况,就需要清理这些无关文件来腾出空间。
从长远来看,建立监控和预警机制至关重要,你不能等到磁盘空间完全用尽、服务出问题了才后知后觉,应该使用监控系统(如Prometheus、Zabbix或云监控服务)对Redis实例的used_memory、used_memory_peak以及磁盘剩余空间等关键指标进行持续监控,并设置告警阈值,当磁盘使用率达到80%时就开始告警,这样你就有充足的时间去采取上述的清理或扩容措施,避免问题发生。
当Redis磁盘空间告急时, immediate action是清理数据和检查持久化文件,根本解决方案是扩容,而长期的保障则是建立完善的监控体系,根据《Redis实战》一书中的建议,定期审视数据结构和淘汰策略,防患于未然,是保持Redis健康运行的关键。
本文由瞿欣合于2025-12-26发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/68653.html