用Redis搭无限级团队结构,灵活又高效,怎么设计才靠谱?

用Redis搭建一个无限级团队结构,关键在于如何利用Redis灵活的数据结构来高效地表示和查询树状的层级关系,同时要兼顾到性能、扩展性和操作的便捷性,一个靠谱的设计通常不会只依赖一种方法,而是根据不同的查询需求,组合使用多种策略,下面是一个比较全面和实用的设计方案。
核心思路:用路径枚举法存储结构,用集合维护关系
这个方法的核心是把每个团队的完整路径存储起来,并通过Redis的集合等数据结构来维护成员关系和快速查询。
第一步:设计数据模型
假设我们的团队结构是这样的:公司 -> 事业部A -> 部门A1 -> 小组A1a,每个节点都有一个唯一的ID(如dept:1)和一个名称。
-
存储节点信息(使用Hash): 每个团队节点用一个Redis Hash来存储其详细信息。
- Key:
dept:[节点ID],dept:1、dept:2。 - Value(Hash字段):
id: 节点IDname: 团队名称parent_id: 父节点ID(根节点的父节点ID可以为0或空)path: 这是关键字段,存储从根节点到当前节点的ID路径,用分隔符(如冒号或竖线)连接,小组A1a(ID为4)的路径可能是1:2:3:4(对应公司:事业部A:部门A1:小组A1a)。
通过这个
path字段,我们实际上就把整个层级关系“拍平”存储了。 - Key:
第二步:实现关键操作
有了数据模型,我们来设计如何实现增删改查。
-
查询子孙团队(找下级): 这是非常常见的需求,找出事业部A下的所有部门和小组”。
- 方法:利用Redis的
KEYS或SCAN命令(生产环境推荐使用SCAN避免阻塞)配合通配符,因为每个节点的path都包含了其所有祖先的ID。 - 操作:要查找节点
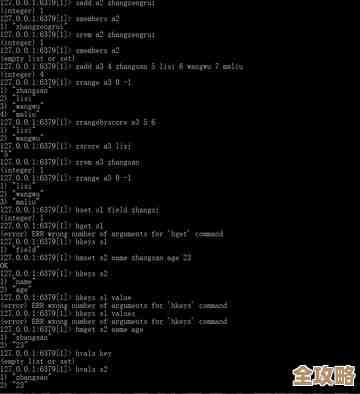
dept:2的所有子孙,可以执行SCAN MATCH dept:* FILTER "path MATCHES '.*:2:.*'",但更高效的做法是为每个节点维护一个子孙集合。 - 优化方案:额外使用一个Set(集合)。
- Key:
children:[节点ID] - Value:包含所有直接和间接子孙节点ID的集合。
- 当添加一个新节点时,除了创建它的Hash和设置
path,还要把它自己的ID添加到其所有祖先的children集合中,添加小组dept:4时,需要将4添加到children:1、children:2、children:3这三个集合里。 - 查询:要查节点2的所有子孙,直接执行
SMEMBERS children:2即可,时间复杂度是O(1),极其高效。
- Key:
- 方法:利用Redis的
-
查询祖先团队(找上级): 查看某个员工所在小组的上级部门直到公司层级”。
- 方法:这个非常简单,直接读取该节点Hash中的
path字段即可,路径1:2:3:4清晰地展示了所有祖先节点ID,然后再用MGET或管道(pipeline)批量获取这些ID对应的团队名称。
- 方法:这个非常简单,直接读取该节点Hash中的
-
添加新团队:
- 生成新节点的唯一ID。
- 用
HSET创建新的Hash(dept:[新ID]),并设置name、parent_id。 - 根据父节点的
path计算出新节点的path(父节点path + 新ID),并设置。 - 关键步骤:将新节点ID添加到其所有祖先节点的
children集合中(使用SADD命令)。
-
删除团队:
- 删除操作要谨慎,通常采用逻辑删除(标记为失效),如果物理删除,需要维护数据一致性:
- 删除节点Hash。
- 从它所有祖先节点的
children集合中移除本节点ID。 - 递归处理:还需要处理它的子孙节点,可以选择将其子孙节点一并删除,或者将这些子孙节点挂到被删除节点的父节点下(需要更新这些子孙节点的
path和所有相关祖先的children集合),这一步比较复杂,建议使用Lua脚本保证原子性。
- 删除操作要谨慎,通常采用逻辑删除(标记为失效),如果物理删除,需要维护数据一致性:
-
查询直接子团队:
- “路径枚举法”本身擅长查所有子孙,但不直接区分直接子节点和间接子节点。
- 方法一:在节点Hash中增加一个
parent_id字段,查询时找出所有parent_id等于当前节点ID的节点,这需要辅助索引。 - 方法二:额外维护一个
direct_children:[节点ID]的集合,只存储直接子节点ID,这样查询直接子节点会非常快。
第三步:关联团队成员
团队结构建好了,如何把用户挂上去?
-
使用Set(集合):
- 为每个团队节点创建一个Set,Key为
members:[团队ID]。 - Value是这个团队下的所有用户ID。
- 优点:可以轻松实现“查询团队下所有成员”、“判断用户是否在某个团队”。
- 注意:一个用户可能属于多个团队(矩阵式管理),所以这种设计是支持的。
- 为每个团队节点创建一个Set,Key为
-
记录用户所属团队:
- 也为每个用户维护一个Set,Key为
user_teams:[用户ID]。 - Value是该用户所属的所有团队ID的路径(
path),为什么存路径而不只是团队ID?因为有了路径,可以很方便地知道用户所在的整个汇报线。 - 优点:可以快速查询“某个用户属于哪些团队”。
- 也为每个用户维护一个Set,Key为
总结与优势
这种组合设计(路径枚举Hash + 关系集合)的优势非常明显:
- 查询极快:无论是找上级、下级还是成员,大部分操作都是O(1)或O(N)的集合操作,速度远超关系型数据库的递归查询。
- 无限层级:理论上层级深度不受限制,
path字段可以很长。 - 灵活扩展:很容易支持移动团队(更新
path和相关的集合)、统计团队人数(SCARD members:[团队ID])等复杂操作。 - 结构清晰:数据模型直观,易于理解和维护。
需要注意的坑:
- 数据一致性:增删改操作需要同时修改多个Key(Hash和多个Set),必须使用Redis事务或Lua脚本来保证原子性,避免出现数据不一致。
- 内存占用:
children集合可能会很大,尤其是根节点,它包含了全量节点ID,需要评估内存成本,对于超大规模数据(例如百万级节点),可能需要引入分片策略。 - 备份与持久化:Redis的数据主要在内存中,需要有完善的RDB和AOF持久化策略,防止数据丢失。
用Redis搭建无限级团队结构,通过巧妙地组合使用Hash和Set,并采用路径枚举的思想,完全可以实现一个既灵活又高效的系统,非常适合对读取性能要求高、团队结构频繁变动的应用场景。

本文由钊智敏于2025-12-27发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/69334.html