Redis在海量数据下还能撑住吗,性能到底有多极限用多少才合适

关于Redis能不能撑住海量数据,性能极限在哪里,以及用多少才合适,这是一个非常实际的问题,我们不能简单地说“能”或“不能”,而是要看具体怎么用,下面根据一些公开的技术分享和实践经验来聊聊。
Redis在海量数据下确实能撑住,但这背后有条件。

Redis最大的特点是所有数据都在内存里,所以它的读写速度极快,但这也带来了最直接的限制:内存大小,一台服务器的内存是有限的,比如常见的服务器可能有几十GB到几百GB的内存,如果你的数据量达到了TB级别,那么单机的Redis肯定是撑不住的。
那怎么办呢?答案就是分布式集群,Redis官方提供了Redis Cluster的解决方案,就是把海量数据分散到多台Redis服务器上,每台服务器只存一部分数据,比如你有3TB的数据,你可以搭建一个由10台机器组成的集群,每台机器有300多GB内存,这样加起来就能装下了,像一些大型互联网公司,比如Twitter、新浪微博,他们的Redis集群可能由成百上千个节点组成,管理着PB级别的数据(来源:Redis官方文档及各大公司技术博客分享),从“容量”的角度看,通过水平扩展,Redis理论上可以支撑非常大的数据量。

性能的极限在哪里?这比容量更复杂。
光能存下还不够,关键是要能快速读写,Redis的性能极限主要受以下几个因素影响:
- 网络带宽和延迟:这是最容易被忽略但往往是第一个瓶颈,当你的应用服务器和Redis服务器之间通过网络通信时,如果网络带宽不够,或者延迟很高(比如跨机房调用),那么Redis本身再快也没用,数据包在路上就堵住了,确保Redis集群和应用服务器在同一个高速网络内至关重要。
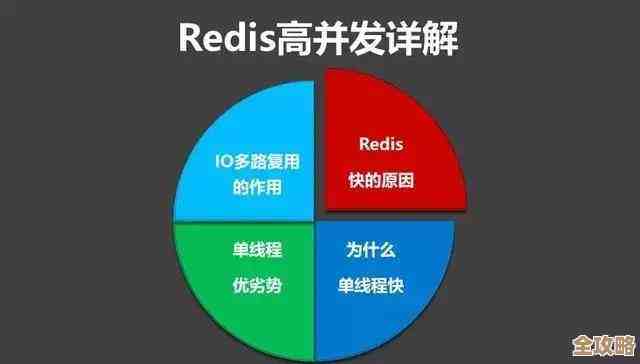
- CPU:Redis是单线程处理命令的(指核心的网络IO和键值读写),这意味着它在一个时间点只能处理一个命令,虽然这个单线程非常高效,但如果你的命令特别复杂(比如对一个大集合进行交集运算),或者每秒的请求量(QPS)极高,这个单线程也可能成为瓶颈,根据Redis官方的基准测试,在普通的硬件上,一个Redis实例每秒处理几十万次简单的GET/SET请求是完全可以的(来源:Redis官方基准测试文档),但如果是复杂操作,性能会下降。
- 持久化操作:为了保证数据不丢失,Redis需要把内存中的数据定期写入硬盘(RDB快照或AOF日志),这个写硬盘的过程,尤其是做RDB快照时,可能会占用大量资源,导致暂时性的性能抖动,在数据量巨大的情况下,这个抖动可能会更明显。
- 数据结构和使用方式:这是影响性能的关键,如果你错误地使用了一个O(N)时间复杂度的命令去操作一个包含百万元素的Key(比如
KEYS *命令),那么这一次请求就可能让Redis“卡住”好几秒钟,导致其他所有请求超时,正确的做法是使用高效的数据结构和命令,比如用SCAN代替KEYS,用Hash存储对象而不是多个String。
用多少才合适?这是一个权衡的艺术。
没有一个固定的数字说“用到50%”或“QPS到10万”就合适,你需要根据自己的业务场景来找到平衡点。
- 内存使用率:一般建议不要跑满,留出20%-30%的余量,一方面是为了应对临时的数据增长,另一方面是给Redis的持久化和主从复制等操作留出缓冲空间,如果内存用满,Redis可能会根据策略淘汰一些数据,或者直接拒绝写入,这会影响业务。
- CPU使用率:对于单线程的Redis实例,CPU使用率不宜持续过高(比如长期超过70%),如果发现CPU成为瓶颈,可以考虑使用分片(Sharding)将负载分散到多个Redis实例上,或者检查是否有慢查询拖累了性能。
- 响应时间:这是最直观的指标,你的业务能容忍的Redis响应时间是多少?1毫秒还是10毫秒?通过监控工具观察Redis的响应时间,如果发现P99(99%的请求的响应时间)或P999(99.9%的请求)指标出现飙升,就意味着系统可能已经接近极限,需要优化或扩容了。
总结一下:Redis就像一辆超级跑车,它在内存的“高速公路”上能跑出惊人的速度,面对海量数据,你可以通过组建集群“车队”来运输,但你要时刻关注“路况”(网络)、“引擎”负载(CPU)、和“驾驶习惯”(命令使用),用多少合适,取决于你的“目的地”要求多快到达(响应时间),以及你愿意为这条“高速公路”投入多少资源(服务器成本),定期监控性能指标,做好容量规划,避免滥用复杂命令,是让Redis在海量数据场景下稳定发挥的关键。

本文由瞿欣合于2025-12-27发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/69656.html