Redis集群里单数节点挂了咋办,节点掉线处理思路和坑总结

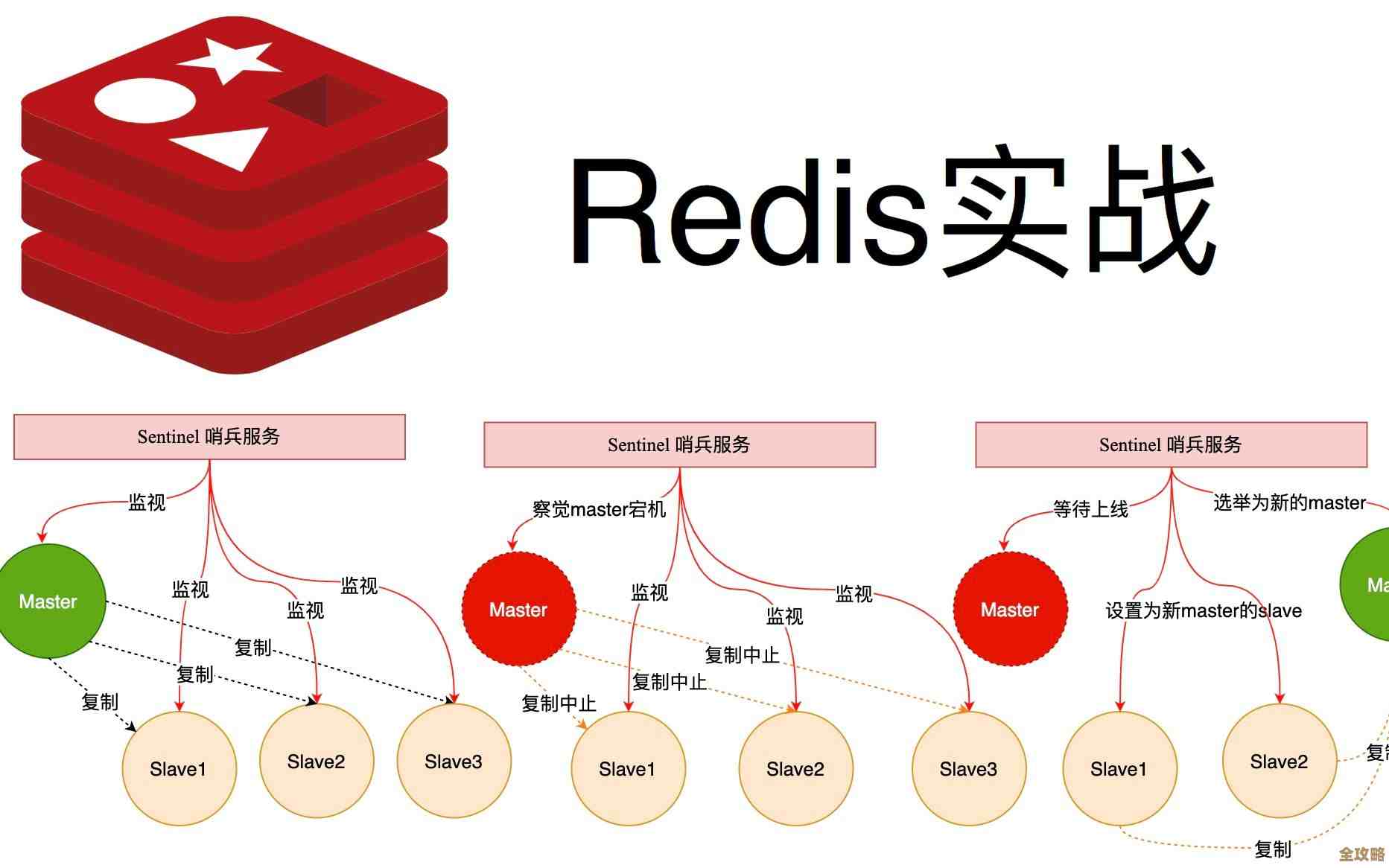
关于Redis集群里如果单个节点挂掉该怎么办,这个问题其实在Redis官方设计集群模式的时候就已经考虑到了,核心的思路就是“主从切换”,说白了就是给每个主节点都配一个或多个备份节点(从节点),当主节点挂掉的时候,从节点会顶上来,接替主节点的工作,以此来保证整个集群还能继续提供服务,这个顶替的过程,在Redis集群里是自动完成的,叫做“故障转移”。
(来源:Redis官方文档关于复制和故障转移的章节)
当你的集群中某一个主节点(比如我们叫它A节点)因为机器宕机、网络中断或者其他原因突然挂掉了,这时候会发生以下几件事情:
- 集群状态变化:集群会检测到A节点失联了,其他还能正常工作的主节点会通过一种叫做“Gossip”的协议互相通信,最终达成一个共识:“A节点可能挂了”,集群的状态会变为“FAIL”,意思是出现了故障。
- 从节点选举:A节点挂掉后,它下面的从节点(比如叫A1、A2)会发现自己的老大联系不上了,这些从节点会开始竞争上岗,它们会向集群中所有其他主节点申请,要求成为新的主节点。
- 投票与晋升:其他所有存活的主节点会参与投票,只要有一个从节点获得了大多数主节点的同意票(超过一半),它就会成功晋升为新的主节点,举个例子,如果你的集群有3个主节点,大多数”就是2票,如果有5个主节点,大多数就是3票。
- 接管数据与服务:成功当选的从节点(比如A1)会立刻执行一系列操作:它会将自己身份切换为主节点,并接管原来A节点负责处理的所有哈希槽(数据分区),它会向整个集群广播:“我现在是这些槽的新主人了!”
- 集群恢复:一旦新的主节点上线并接管了槽,集群的状态就会从“FAIL”恢复为“OK”,整个集群又可以正常接受读写请求了。
(来源:Redis官方文档对故障转移过程的描述)
这个过程听起来很自动化、很美好,但实际操作和运维中会遇到不少“坑”,需要特别注意:
第一个大坑:节点数量配置不当,导致无法选举。 这是最经典也是最危险的坑,上面说了,选举新主需要“大多数”主节点同意,如果你的集群只有两个主节点,挂掉一个,剩下那个主节点只有一票,它达不到“大多数”(需要2票),所以它无法投票让任何一个从节点上位,结果就是,集群将一直处于故障状态,无法自动恢复。搭建Redis集群时,主节点的数量必须是奇数(比如3、5、7),这样才能保证在部分节点挂掉时,剩下的节点还能形成“大多数”进行投票。 同样,如果是一个主节点配一个从节点,那么至少需要3个主节点和3个从节点(共6个节点)的配置才是安全的。
第二个坑:网络分区问题,俗称“脑裂”。 假设你的集群网络突然出现故障,把集群分成了两半,一个3主3从的集群,被网络分割成一边是2个主节点,另一边是1个主节点+3个从节点,网络较差的一边(只有1个主节点)会因为无法联系到大多数主节点,而认为集群出故障了,它这边的从节点可能会尝试选举出一个新的主节点,这样一来,集群里就可能同时存在两个“主节点”都认为自己负责同一批数据,导致数据不一致,等网络恢复后,两个“主节点”相遇,旧的主节点会被强制降级为从节点,并清空自己的数据,去同步新的主节点,这期间可能会造成数据丢失。
第三个坑:故障转移期间的数据丢失风险。 虽然故障转移很快(通常几秒钟),但它不是瞬间完成的,在旧主节点挂掉的那一刻,到新主节点正式上任并提供服务的这个极短的时间窗口内,如果有数据正在写入旧主节点,这部分数据可能还没来得及同步给从节点,就会永久丢失,这是因为Redis主从复制默认是异步的,主节点为了性能,不会等到从节点都确认收到后才告诉客户端写入成功。
第四个坑:客户端感知延迟与重试机制。 在故障转移发生时,客户端可能会遇到短暂的报错,CLUSTERDOWN”或者连接失败,一个设计良好的客户端驱动应该能自动处理这种情况:它会尝试刷新集群的拓扑结构(节点映射关系),发现新的主节点是谁,然后自动把请求重定向到新主节点上,但如果你的客户端驱动比较老或者配置不当,它可能无法自动处理,需要重启应用,或者会长时间卡在旧的路由信息上,导致持续报错。
第五个坑:手动干预的陷阱。 有时候节点可能只是临时网络抖动,一会儿就自己恢复了,但如果运维人员过于心急,在集群自动故障转移还没完成时,就手动去重启挂掉的节点,可能会把事情搞得更复杂,旧主节点重启后,它会发现自己负责的槽已经被别的节点接管了,它就会变成一个新主节点的从节点,这个过程本身没问题,但如果操作顺序不对,或者节点数据差异很大,可能会引发全量同步,占用大量网络带宽,影响集群性能。
总结一下处理思路和关键点:
- 预防为主:搭建集群时就要规划好,使用奇数个主节点,并确保每个主节点都有至少一个从节点。
- 监控报警:必须要有完善的监控系统,实时监控每个节点的状态和集群的健康度,一旦发现节点下线或集群状态异常,能立即收到报警。
- 理解过程:了解故障转移的原理和潜在风险,这样在真正出问题时才不会慌乱。
- 谨慎操作:在故障发生时,除非非常确定,否则先观察一下集群的自动恢复情况,避免不必要的、可能适得其反的手动干预。
- 测试!测试!测试! 在生产环境部署前,一定要在测试环境模拟各种故障场景(如kill掉节点进程、断网等),验证集群的故障恢复能力和客户端的兼容性,这是发现和规避上述所有“坑”的最有效方法。
(来源:综合了Redis运维常见的实践经验和官方文档中的注意事项)

本文由颜泰平于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/69771.html