Angular技术怎么帮你搞定缓存数据库,提升性能和开发效率

关于Angular技术如何帮助搞定缓存数据库,提升性能和开发效率,我们可以从Angular框架本身提供的机制以及其倡导的开发模式来理解,Angular并不是一个直接操作数据库的框架,它主要处理的是前端用户界面,它提供了一套非常强大的工具和模式,使得在前端层面管理“缓存”变得异常高效和简单,这间接但极大地优化了与后端数据库的交互,从而提升了整体应用的性能和开发效率。
核心武器:强大的依赖注入与服务(来源:Angular官方核心概念 - 服务与依赖注入)
Angular最核心的武器之一就是其依赖注入系统和服务,服务在Angular中是一个单例对象,也就是说,在整个应用的生命周期内,一个服务通常只有一个实例,这个特性天生就是为缓存准备的,我们可以创建一个专门的数据服务,比如叫做UserDataService,来负责所有与用户数据相关的获取和存储。
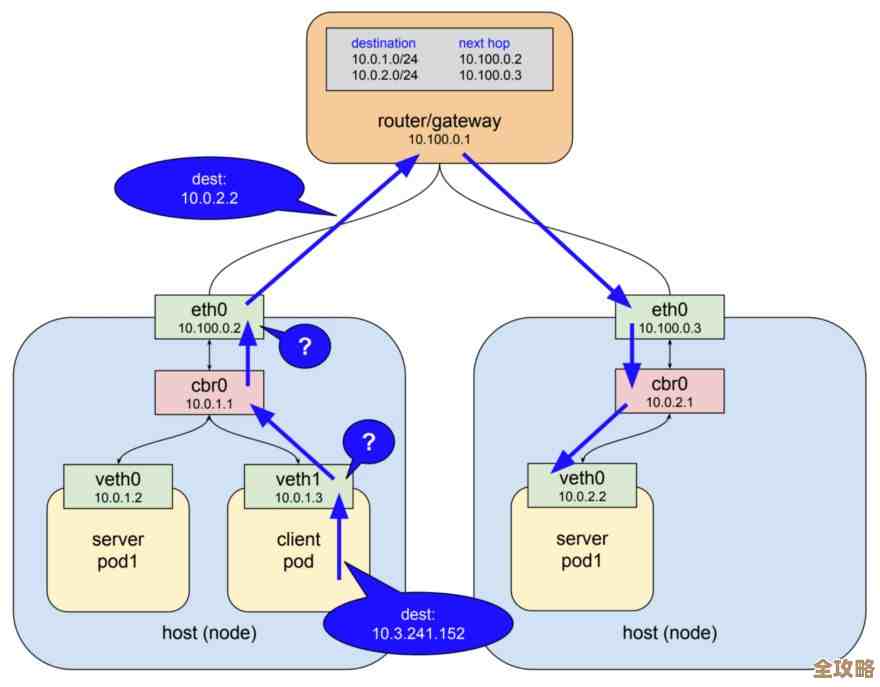
当组件A需要用户数据时,它不会直接去后台数据库请求,而是调用这个UserDataService的某个方法,服务会先检查自己的内部(比如一个JavaScript对象或者Map)有没有缓存这份数据,如果有,它立刻把缓存的数据返回给组件A,完全跳过网络请求,如果没有,它才去请求后端API,从真实的数据库中获取数据,然后在返回给组件的同时,自己也存一份,当组件B也需要同样的用户数据时,服务发现缓存里已经有了,直接返回,瞬间完成。
这种方式带来的性能提升是立竿见影的,想象一下,一个电商网站的商品列表页,用户来回跳转,如果没有缓存,每次点击进入列表都要等待数据库查询和网络传输,体验会很差,而利用Angular服务做了缓存之后,只有第一次加载需要等待,后续的浏览如丝般顺滑。
效率利器:RxJS的可观察对象与异步数据流(来源:Angular官方推荐的RxJS库)
Angular深度集成了RxJS库,用于处理异步操作,RxJS的可观察对象是管理缓存数据流的完美工具。

它可以避免重复的请求,假设两个组件几乎同时请求同一份数据,如果没有管理机制,可能会向后台发送两个一模一样的请求,浪费资源,利用RxJS的shareReplay等操作符,我们可以让第一个请求发出后,其响应结果被“共享”给后续的所有订阅者,也就是说,第二个组件只是订阅了已经存在的数据流,直接拿到缓存结果,而不会触发第二次网络请求。
它提供了强大的数据状态管理能力,服务中缓存的数据可以作为一个可观察对象暴露给整个应用,任何组件都可以订阅这个数据流,当数据需要更新时(比如用户修改了个人信息),我们只需要在服务中更新缓存的数据,然后通过可观察对象“推送”新的数据值,所有订阅了这个数据流的组件都会自动收到最新的数据,并立即更新视图,开发者不需要手动去每个组件里查找并更新数据,这种“响应式”的模式极大地减少了出错的概率,提升了开发效率。
实战技巧:HTTP拦截器实现智能缓存(来源:Angular官方指南 - HTTP拦截器)
对于更复杂的缓存策略,Angular的HTTP拦截器提供了集中式的解决方案,拦截器可以在HTTP请求发出前和收到响应后,进行统一的处理。

我们可以编写一个“缓存拦截器”,这个拦截器会检查即将发出的HTTP请求:这个请求的URL是不是GET请求?它的数据是不是不太经常变化的(比如配置信息、城市列表)?如果是,拦截器会先检查本地缓存(可以存在服务里,甚至存在浏览器的localStorage里)有没有这个URL对应的响应数据,如果有,拦截器会直接“拦截”这个请求,不再发往服务器,而是伪造一个和服务器返回格式一样的成功响应,数据来自缓存,直接返回给调用方,这个过程对调用数据的组件是完全透明的,组件根本不知道数据是来自缓存还是网络,但它享受到了极速加载的好处。
拦截器还可以设置缓存的过期策略,可以为缓存数据设置一个时间戳,当再次遇到相同请求时,判断缓存是否过期,如果过期了,就正常发送请求,用新数据更新缓存,这实现了智能化的缓存管理。
结构化保障:模块化与组件化(来源:Angular官方核心概念 - 模块与组件)
Angular强制性的模块化和组件化结构,为缓存的设计提供了良好的基础,因为数据访问的逻辑被集中封装在服务中,而不是散落在各个组件里,这使得维护和优化缓存策略变得非常容易,开发者只需要修改一个服务文件,就能全局改变应用的数据获取行为,这种关注点分离的设计,让开发者能更专注于缓存逻辑本身,而不是疲于奔命地在成百上千个组件中寻找和修改数据调用代码,这本身就是对开发效率的巨大提升。
Angular通过其服务的单例特性提供了天然的缓存容器,通过RxJS的可观察对象提供了高效、响应式的数据流管理方式,通过HTTP拦截器提供了集中、智能的缓存策略实施点,再辅以模块化的工程结构确保代码的可维护性,这一套组合拳下来,使得开发者能够用一种结构清晰、高效且易于维护的方式,在前端层面构建起一个强大的“缓存层”,这个缓存层有效地减少了不必要的数据库查询请求,降低了服务器压力,大幅提升了前端应用的加载速度和用户体验,同时也让开发者从繁琐的数据状态同步工作中解放出来,专注于业务逻辑的实现。
本文由芮以莲于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/69928.html