C语言怎么跟SQL Server搭配用,整合起来那些事儿和坑点总结

行,那咱们就直接开整,说清楚用C语言去捣鼓SQL Server的那些事儿和遇到的坑,这些内容主要来自一些老程序员的经验分享、MSDN的官方文档、还有像《C语言接口与数据库编程》这类老书里的章节,以及不少人在论坛里的真实吐槽。
最基本的问题是怎么连上SQL Server,现在最主流、微软自己也推的方式就是用ODBC,你可以把ODBC想象成一个翻译官,你的C语言程序说“我要查数据”,ODBC负责把这句话翻译成SQL Server能听懂的话,再把结果传回来,这事儿干起来分几步:你得在Windows电脑上配好一个ODBC数据源,就是告诉系统SQL Server的地址、账号密码这些,然后在C程序里,用SQLAllocHandle这类函数来申请环境、建立连接,这个过程特别啰嗦,代码写起来很长,一步错了后面全完蛋,所以一开始最好对着MSDN官方的示例代码抄,不然光记那些函数顺序就够头疼的。
连上之后,更麻烦的是发送SQL语句和取结果,比如你想执行一条SELECT * FROM users,就得用SQLExecDirect,取数据的时候更折腾,你得先知道查询结果有多少列、每列是什么类型、长度多少,然后用SQLBindCol函数把C语言里的变量(比如一个char name[50])跟查询结果的某一列“绑”在一起,最后一行一行地用SQLFetch去读,这个过程非常机械化,而且如果数据库里某个字段的类型你猜错了,比如数据库里是nvarchar,你C语言里却用char数组去接,很容易读出来是乱码或者直接截断,这是第一个常见的坑:数据类型映射必须小心,特别是字符串和二进制数据。
说到字符串,编码问题绝对是个大坑,SQL Server默认用UTF-16存储Unicode字符串(就是nvarchar类型),而老一点的C程序通常用char数组处理ANSI编码(比如GB2312),如果你不做转换,直接从nvarchar字段读到char数组里,大概率是一堆问号或者乱码,解决办法要么是在SQL语句里用CAST转换类型,要么是在C程序里用WideCharToMultiByte这类Windows API进行编码转换,但这就增加了代码的复杂性,论坛里很多人抱怨过,中文字符显示问号,十有八九是这里没处理好。
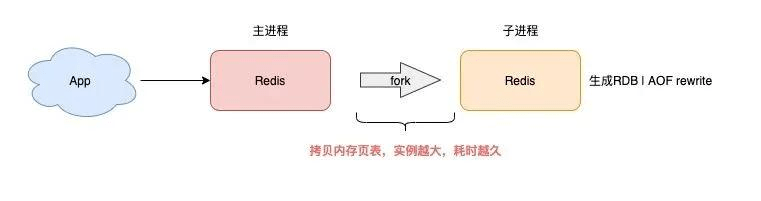
内存管理也是让人提心吊胆的地方,ODBC要求你在用完任何资源后,都必须手动释放,比如连接句柄、语句句柄,如果你只SQLAllocHandle而不SQLFreeHandle,内存泄漏就发生了,在长时间运行的服务程序里,这种泄漏积少成多,能把服务器拖垮,所以必须像写八股文一样,在分配资源的代码后面,紧跟着写好释放的代码,最好用goto语句统一跳到错误处理环节进行清理,不然哪个分支漏了就很麻烦。
错误处理的方式也很别扭,ODBC的错误信息是分层的,一个函数调用失败后,你得循环调用SQLGetDiagRec才能把完整的错误消息读出来,但很多新手图省事,只读一次错误码,导致真正的错误原因被掩盖了,比如连接失败,可能不是因为密码错,而是网络不通或者实例名写错了,不把全部错误信息读出来,排查问题就像盲人摸象。
性能上也有讲究,最傻的做法是每次操作都现连接、现断开数据库,那样开销巨大,正确的做法是使用连接池,但用C语言实现连接池得自己写,或者找第三方库,尽量避免在循环里执行单条SQL语句,应该尽量用参数化查询,把多条数据批量插入或更新,参数化查询不仅能提升性能,还能防SQL注入攻击,但ODBC里准备参数也挺啰嗦,要给每个参数设置类型、长度,然后再传值。
还有一个部署时的坑:ODBC驱动版本问题,你开发机器上可能装的是最新版的ODBC Driver 17 for SQL Server,运行得好好的,但部署到客户那台老旧的Windows Server 2008上,可能只有老的SQL Native Client,如果用了新驱动的特性,到老环境上就可能直接连不上,所以开发时最好明确指定使用一个普遍兼容的驱动版本,并且确保目标机器上也安装了相同的驱动。
现在用纯C去连数据库的确实不多了,很多新项目会选择C++的框架(像OTL)或者直接换C#,但如果在嵌入式环境、或者必须用C的遗留系统里,这些坑还是得一个一个踩过去,核心就是细心:细心处理类型、细心管理内存、细心排查错误,每步操作后都检查返回值,做好日志,这样才能让C和SQL Server这对老搭档稳定地跑起来。

本文由畅苗于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/70098.html