Redis卡住了咋办?教你几招快速排查和解决堵塞问题

综合整理自知乎技术社区、Redis官方文档以及阿里云开发者社区的相关问题讨论和解决方案)
Redis卡住了,感觉整个应用都慢了下来,甚至超时报警,这确实是让人头疼的问题,别慌,这就像水管堵了,我们一步步找到堵塞点就能疏通,下面教你几招实用的排查和解决思路,不需要你成为Redis专家也能看懂。
第一招:先确认是不是真的“卡”住了,以及卡的程度
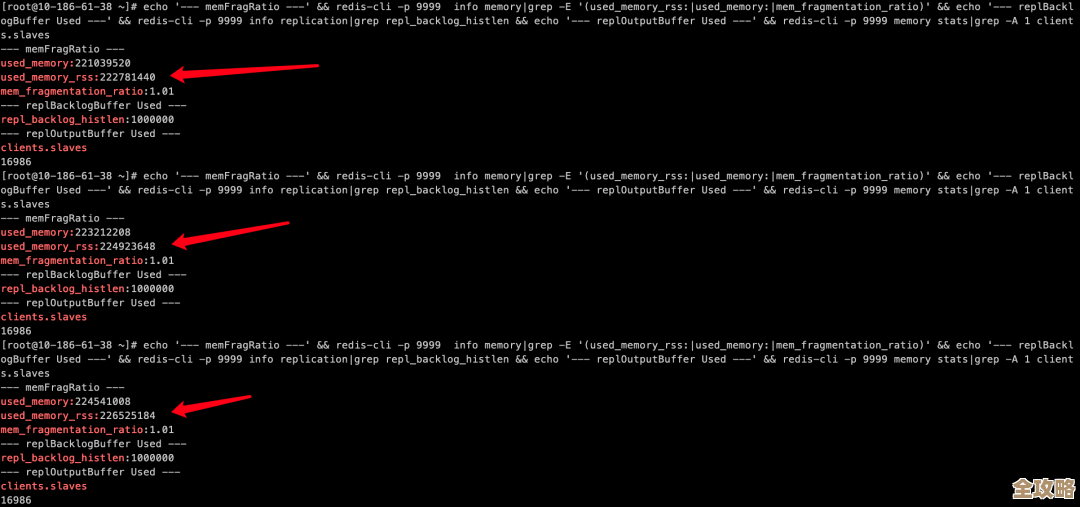
你得有个“仪表盘”来看Redis的健康状况,最直接的方法是使用Redis自带的命令行工具 redis-cli,并加上 --stat 参数试试,在服务器上执行 redis-cli --stat,它会一秒一次地输出一些关键信息,你可以快速看一下每秒处理的命令数是不是特别低,或者干脆没变化。
如果连这个命令都执行不了或者没反应,那说明堵塞比较严重了,这时可以尝试一个非常关键的命令来检测Redis的响应情况:redis-cli -h <你的IP> -p <你的端口> --latency-history -i 5,这个命令会每隔5秒检测一次Redis的响应延迟(latency),正常情况下这个延迟应该在1毫秒以下,或者是个位数毫秒,如果你看到延迟飙升到几百毫秒甚至几秒,那肯定是出问题了,通过这个,你就能量化“卡”的程度。
第二招:找准“堵点”在哪里——内部原因排查
确认Redis确实延迟很高之后,我们就要找原因了,原因大致分两类:Redis服务器内部原因和外部原因,我们先从内部找起。
-
检查慢查询: Redis可能会因为执行某些特别耗时的命令而卡住,使用
SLOWLOG GET 10命令,它可以列出最近10条执行时间最长的命令,你可能会发现一些像KEYS *(这个命令在生产环境绝对要禁用!)、或者对一个大集合(Set/Hash)执行的HGETALL、SMEMBERS,或者一次获取太多的LRANGE命令,这些命令会阻塞Redis,导致其他命令排队。- 解决办法: 找到这些慢查询后,就要优化业务代码,比如用
SCAN替代KEYS,用HSCAN分批获取大数据,避免使用KEYS和FLUSHALL、FLUSHDB这种危险命令。
- 解决办法: 找到这些慢查询后,就要优化业务代码,比如用
-
检查持久化操作: Redis为了把数据保存到硬盘(持久化),会有两种主要方式:RDB快照和AOF日志,如果数据量很大,生成RDB快照(
bgsave)或重写AOF日志(bgrewriteaof)会非常消耗CPU和内存,尤其是在硬盘读写速度慢的机器上,可能会导致Redis短暂卡顿。- 如何判断: 你可以执行
INFO PERSISTENCE命令,查看输出里有没有aof_rewrite_in_progress:1或rdb_bgsave_in_progress:1,这表示正在进行持久化操作。 - 解决办法: 可以考虑优化持久化策略,比如在业务低峰期触发持久化,或者升级硬盘为SSD。
- 如何判断: 你可以执行
第三招:看看是不是“外人”捣乱——外部原因排查
如果Redis内部看起来没啥大问题,那就要把目光转向外部。
-
检查内存使用: 这是最常见的原因之一,执行
INFO MEMORY命令,重点关注used_memory和maxmemory,如果内存使用率接近或达到上限,Redis会开始根据你设置的策略(如LRU)淘汰(evict)数据,这个淘汰过程本身会消耗CPU资源,更糟糕的是,如果内存不够用,并且没有设置淘汰策略或者淘汰不掉,Redis可能连写命令都拒绝执行,导致错误,感觉上就是卡住了。- 解决办法: 要么给Redis加内存,要么优化数据,删除无用键,或者设置合理的淘汰策略(如
allkeys-lru)。
- 解决办法: 要么给Redis加内存,要么优化数据,删除无用键,或者设置合理的淘汰策略(如
-
检查连接数和网络: 执行
INFO CLIENTS查看connected_clients数量是不是异常的高,执行INFO STATS查看total_connections_received和rejected_connections,如果有大量的连接被拒绝,可能达到了maxclients上限,网络带宽被打满也会导致请求缓慢。- 解决办法: 检查应用代码是否有连接泄漏(用了不关),或者是否需要调整
maxclients参数,如果是带宽问题,需要排查是否有大Key被频繁读取。
- 解决办法: 检查应用代码是否有连接泄漏(用了不关),或者是否需要调整
-
检查CPU和机器负载: Redis是单线程工作的,它非常吃CPU的单核性能,如果服务器上还有其他非常耗CPU的进程(比如数据库、其他应用),就会和Redis抢资源,导致Redis处理命令变慢,你可以用
top命令看看Redis进程的CPU占用率是不是一直100%,或者系统整体负载(load average)是不是很高。
第四招:终极武器——使用专业工具
如果以上方法还找不到原因,可以尝试更强大的工具,Redis 4.0引入了“延迟监控框架”,可以帮你更精细地定位延迟产生的环节,你可以通过 CONFIG SET latency-monitor-threshold 100 开启(100是阈值,单位毫秒),然后使用 LATENCY LATEST 和 LATENCY GRAPH <事件名> 来查看详细的延迟事件报告,比如是命令执行慢、还是fork子进程慢等。
总结一下排查步骤:
- 用
--latency-history确认延迟存在。 - 用
SLOWLOG查慢查询。 - 用
INFO MEMORY查内存。 - 用
INFO PERSISTENCE查持久化。 - 用
INFO CLIENTS和top查外部资源。
大部分堵塞问题都能通过以上几步定位,预防胜于治疗,平时多监控Redis的关键指标(内存、延迟、连接数),就能在问题变严重前发现苗头。

本文由黎家于2025-12-29发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/70431.html