MySQL报错ER_GRP_RPL_PRIMARY_KEY_NOT_DEFINED导致故障,远程帮忙修复思路分享

这个故障是我在一次远程支持一个电商网站时遇到的,那天下午,客户突然打电话过来,语气非常着急,说他们的MySQL数据库集群好像出问题了,主库和从库之间的数据同步中断了,而且后台不断刷出一个看不懂的报错,错误代码是“ER_GRP_RPL_PRIMARY_KEY_NOT_DEFINED”,他们自己尝试重启节点,但问题依旧,新数据就是同步不过去,已经影响到线上的订单业务了。
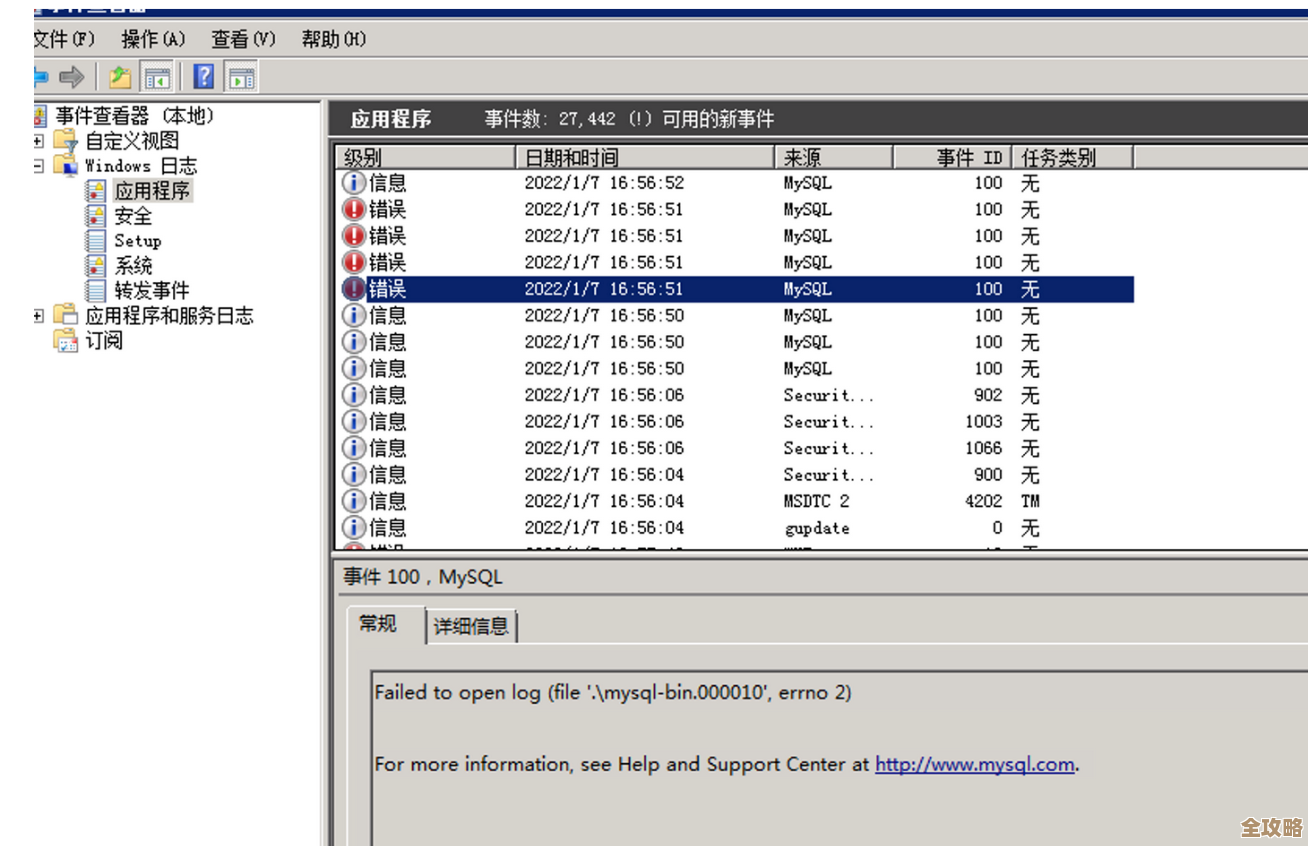
我立刻通过远程桌面连接上去,我确认了他们的环境:是一个三节点的MySQL Group Replication(MGR)集群,这是MySQL官方提供的一种高可用解决方案,我直奔主题,去查看MySQL的错误日志,果然,日志里密密麻麻地都是这个错误信息,根据MySQL官方文档的解释,这个错误的意思是:在组复制环境中,当一个事务需要被复制到其他节点时,如果这个事务操作的表没有定义主键(PRIMARY KEY),组复制就无法安全地确定哪一行数据被修改了,从而导致复制失败。
MGR集群为了保证数据一致性,需要一个唯一标识来精确追踪每一行数据的变更,这个唯一标识最好就是表的主键,如果没有主键,MGR就会很“困惑”,不知道具体该修改哪条记录,为了安全起见,它就直接报错并停止同步了。
我需要找到是哪个表、哪个操作触发了这个错误,我让客户提供了导致同步中断前后一段时间内在主库上执行的SQL语句记录(也就是binlog),通过分析binlog,我很快定位到了罪魁祸首:是一张叫做user_operation_log的用户操作日志表,开发人员在一次紧急的功能上线中,直接对这张表执行了一个UPDATE语句,更新了某个时间点的所有日志记录的状态,而问题就在于,这张user_operation_log表在设计之初,竟然没有设置主键!
修复思路很明确,但操作需要非常小心,因为这是在线上业务运行期间,我的思路是分几步走:
第一步,也是最重要的一步:与客户和他们的开发团队沟通,说明问题的根本原因,我告诉他们,长远来看,数据库里每张表都应该有主键,这不仅是MGR的要求,也是良好的数据库设计规范,他们表示理解,并同意立即修复表结构。
第二步,制定最小化影响的修复方案,直接在业务高峰时段为一张已经有大量数据的表添加主键,可能会锁表很长时间,导致服务不可用,这绝对不行,我提出了两个方案:
方案A:先在从库(当时已停止同步,可视为离线)上测试添加主键的操作耗时和影响,如果表不大,可以考虑使用ALTER TABLE ... ALGORITHM=INPLACE, LOCK=NONE这样的在线DDL操作来添加自增主键,但需要MySQL版本支持,并且不一定所有情况都能无锁完成。
方案B:创建一个新表,这个新表带有主键结构(比如新增一个id BIGINT AUTO_INCREMENT PRIMARY KEY字段),然后分批将旧表的数据导入新表,最后再通过重命名表的方式完成切换,这种方式对业务影响相对可控,但步骤稍多。
经过评估,客户选择方案B,因为他们的数据量不小,在线DDL风险未知。
第三步,具体操作,我指导他们按以下步骤执行:
- 在主库上,停止对新数据的写入(或者确保在切换瞬间没有新数据写入
user_operation_log表)。 - 创建一个新表
user_operation_log_new,表结构和旧表完全一样,但增加了一个自增主键字段id。 - 编写一个小脚本,分批将旧表的数据插入到新表中,由于这是日志表,对事务一致性要求不是极高,分批插入可以减轻数据库压力。
- 数据迁移完成后,在一个业务低峰期,执行原子性操作:先重命名旧表为
user_operation_log_backup,再将新表重命名为user_operation_log,这个操作很快,业务中断时间极短。 - 重启组复制服务,观察同步状态,果然,之前卡住的数据开始顺利同步到从库,错误日志也不再出现。
第四步,事后复盘,我建议客户对数据库设计建立严格的规范,强制要求所有表都必须有主键,并且在测试阶段就进行MGR兼容性检查,避免类似问题再次发生。
这次远程故障修复让我深刻体会到,很多时候数据库集群的故障并不是集群本身有多复杂,而是源于最基础的数据库设计问题,ER_GRP_RPL_PRIMARY_KEY_NOT_DEFINED这个错误就是一个典型的“基础不牢,地动山摇”的例子,在采用MGR这类高级特性时,必须严格遵守它的运行前提条件。

本文由颜泰平于2025-12-29发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/70721.html