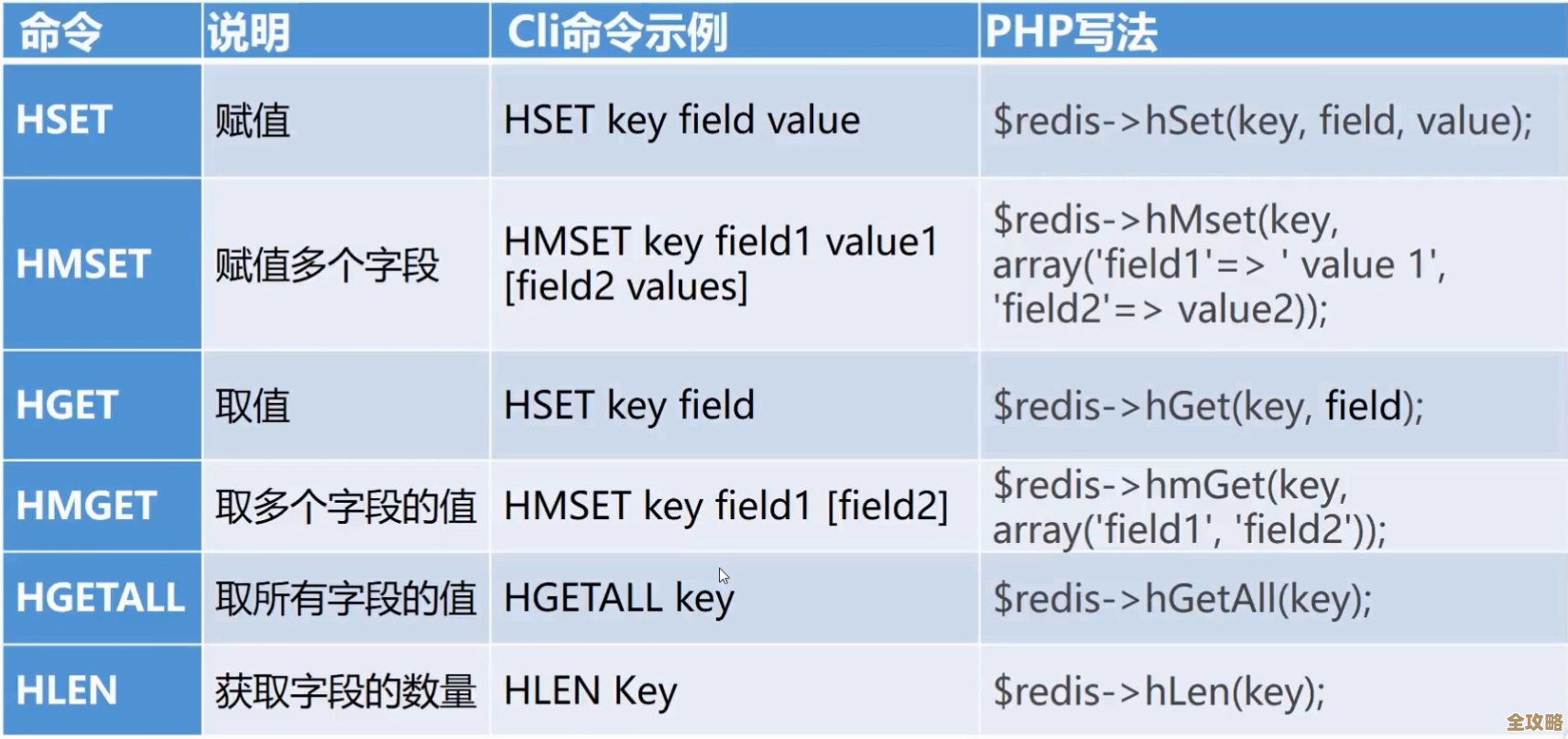
说说Oracle数据库性能那些事儿,怎么监控和查看才靠谱

说起Oracle数据库的性能问题,这确实是让很多DBA和运维人员头疼的大事,数据库就像是一个企业的数据心脏,它要是跳得慢了或者不规律了,整个业务系统都可能跟着瘫痪,怎么才能靠谱地监控和查看Oracle数据库的性能状况,做到心中有数、遇事不慌呢?我们不能只靠感觉,得有一些实实在在的方法和工具。
咱们得知道从哪里看起,根据Oracle官方文档和一些资深DBA的实践经验(如Oracle官方文档《Database Performance Tuning Guide》和Oracle ACE们的技术分享),监控Oracle性能,不能只盯着一个点,得从宏观到微观,层层递进,这就像医生看病,先量体温、测血压,再看具体的化验单。
第一,先看整体“健康状况”——系统级监控。
在怀疑数据库有问题时,第一步不是立刻扎进复杂的SQL语句里,而是先看看数据库所在的服务器“累不累”,这包括:
- CPU使用率:如果服务器的CPU长时间保持在80%甚至90%以上,那肯定有地方不对劲,可能是某些SQL语句把CPU资源耗尽了。
- 内存使用情况:Oracle非常依赖内存,你要关注系统的剩余内存是否充足,以及Oracle的SGA(系统全局区)和PGA(程序全局区)设置是否合理,如果操作系统因为内存不足开始频繁地使用虚拟内存(交换空间),那性能会急剧下降。
- 磁盘I/O:数据库说到底就是读写磁盘,如果磁盘的读写等待时间很长,或者IOPS(每秒读写次数)已经达到磁盘的极限,那么无论SQL写得多好,速度都快不起来,工具像操作系统自带的
iostat(Linux)或vmstat就很好用。
这些是基础,如果这里没问题,那问题可能更集中在数据库内部。
第二,深入数据库内部——等待事件是关键。
这是Oracle性能诊断的核心思想,由Oracle大师Cary Millsap等人提倡(参考《Optimizing Oracle Performance》一书),简单说就是:数据库进程在完成一个任务时,大部分时间不是在干活,而是在“等待”,等待从磁盘读取数据块,等待锁被释放,等待CPU空闲等等,找到“谁”在“等待”什么“事件”,就找到了性能瓶颈的突破口。
怎么查看等待事件呢?Oracle提供了动态性能视图,比如v$system_event(看系统总的等待情况)和v$session_wait(看每个会话当前的等待),通过查询这些视图,你能发现当前数据库最突出的等待类型。
- 如果
db file sequential read等待很高,通常意味着全表扫描过多,需要优化SQL和索引。 - 如果
enq: TX - row lock contention等待很高,说明应用层面可能存在严重的事务锁竞争。
第三,揪出“捣蛋鬼”——分析高负载SQL。
很多时候,80%的性能问题是由20%的糟糕SQL语句引起的,定位并优化这些SQL是提升性能最有效的手段。
怎么找这些SQL?可以看:
- 执行时间最长的SQL:在
v$sql视图中,可以按ELAPSED_TIME( elapsed time)排序,找出那些累计执行时间很长的语句。 - 逻辑读最多的SQL:逻辑读是指从内存中读取数据块的次数,这个值越大,说明SQL消耗的CPU资源越多,在
v$sql中按BUFFER_GETS排序。 - 磁盘读最多的SQL:在
v$sql中按DISK_READS排序,找出那些导致大量物理I/O的语句。 - 实时监控:使用
v$session视图结合v$sqltext,可以查看当前正在执行的会话正在跑什么SQL,以及它的状态。
找到可疑SQL后,下一步就是用EXPLAIN PLAN命令查看它的执行计划,看看它是怎么访问数据的,是全表扫描还是走了索引,连接方式是否高效等等。
第四,利用好现成的工具——AWR和ASH。
对于Oracle企业版用户,有两个非常强大的内置工具:AWR(自动工作负载仓库)和ASH(活动会话历史)。
- AWR:相当于数据库的“体检报告”,它默认每小时快照一次系统状态(比如等待事件、SQL统计、系统负载等),并生成一份报告,通过对比两个时间点的AWR报告,你可以清晰地看到在问题时间段内,数据库的各项指标发生了什么变化,哪个等待事件突增,哪条SQL变得异常活跃,这是进行系统性性能分析的首选工具。
- ASH:相当于数据库的“实时监控录像”,AWR是小时级别的,而ASH是秒级的,它每秒采样一次当前活动会话的信息,当发生一个短暂的、持续几分钟的性能抖动时,AWR可能捕捉不到细节,但ASH可以让你像回放录像一样,看到那几分钟里每一个会话在干什么、在等待什么,这对于诊断间歇性性能问题至关重要。
总结一下靠谱的监控思路:
- 由外而内:先看操作系统资源(CPU、内存、磁盘)是否成为瓶颈。
- 由总到分:通过等待事件分析,确定系统级的主要矛盾。
- 聚焦重点:抓住那些消耗资源最多、执行效率最低的SQL语句进行优化。
- 善用工具:充分利用AWR/ASH这种高级工具,让数据说话,避免盲目猜测。
- 建立基线:在系统运行良好时,保存一份AWR报告作为性能基线,这样出问题时,就有可比对的“健康标准”了。
性能优化是一个持续的过程,而不是一次性的任务,建立一个常态化的监控机制,才能防患于未然,真正让数据库性能变得靠谱。

本文由瞿欣合于2025-12-29发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/70913.html