Redis的key太大了会出问题,存储和性能都得注意别忽视这个限制

关于Redis的key设计,有一个非常关键但时常被开发者忽略的要点:key的大小绝不能随意,一个过大的key,就像是在一条本应畅通无阻的高速公路上突然设置了一个超宽超重的巨型卡车,它不仅自身移动困难,更会严重阻塞整个交通网络,给Redis的存储效率和运行性能带来一系列连锁问题。
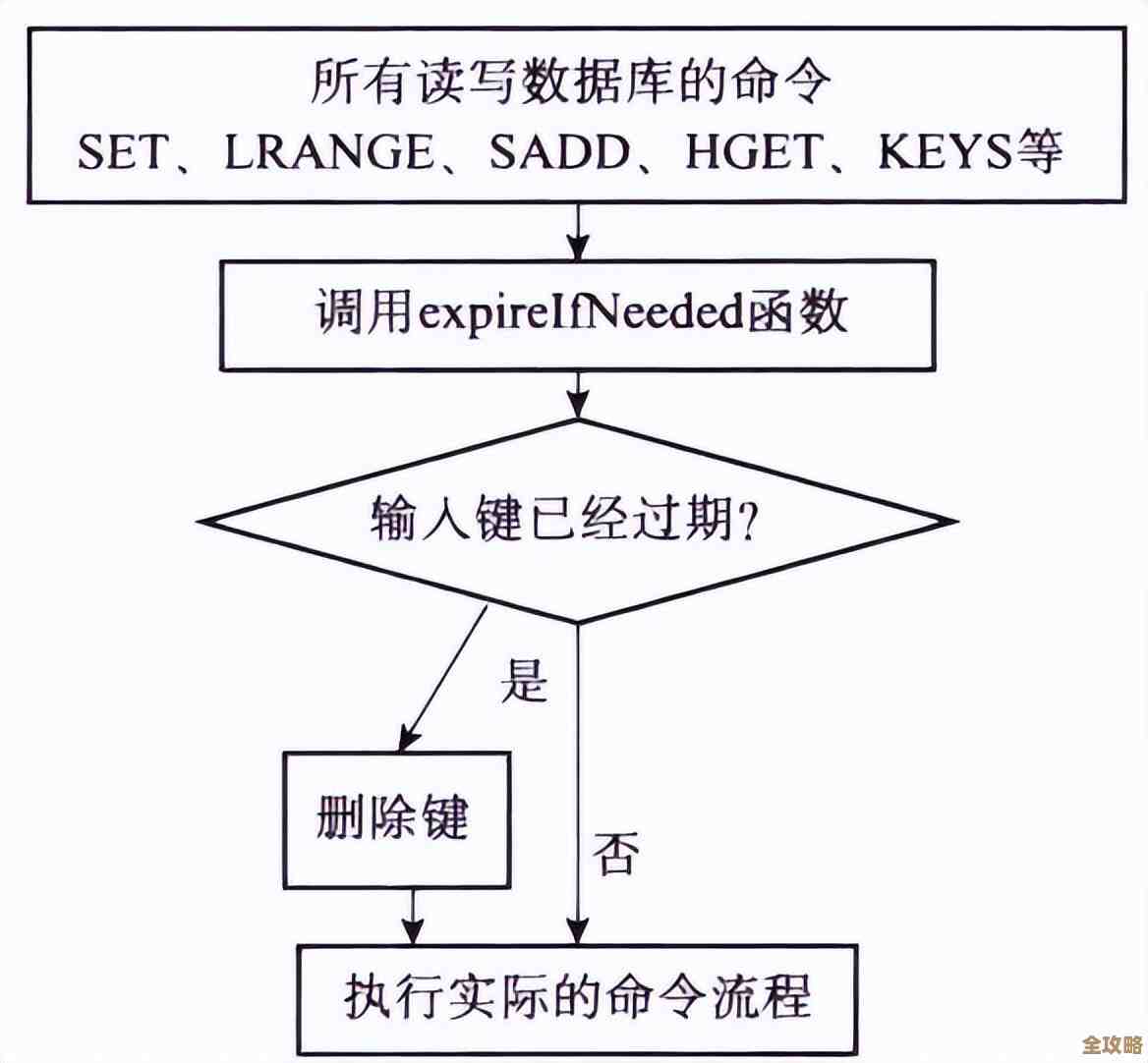
我们从最直接的存储层面来看,Redis虽然常被用作缓存,数据可能有过期时间,但只要key存在,它就会占用内存,一个key本身就是一个字符串对象,Redis在内部为了高效管理内存,针对不同长度的字符串会采用不同的编码方式,当key的长度很小(例如小于39字节)时,Redis会使用一种叫做embstr的紧凑型编码,这种编码方式下,key的元数据和实际字符串值会分配在同一块连续的内存空间中,这样效率非常高,一旦key的长度超过了这个阈值,Redis就会转而使用raw编码,此时元数据和字符串值会分开存储,这本身就会带来一些额外的内存开销,这还仅仅是key本身的开销,如果再考虑到Redis维护全局字典(可以理解为一个巨大的索引表)所需要的数据结构,比如字典、指针等,每一个key无论大小,都会在这些结构中占据一份空间,当一个key的长度从十几个字节膨胀到几百甚至几千字节时,这份“固定”的开销就会被不成比例地放大,你存储的可能是几个KB的value,但光是为了“这个value的名字(也就是key),就先付出了几百字节甚至更多的内存代价,在数据量巨大、追求极致内存利用率的场景下,这种浪费是绝对不能接受的。

也是更严重的问题,在于性能方面,Redis的核心优势就是其惊人的速度,而这速度很大程度上源于其单线程的内存操作模型,所有命令都是按顺序执行的,这意味着如果一个操作耗时过长,就会阻塞后续所有命令,造成请求延迟飙升,甚至引发雪崩效应,一个大key就是这种单线程模型的“杀手”。
第一,读写大key的网络传输耗时。 当你使用GET或SET命令操作一个value体积巨大的key时(比如一个包含几十万元素的Hash或者一个几MB的String),客户端和服务器之间需要传输的数据量非常大,网络传输本身就需要时间,数据量越大,耗时自然越长,这段时间里,Redis服务器需要为这个连接分配资源,等待数据发送或接收完毕,无法处理其他请求,这直接导致了平均响应时间的增加。

第二,Redis服务器自身的序列化/反序列化开销。 即便网络传输瞬间完成,Redis在处理命令时,也需要对数据进行解析,操作一个巨大的value,其CPU计算成本远高于操作一个小的value,你要修改一个巨大Hash中的某个字段,Redis需要先找到这个key,然后解析整个Hash结构,再定位到具体字段进行修改,这个解析过程对于大key来说,是一个O(N)时间复杂度的操作,value越大,耗时越久,这段时间,线程同样被独占。
第三,也是最危险的,删除大key引发的长时间阻塞。 这是大key最经典的“坑”,当你对一个有大value的key执行DEL命令,或者这个key设置了过期时间而Redis需要自动清理它时,问题就出现了,为了释放内存,Redis需要遍历整个数据结构并逐个释放内存空间,删除一个存储了几十万个元素的Set或List,或者一个几MB的String,可能不是毫秒级,而是几十甚至几百毫秒级的操作,在这整个删除过程中,Redis主线程是完全阻塞的,无法响应任何其他命令,对于要求低延迟的应用(如实时排行榜、会话存储)这种长达百毫秒的停顿是灾难性的,会导致大量请求超时,用户体验急剧下降,甚至被监控系统误判为服务宕机。

在Redis主从复制和持久化机制中,大key也会带来麻烦,主从全量同步时,主节点需要生成RDB快照文件,如果存在大key,生成RDB的过程可能会因为序列化这个大key而变慢,延长了从节点的同步时间,同样,在AOF重写(BGREWRITEAOF)过程中,父进程需要遍历数据库生成新的AOF文件,大key的存在同样会拖慢这个关键后台任务的执行速度,如果重写时间过长,还可能因为累积的AOF日志过多而引发更复杂的问题。
key到底多大才算“大”呢?并没有一个绝对的标准,这取决于你的Redis实例规格、业务可接受的延迟水平以及QPS,但业界通常有一些经验性的参考值,阿里云等云服务商在其最佳实践中会建议(来源:阿里云Redis开发规范),一个String类型的value大小最好控制在10KB以内,而对于集合类型(Hash、List、Set、Sorted Set)的元素数量,建议不要超过5000,如果value超过10KB或者集合元素超过1万,就可以认为存在大key风险,需要引起警惕并考虑优化。
如何发现和解决大key问题呢?Redis 4.0版本之后提供了--bigkeys扫描命令,可以帮我们找出实例中的大key,解决方案的核心思想是“化整为零”,不要用一个巨大的key存储所有数据,而是进行拆分,一个存储了百万用户信息的巨大Hash,可以按照用户ID的范围或哈希值,拆分成成千上百个小的Hash key,一个巨大的List可以拆分成多个List,或者使用更合适的数据结构,通过将数据分散到多个key上,可以将原本集中式的、耗时的操作,分散成多个快速的、可并行的小操作,从而避免对Redis单线程模型造成冲击,保证整个服务的稳定性和高性能。
在设计Redis的key时,时刻绷紧“key不能太大”这根弦,是保证Redis能够持续提供高性能、低延迟服务的基本前提,忽视这个限制,就如同埋下了一颗定时炸弹,随时可能在业务高峰期引爆,导致严重的性能故障。
本文由畅苗于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/70973.html