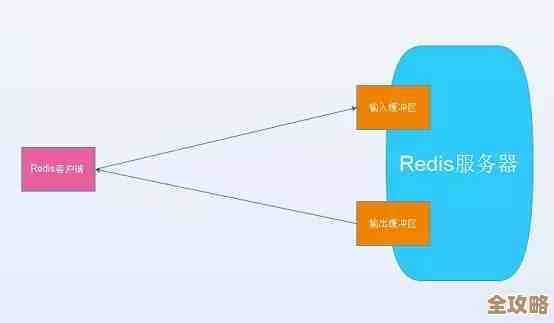
Redis内存不够用导致系统卡顿,赶紧调大内存别让瓶颈拖后腿

前段时间,我们系统遭遇了一次比较严重的卡顿,页面加载慢得像蜗牛,一些关键操作时不时就超时失败,用户抱怨声一片,技术团队火速排查,最后定位到问题根源:Redis服务器的内存用满了,这次经历让我们深刻意识到,对于严重依赖Redis的系统来说,内存容量绝不是可以掉以轻心的环节,一旦它成为瓶颈,整个系统都会被拖垮。
情况是这样的: 我们的系统用Redis做了很多事,比如缓存用户会话信息、存储热点数据、还有用作一些临时任务的队列,一直以来都运行得不错,但随着业务量持续增长,尤其是搞了几次促销活动后,存入Redis的数据量悄然逼近了当初设定的内存上限,出事那天,业务峰值一来,Redis试图写入新数据时,发现内存已经触顶了。

根据Redis官方文档的处理逻辑,当内存满了之后,它会根据一个预设的策略来淘汰旧数据,以便给新数据腾地方,我们当时设置的可能是“allkeys-lru”策略,意思是尝试淘汰最近最少使用的键,这个策略本身没问题,但在内存严重不足、写入请求又非常频繁的高峰期,问题就暴露出来了,Redis需要额外消耗大量的CPU资源去计算哪些键应该被淘汰,然后执行删除操作,这个过程中,处理正常读写请求的资源就被严重挤占了,导致响应速度急剧下降,更糟糕的是,如果淘汰速度赶不上写入速度,有些写入命令甚至会直接失败,这就好比一个仓库已经爆满,管理员不得不紧急清退一些旧货物才能放进新货,清退的过程既费时又费力,导致整个仓库的出入库流程都瘫痪了。
为什么内存不够会影响这么大? 这要从Redis的设计特点说起,Redis的核心优势就是其超凡的速度,而这个速度是建立在所有数据都放在内存基础上的,内存的读写速度远远快于磁盘,内存资源是有限且相对昂贵的,当所有内存都被占用后,Redis就失去了它最大的依仗,它不能像传统数据库那样从容地把不常用的数据换到磁盘上(虽然Redis有持久化机制,但那是为了数据安全,不是用来扩展内存的),只能立即在现场进行“垃圾分类”,这个紧急处理动作,就像在一条高速公路上突然进行道路施工,必然造成全线拥堵。

我们的应对和教训: 当时为了快速恢复服务,我们第一时间联系运维同事,紧急调整了Redis实例的内存配置上限(比如从8G调大到16G),内存空间一大,Redis立刻从“频繁垃圾回收”的窘境中解脱出来,CPU负载骤降,系统响应速度很快就恢复了正常,这简直就是立竿见影的效果。
但这件事也给我们敲响了警钟,单纯调大内存只是临时救火,不是根治办法,我们后续做了几件事:
- 监控预警: 加强了监控,设定了更严格的内存使用率阈值(比如超过80%就告警),让我们能提前发现问题,而不是等挂了再处理。
- 分析内存使用: 使用Redis自带的命令(比如
INFO memory,MEMORY STATS)深入分析内存都用在了哪里,看看有没有不合理的大Key(单个键存储数据过大)或者大量无用的缓存数据。 - 优化数据结构和过期时间: 审查代码,优化了一些数据结构的使用,比如能用更节省内存的哈希结构就不用字符串;给缓存数据设置了更合理的过期时间,避免无用数据长期堆积。
- 考虑架构调整: 对于非核心的、量特别大的缓存数据,考虑是否可以用其他方案分担压力,或者对Redis集群进行分片,从架构上扩展容量。
Redis内存用满导致系统卡顿是一个典型的资源瓶颈问题,它提醒我们,在享受Redis高性能带来的便利时,必须时刻关注其资源水位。“赶紧调大内存”是故障发生时最直接有效的应对策略,能迅速解除瓶颈,让系统恢复畅通,但从长远看,建立 proactive 的监控、定期优化内存使用、规划好容量,才是避免类似问题再次发生、不让Redis从性能加速器变成系统拖累的关键。
本文由水靖荷于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71296.html