Redis生产环境那些事儿,运维中你得知道的关键点和技巧

主要综合自Redis官方文档的运维建议、阿里云开发者社区的《Redis开发与运维》读书笔记以及部分资深运维工程师的经验分享)

内存是Redis最重要的资源,你得时刻盯着内存使用率,不能等快满了才处理,一旦内存用尽,Redis会开始根据你设置的maxmemory-policy策略来淘汰数据,比如淘汰最近最少使用的键(LRU),或者直接拒绝写入,如果你的应用不允许丢失数据,那就要非常小心淘汰策略的选择,有个常见的坑是,你以为设置了淘汰策略就高枕无忧了,但实际上如果瞬时写入量巨大,可能还没来得及淘汰,内存就先爆了,导致写失败,监控内存使用趋势并提前扩容是关键,要警惕内存碎片,可以通过info memory命令查看mem_fragmentation_ratio指标,如果这个值长时间远大于1.5,可能就需要考虑重启实例来整理碎片了。
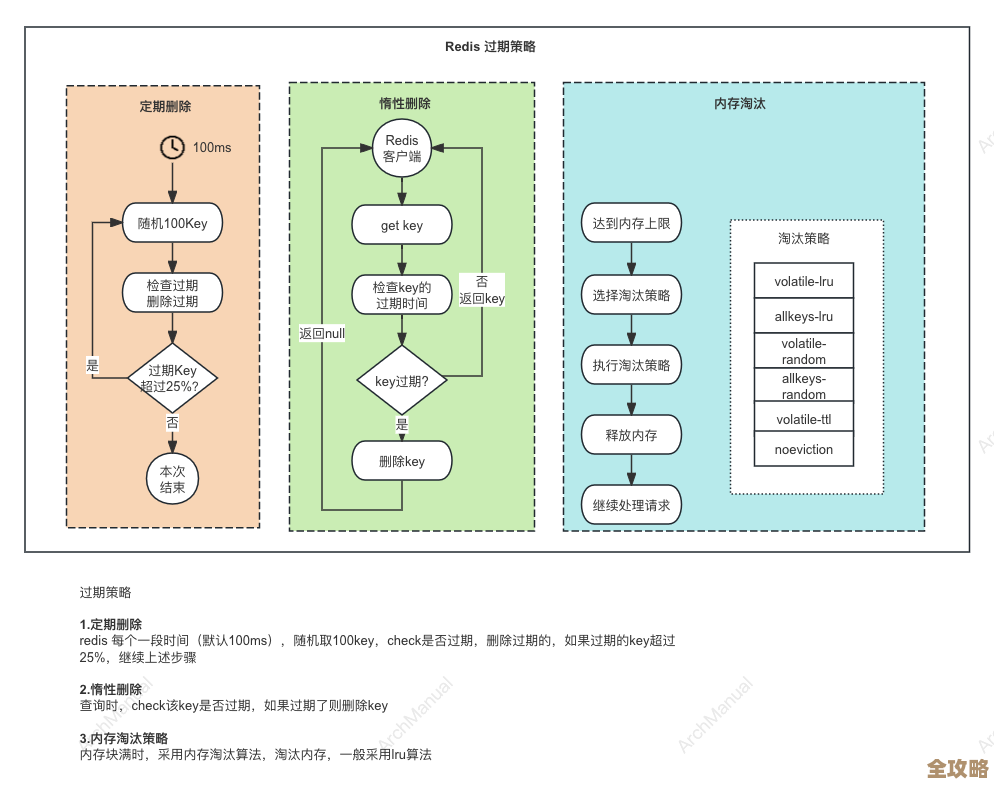
持久化配置是保证数据不丢的基石,Redis主要有两种:RDB和AOF,RDB是定时拍快照,恢复快,但可能会丢失最后一次快照到故障期间的数据,AOF是记录 every write operation,数据安全性高,但文件会越来越大,恢复起来也慢,生产环境通常建议两者都开启,用AOF保证数据安全,用RBD做冷备和快速恢复,这里有个关键技巧,在Redis 4.0之后,有一个混合持久化(AOF-use-rdb-preamble)的选项,开启后AOF文件在重写时会把当前数据以RDB格式写入文件头,这样既保证了快速恢复又能获得AOF的增量数据优势,强烈推荐使用,要定期检查AOF文件的重写过程是否正常,避免AOF文件无限膨胀吃掉磁盘空间。

第三,高可用和故障转移不能马虎,单节点Redis挂了服务就全停了,所以生产环境一定要用哨兵(Sentinel)或者集群(Cluster)模式,哨兵模式负责监控主节点,主库挂了能自动选一个从库升为主库,实现故障自动切换,但你需要部署至少三个哨兵实例来避免误判,集群模式则主要是为了解决单机内存瓶颈,通过分片(sharding)把数据分布到多个节点上,同时它也内置了高可用能力,选择哪种模式要看你的业务需求:如果数据量不大,但要求高可用,用哨兵;如果数据量巨大,必须分片,就用集群,部署好后,一定要模拟一下主库宕机,看看故障转移是否能按预期工作,这是检验配置是否正确的唯一标准。
第四,性能优化和慢查询排查是日常功课,Redis虽然快,但使用不当也会慢,首先要禁用类似KEYS *这样的危险命令,它会阻塞整个服务器,可以用SCAN命令代替做模糊查询,通过slowlog命令设置慢查询日志的阈值(比如10毫秒),定期检查是哪些命令执行慢了,常见的原因可能是用了O(N)复杂度的命令操作大集合(比如对一个百万成员的集合执行HGETALL),或者网络延迟,监控网络带宽和CPU使用率也很重要,如果CPU跑满了,性能瓶颈可能就不在Redis本身了,对于热点Key问题,如果某个Key的访问频率异常高,可以考虑将这个Key拆分成多个子Key,分散压力。
第五,安全防护是底线,千万别把Redis直接暴露在公网上,用防火墙严格限制可访问的IP地址,一定要给Redis设置一个强密码(requirepass配置),虽然这个认证机制比较简单,但能挡住大部分扫描和攻击,如果条件允许,可以使用SSL/TLS加密客户端与Redis之间的通信,要谨慎处理CONFIG命令,可以考虑通过rename-config命令把它重命名成一个难以猜测的名字,防止被恶意修改配置。
监控和告警是你的眼睛和耳朵,不能只靠人工登录服务器去看,需要有一套监控系统持续收集Redis的关键指标:内存使用率、连接数、每秒操作数(QPS)、延迟(latency)、Key淘汰数量、主从复制状态等,一旦这些指标出现异常波动,比如延迟突然飙升、从库连接断开,告警系统要能立即通知到你,只有建立了完善的监控,你才能在问题影响用户之前发现并解决它。
在生产环境运维Redis,核心思想就是“防患于未然”,通过合理的配置、充分的测试、持续的监控和清晰的处理预案,才能让Redis稳定高效地为你服务。

本文由度秀梅于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71784.html