Redis老是连不上地址池,咋整才能稳妥解决这事儿呢

咱得弄明白,连接池为啥会“连不上”,这就像一个小卖部(你的应用程序)和一个大仓库(Redis服务器)做生意,小卖部为了方便,不会每次进货都现派个人去仓库,而是在仓库里设了个小办公室(连接池),长期驻留几个伙计(数据库连接),专门负责搬货,连不上”了,无非是几个原因:要么是去仓库的路不通(网络问题),要么是仓库大门坏了或者仓库满了(Redis服务器问题),要么是小卖部自己管理伙计的方式出了问题(连接池配置或应用代码问题)。
第一步:先别瞎折腾,搞清楚到底是哪儿疼
当问题出现时,别急着去改配置,先像老中医一样“望闻问切”。
-
看错误日志:这是最直接的线索。 错误信息通常会告诉你大概方向,是“Connection refused”(连接被拒绝)?还是“Connection timeout”(连接超时)?或者是“Read timeout”(读取超时)?不同的错误对应不同的问题。
- “Connection refused”(连接被拒绝):这通常意味着Redis服务器根本就没开机,或者你找的地址端口不对,就好比你按照地址去找仓库,结果发现那儿是块空地,这时候你得去确认一下Redis服务是不是正常运行着 (
systemctl status redis或者ps aux | grep redis),并且检查一下你的应用程序里配置的Redis地址(host)和端口(port)是不是写错了。 - “Connection timeout”(连接超时):这意思是,去找仓库的路太堵了,在规定时间内根本没走到,这说明是网络层面的问题,可能是网络延迟太高,也可能是防火墙把路给拦了,你需要用
telnet或者ping命令测试一下从你的应用服务器到Redis服务器网络是否通畅,端口是否开放。 - “Read timeout”(读取超时):这个有点不一样,路是通的,人也到仓库了,但是交代给仓库伙计(Redis连接)办事,他磨磨蹭蹭老半天没回信,这可能是Redis服务器本身压力太大,处理命令非常慢(比如在执行非常耗时的命令),也可能是网络不稳定,数据包丢了。
- “Connection refused”(连接被拒绝):这通常意味着Redis服务器根本就没开机,或者你找的地址端口不对,就好比你按照地址去找仓库,结果发现那儿是块空地,这时候你得去确认一下Redis服务是不是正常运行着 (
-
看看Redis服务器自个儿咋样: 连上Redis服务器,用
redis-cli工具输入info命令,重点关注几块内容:connected_clients:当前有多少个客户端连着,如果这个数特别高,快接近你的maxclients(最大客户端数,默认10000)了,那说明连接数爆了,新连接自然就进不来了。used_memory:用了多少内存,如果快满了,Redis可能会开始卡顿,甚至拒绝写入。instantaneous_ops_per_sec:每秒操作数,看看是不是有突发的高流量把Redis打挂了。blocked_clients:有多少客户端被阻塞了,如果有很多,说明可能有慢查询堵住了。
第二步:对症下药,从根儿上整治

摸清情况后,就可以动手解决了。
规整一下你的应用代码(管好小卖部的伙计)
很多时候,问题出在应用没有正确使用和释放连接,这叫“连接泄漏”。
- 确保用完就还: 这听起来是废话,但最容易出问题,你的代码里,每一次从连接池借走一个连接(比如执行一个Redis命令),操作完成后,必须把它还回池子里,在Java里就是用完了
close(),在Python的redis-py里通常用with语句块来自动管理,如果忘了还,这个连接就永远占着茅坑不拉屎,池子里的连接会越来越少,直到耗尽。 - 设置合理的超时时间: 给你的操作设置一个“等待耐心值”,包括连接超时(等建立连接多久)、读取超时(等返回结果多久),别无限期等下去,超时了就报错,然后你可以决定是重试还是直接失败,这样能避免线程被长时间挂起,具体设置多少,要根据你的业务容忍度和网络状况来定。
- 避免慢查询: 别让伙计去搬一座山,像
keys *这种命令,在数据量大的时候简直是灾难,它会阻塞Redis很长时间,导致其他所有命令都卡住,用SCAN代替KEYS,小心处理FLUSHALL、MONITOR等命令。
调教一下连接池的配置(优化伙计的调度规则)

连接池本身也有些参数可以调整,让它更适应你的业务。
- 最大连接数 (
maxTotal或max_connections): 池子里最多养多少个伙计,不是越大越好,够用就行,设太大了浪费资源,还可能压垮Redis,设太小了,高并发时伙计不够用,就得排队等。 - 最大空闲连接数 (
maxIdle): 活干完了,最多留几个伙计在办公室闲着,闲着的伙计可以快速响应新任务,这个值可以设得和最大连接数差不多,避免频繁地创建和销毁连接(这很耗资源)。 - 最小空闲连接数 (
minIdle): 办公室至少得留几个伙计待命,以备不时之需,可以防止流量突然来时,临时招人手忙脚乱。 - 获取连接的最大等待时间 (
maxWaitMillis): 当池子里没空闲伙计时,新任务愿意等多久,等太久了用户体验差,设置短一点可以快速失败降级。
检查和加固基础设施(修好路和仓库大门)
- 网络问题: 如果跨机房或者用云服务,网络不稳定是常事,考虑让应用和Redis在同一个机房或虚拟私有云(VPC)内,减少网络跳数,如果是防火墙问题,好好检查一下安全组规则。
- Redis服务器资源: 确保Redis服务器的CPU、内存够用,别让仓库本身又小又破,监控服务器的系统资源。
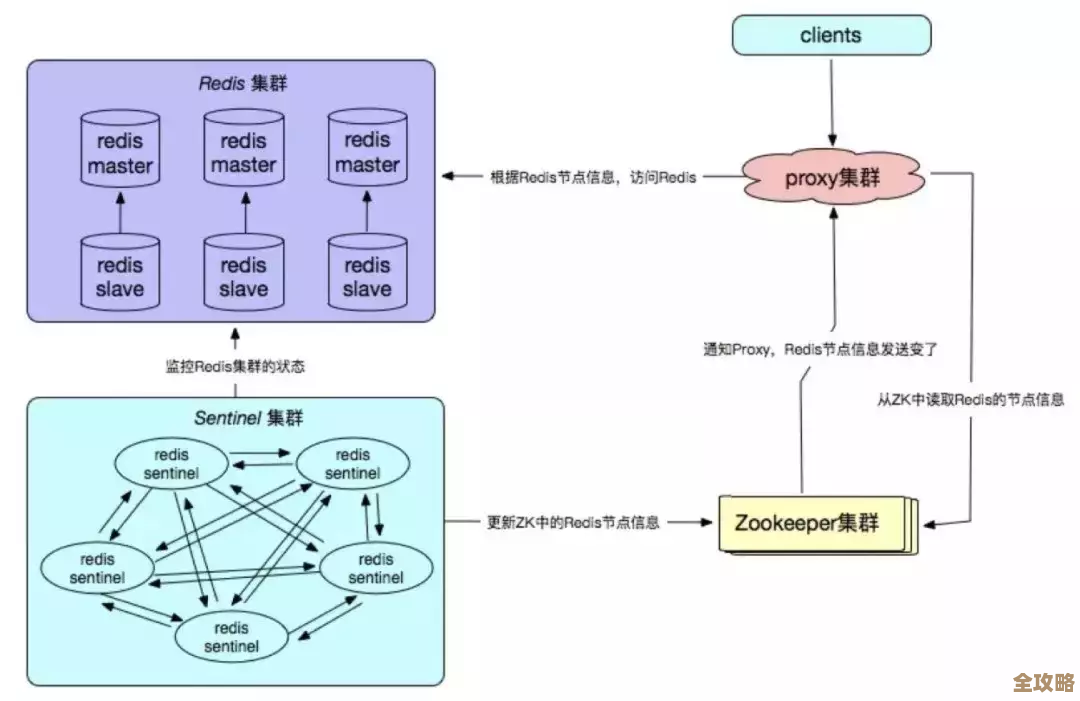
- 考虑高可用: 如果业务很重要,不能容忍Redis宕机,就别用单机版的Redis了,上 Redis Sentinel(哨兵) 或者 Redis Cluster(集群),哨兵能实现主从切换,主库挂了,哨兵能自动选个从库当新主库,应用通过连接哨兵就能自动拿到新的主库地址,集群则能分散数据和压力,这就好比给仓库搞个备用的,或者开几个分仓,一个不行了还有别的顶上。
第三步:建立长效监控机制(装上摄像头和警报器)
问题解决后,不能就撒手不管了,得装上监控。
- 监控连接池 metrics: 很多客户端都提供监控指标,比如当前活跃连接数、空闲连接数、等待获取连接的线程数、连接创建销毁次数等,把这些指标接到你的监控系统(如Prometheus+Grafana)里,画成图表,一旦发现空闲连接数持续为0,或者等待线程数飙升,就能提前预警。
- 监控Redis服务器指标: 持续关注前面提到的
connected_clients,used_memory, 内存碎片率等。 - 设置告警: 当关键指标出现异常(比如连接数超过阈值、内存使用率超过90%)时,及时发短信、发邮件通知你。
解决Redis连接池问题,就是个“排查 -> 优化 -> 监控”的循环过程,先从最简单的日志和服务器状态查起,优先检查代码有没有正确释放连接,然后根据业务量调整连接池参数,最后在基础设施和监控上投入,实现长治久安,这样一步步来,就能把这烦人的事儿稳妥地解决掉。
本文由黎家于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71853.html