MySQL报错MY-011728,无法转换数据包成事件,远程帮忙修复故障

开始)
用户打电话来说他的MySQL数据库出问题了,具体报错代码是MY-011728,错误信息全文大概是这样的:[MY-011728] [Repl] Slave I/O for channel '': Got fatal error 1236 from master when reading data from binary log: 'Cannot replicate because the master's binary log is corrupted (the first event 'mysql-bin.000017' at 154, the last event read from './mysql-bin.000017' at 125, the last byte read from './mysql-bin.000017' at 125).' Error_code: MY-011728。

这个错误看着挺长的,但其实核心意思就是说,主从复制架构里,那个从库在尝试读取主库的二进制日志文件时,发现这个日志文件好像坏掉了,数据对不上,所以从库的IO线程就罢工了,报了这么一个错。“无法转换数据包成事件”这个描述,其实就是指从库拿到了主库发过来的二进制日志数据包,但是这个数据包的内容不符合预期,它没办法把这个数据包解析成一个有效的数据库操作事件。
这个错误通常发生在主从复制环境里,就是主库把对数据库的每一个改动都记录在一个叫二进制日志的文件里,然后从库会不停地去主库拉取这些日志,在自己身上重新执行一遍,这样就能保证主从数据一致,现在的问题是,从库在拉取一个叫mysql-bin.000017的日志文件时,发现这个文件从某个位置开始,内容不对劲了,可能是损坏了。

为什么好端端的二进制日志会损坏呢?根据网上一些技术社区的讨论和MySQL官方文档的提示,可能的原因有好几种,第一种是硬件问题,比如存放二进制日志文件的磁盘坏了,有坏道,导致写入的数据不完整或者读出来是错的,第二种是操作系统层面的问题,比如在MySQL服务还在运行、正在往日志文件里写数据的时候,服务器突然断电了,或者系统崩溃了,这很可能导致日志文件只写了一部分,成了一个不完整的文件,第三种可能是网络问题,虽然不那么常见,但如果主从库之间的网络连接非常不稳定,在传输日志内容的过程中发生了严重的数据包丢失或损坏,也可能导致从库收到一个残缺的数据包,第四种可能是MySQL服务器软件本身出现了罕见的bug,但这种情况概率比较低。
现在用户是要求远程帮忙修复,我们人不在现场,只能通过远程连接上去操作,所以修复的思路就是,既然这个从库卡在了一个坏的日志文件上,那我们就要想办法让它跳过这个损坏的点,重新从主库的一个正确的位置开始同步。

具体的操作步骤,根据一些有经验的DBA在论坛上分享的案例,大概是这样的,我们需要远程登录到出问题的从库服务器上,连接到MySQL数据库,第一步,要先停止掉复制相关的线程,执行命令STOP SLAVE; 或者更具体的 STOP SLAVE IO_THREAD;,这样从库就不会再尝试去连接主库和读取那个坏掉的日志了。
第二步,我们需要确定一下损坏的严重程度,可以尝试在主库上检查一下那个被报错的二进制日志文件mysql-bin.000017的状态,用命令SHOW BINARY LOGS;看看这个文件是否还存在,文件大小是不是正常,可能只是这个文件的一小部分损坏了,如果情况不严重,可以尝试在主库上使用MySQL自带的工具mysqlbinlog来解析这个文件,比如执行mysqlbinlog mysql-bin.000017,看能不能正常读出日志内容,如果能读出来,只是中间有一小段读不了,那我们可以手动定位到损坏位置之后的一个有效位置。
如果这个文件损坏得很厉害,或者我们不想那么麻烦地去一点点找位置,更常用也更稳妥的办法是直接让从库放弃这个文件,从一个全新的位置开始同步,这就需要进行主从复制的重新搭建,第三步,我们需要在主库上创建一个新的数据库备份快照,因为从库当前的数据可能已经和主库不一致了,直接重新指定日志位置可能会造成更多数据混乱,比较安全的方法是,先在主库上执行一个全量备份,可以使用mysqldump工具,备份的时候要记住使用--master-data参数,这个参数会在备份文件里记录下当前主库的二进制日志位置信息,这样从库恢复的时候就知道该从哪儿开始继续同步了。
第四步,把主库上做好的这个备份文件传输到从库服务器上,第五步,在从库上先清除掉旧的复制信息,执行RESET SLAVE ALL;命令,把从库上现有的数据清空(如果允许的话),再用主库传过来的备份文件重新导入数据,恢复到一个一致的状态,第六步,根据备份文件里记录的二进制日志位置信息,重新配置从库指向主库,执行CHANGE MASTER TO ...命令,指定主库的地址、用户名、密码以及开始复制的日志文件和位置,启动从库复制,执行START SLAVE;,并检查复制状态SHOW SLAVE STATUS\G,看看IO线程和SQL线程是不是都正常跑起来了,有没有再报错。
在整个处理过程中,沟通很重要,要告诉用户,修复期间主从复制会中断一段时间,可能会对业务有影响,比如读流量不能分担到从库了,还要建议用户,问题修复后,最好查一下服务器硬件健康状况,特别是硬盘,看看是不是有预警,检查一下MySQL的配置,确保sync_binlog参数是设置为1的,这样可以最大程度地降低服务器意外断电时日志损坏的风险,如果可能,给数据库服务器配个UPS不间断电源也是个好主意。
结束)
本文由凤伟才于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/72139.html
相关文章
-
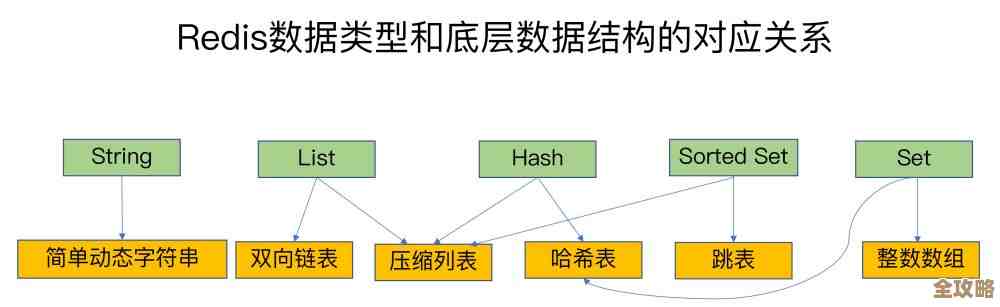
Redis主备信息怎么查啊,有没有简单点的方法快速看清楚主从状态
-

态牛-Tech Neo带你看看企业级运维那些事儿,别光听说得亲自体验才知道啥叫真运维
-
MySQL报错MY-010663,涉及NDB日志事务ID问题,远程帮忙修复故障中
-
云计算基础里头的虚拟化技术,KVM和XEN到底差在哪儿,一篇文章帮你搞明白
-

ORA-07268报错搞不定?szguns的getpwuid错误远程帮你快速排查修复
-

秒杀活动用Redis的Get查最低价,速度快到飞起,redis查询那块真香
-

其实云计算数据管理里,有几个特别重要的点,没掌握好就挺难真正解锁那些潜力的
-
用Redis来存储和读取真实图片,实际操作和思路分享



