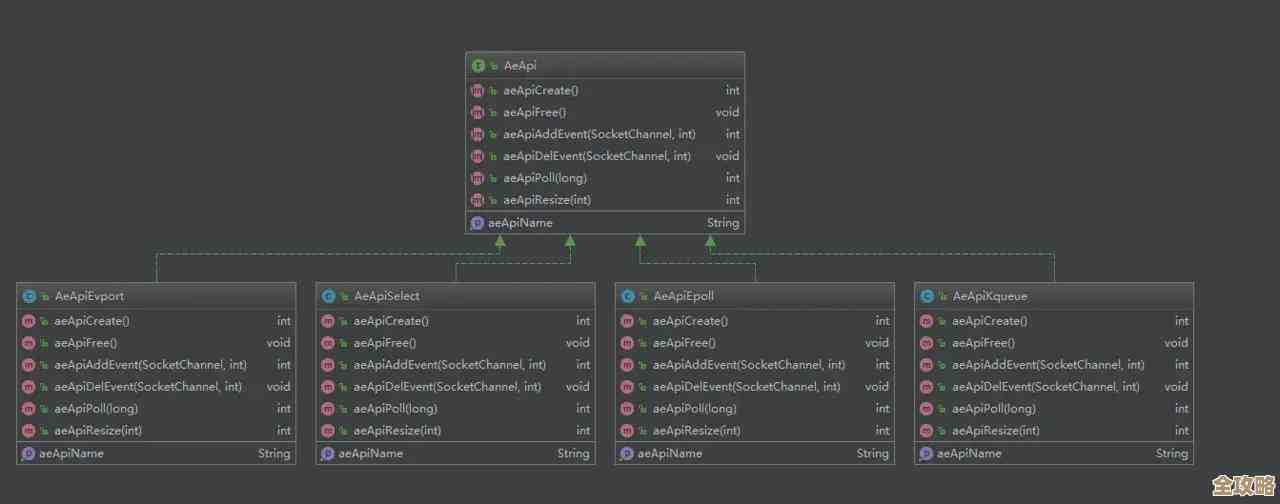
Redis槽的数据容量到底有多大,限制在哪儿?浅析和一些思考

(引用来源:Redis官方文档关于集群的说明,以及一些技术社区如Stack Overflow、中文技术博客上的相关讨论)
Redis槽的数据容量到底有多大,限制在哪儿?这个问题看似简单,但其实背后涉及到Redis集群的设计理念,咱们不用那些难懂的术语,就用人话把它捋清楚。
最核心的一个数字是:16384,这个数字就是Redis集群中“槽”的总数,你可以把Redis集群想象成一个有16384个抽屉的大柜子,当你存一个数据的时候,Redis会根据这个数据的键(Key)算出一个值,就像一把钥匙,这个钥匙能且只能打开其中一个抽屉,然后这个数据就被放进对应的抽屉里,整个集群的所有数据,就是被这样均匀地(理论上)分配到这16384个抽屉里的。

第一个问题来了:为什么是16384个?为什么不是更多,比如65536个?
这主要是出于网络通信的考虑。(引用来源:Redis作者Salvatore Sanfilippo在GitHub上的解释)在Redis集群中,每个节点都需要知道其他所有节点负责管理哪些槽,它们通过一种叫“心跳包”的消息定期互相通知,这个心跳包里就包含了一个“位图”信息,用来表示自己负责哪些槽,位图可以理解为一个很长的二进制串,每一位代表一个槽,如果是1就表示这个槽归我管,是0就表示不归我管。
如果槽的数量是16384个,那么这个位图的大小就是16384位,也就是2048个字节(2KB),如果槽的数量是65536个,位图大小就会变成8192字节(8KB),虽然看起来8KB也不大,但Redis集群要求每秒都要在节点之间发送多次这样的心跳包,当集群节点数量很多时(比如上千个),这些心跳包带来的网络流量就会变得不可忽视,为了在集群规模和网络开销之间取得一个很好的平衡,作者最终选择了16384这个数,他认为这个数量级,即使对于有上千个节点的超大集群来说,网络压力也是可以接受的。

现在说回“数据容量”的问题。一个槽能放多少数据?
答案是:一个槽本身没有固定的、明确的数据大小限制。 限制其实不在“槽”这个逻辑概念上,而在负责管理这个槽的“Redis节点”的物理内存上。
还是用抽屉的比喻,16384个抽屉分布在一个由多个小柜子(Redis节点)组成的大柜子(Redis集群)里,比如你有三个小柜子A、B、C,那么可能抽屉1-5000归A管,5001-10000归B管,10001-16384归C管,每个小柜子(节点)的容量是有限的,比如它的内存是16GB,分配给这个小柜子的所有抽屉(槽)里存放的数据总量,就不能超过16GB。

真正的限制是:单个Redis实例(节点)的最大可用内存。 这是Redis集群数据容量的真正瓶颈,如果你想扩大整个集群的总容量,办法不是去增加槽的数量(这个数是固定的),而是增加节点的数量,把槽重新分配一下,让更多的机器来分担数据存储的压力。
这就引出了另一个重要的思考:数据分布的均匀性至关重要。
因为槽的数量是固定的,所以数据的分布完全依赖于那个计算钥匙的算法(CRC16校验和),理想情况下,数据应该非常均匀地散列到16384个槽里,但如果你的键(Key)设计得不好,比如大量使用非常相似的键(例如user:001, user:002...),并且算法导致它们都被集中映射到了某几个槽,那么就会出现“数据倾斜”,即使整个集群总内存绰绰有余,但管理着那几个热门槽的节点会因为数据太多而内存爆满,其他节点却还很空闲,这就好比大部分东西都塞进了同一个抽屉,导致那个小柜子快被撑破了,而其他小柜子却空荡荡的,键的设计和集群的健康监控非常重要。
- 槽的数量限制:固定为16384个,主要是为了平衡集群节点间通信的网络开销。
- 槽的数据容量限制:槽本身无限制,限制在于承载该槽的Redis节点的物理内存大小。
- 扩大容量的方法:通过增加集群节点数量,将槽重新分配,实现水平扩展。
- 关键风险点:数据倾斜,如果数据不能均匀分布在各个槽上,会导致单个节点成为瓶颈。
谈论Redis槽的容量,不能脱离具体的集群节点配置和数据分布情况,它不是一个孤立的数字游戏,而是一个涉及网络、内存、数据设计等多个因素的系统性工程问题。
(引用来源:综合自对Redis集群原理的理解以及上述技术社区的实际问题讨论)
本文由芮以莲于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/72214.html