分布式Redis集群搭建那些坑和难点,面试时怎么聊才不慌

说到分布式Redis集群的搭建,尤其是在面试的时候被问到,很多人会觉得心里没底,因为这里面确实有不少实际操作中才会遇到的“坑”和需要深入理解的难点,你不能只停留在“我知道主从复制和分片”这种表面概念,得能说出点实实在在的东西,下面我就根据一些技术社区像知乎、CSDN上很多工程师分享的经验,以及《Redis设计与实现》这本书里提到的一些原理,来聊聊怎么聊才能不慌。
第一点,得先搞清楚为啥要用集群,别一上来就谈技术细节。 你可以从单机Redis的瓶颈开始聊,单机内存不够了怎么办?一台机器挂了服务就全停了怎么办?读写压力太大一台机器扛不住怎么办?这样聊显得你思考问题是从实际业务需求出发的,而不是死记硬背概念,这时候再引出集群的目标:高可用(挂了有备份顶上去)、高并发(数据分开放,大家一起扛压力)、海量数据存储(一台存不下就多台一起存),这样开场,逻辑就很顺。
就可以切入核心难点了,第一个大坑就是“数据分片”的策略和带来的问题。 你不能只说“用哈希分片”,这太笼统了,面试官想听的是你理解其中的麻烦,最常见的取模哈希,一旦集群节点数变了(比如增加或减少机器),会导致绝大部分数据都找不到,缓存雪崩,服务基本就瘫痪了,这时候你再引出Redis Cluster用的那种一致性哈希的变体——哈希槽(Hash Slot)的概念,关键是要解释清楚哈希槽为什么好:它把16384个槽分配给节点,节点变更时,只需要移动一部分槽和数据,而不是全部重新洗牌,影响面小得多,但这里也有坑,你得提到“数据迁移”过程中的问题:比如在迁移一个键的过程中,客户端同时访问这个键,该怎么处理?Redis Cluster的做法是,如果数据还在旧节点,旧节点处理,但会返回一个“重定向”信息告诉客户端去新节点找,这可能会增加一点延迟,如果你能聊到这个细节,就显得你很懂。
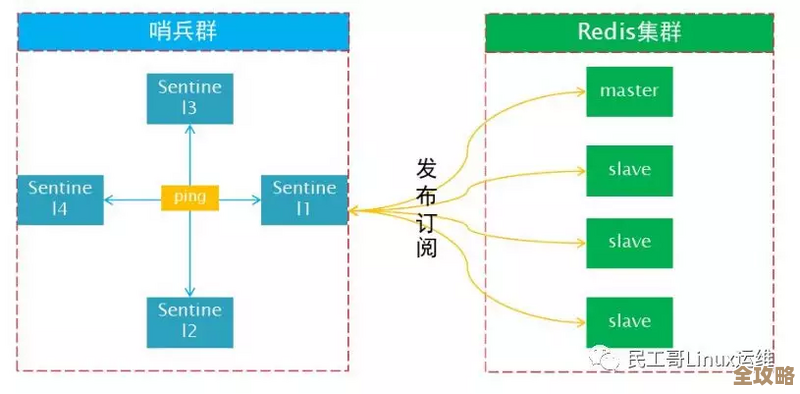
第二个难点,也是面试必问的,高可用”机制,也就是主从复制和故障切换(Failover)。 主从复制听起来简单,但坑不少,你搭好了主从,有没有遇到过从节点数据一直追不上主节点的情况?这就是复制延迟,你要聊到为什么会产生延迟:主节点写入太快,从节点是异步复制的,网络带宽又不够,就可能积压很多数据,更棘手的是脑裂问题:网络一抖动,哨兵(Sentinel)以为主节点挂了,选举了一个新主,结果旧主其实没挂,现在两个“主”同时存在,客户端往两个主节点写数据,数据就乱套了,你怎么避免?可以提到一些配置参数,比如最小从节点数量、主从延迟最大允许时间,让哨兵别太敏感,还有,故障切换时,怎么保证数据不丢?这又得提到Redis持久化策略(AOF和RDB)在其中的作用,以及它们各自的优缺点(比如AOF丢数据少但恢复慢,RDB快但可能丢一段时间的数据),把这些点串起来聊,说明你不仅知道有高可用,还深入思考过它如何能真正做到“高”和“可用”。
第三个常被忽略但很重要的点是“集群管理和运维的复杂性”。 搭建起来只是第一步,扩缩容怎么做?增加一个节点,如何把一部分哈希槽和数据平滑地迁移过去,同时保证服务不中断?这需要用到专门的工具(比如redis-trib.rb或新版redis-cli的集群管理命令),而且操作顺序很有讲究,一不小心就可能出问题,再比如,监控怎么做?集群这么多节点,你得监控每个节点的内存使用率、CPU负载、网络流量、慢查询吧?还有,备份和恢复,集群环境下比单机复杂多了,你得有个统一的方案,如果你能提到这些运维层面的挑战,并说说你了解过的工具(如Prometheus监控Redis指标)或最佳实践,面试官会觉得你是有实际经验或者有很强学习意识的。
聊到客户端。 很多人以为服务端搭好就万事大吉,其实客户端配置不对,照样白搭,你要提到客户端需要支持集群协议,它需要能缓存一份哈希槽的映射关系,并且能在收到服务端的重定向命令(比如MOVED、ASK错误)时,自动更新配置并重试请求,如果客户端不支持或者配置错误,就会一直报错。
面试时聊分布式Redis集群,别干巴巴地背概念,要从问题出发(单机瓶颈),讲到解决方案(集群架构),再重点剖析解决方案带来的新问题(分片迁移、脑裂、运维复杂等),最后落到实际应用(客户端配置、监控),这样聊下来,层次分明,既展示了你的知识广度,也体现了思考深度,自然就不会慌了,证明你不仅“知道”,理解”了这些技术。

本文由邝冷亦于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73193.html