Redis架构图细节全拆解,带你一步步看懂Redis内部结构和工作原理

Redis架构图细节全拆解,带你一步步看懂Redis内部结构和工作原理
我们可以把Redis想象成一个超级高效、功能多样的“内存数据仓库”,要理解它,最好的办法就是画一张架构图,然后从外到内、从上到下一层层拆解。
第一层:客户端与网络接口 (引用来源:普遍共识的Redis客户端-服务器模型) Redis的工作模式非常经典,就像一个餐厅,你(客户端)想点餐(发送命令),点一份红烧肉(set key value)”,你不是直接进厨房操作,而是通过服务员(网络接口)来传达,Redis启动后,会监听一个端口(默认6379),等待四面八方客户端的连接,这些客户端可以是各种语言写的程序,它们通过TCP协议和Redis建立一条“专属通道”,当命令发送过来时,Redis的网络事件处理器(一个叫Reactor的模式)会像餐厅的接待员一样,快速接待你,把你的点餐请求收下来,然后转交给后厨(核心逻辑处理层)去处理,这个过程非常快,因为它使用了I/O多路复用技术(可以理解为一个服务员能同时照看很多桌客人,而不是一个服务员只服务一桌),所以即使有成千上万的客户端同时连接,Redis也能高效应对。
第二层:核心逻辑与数据结构 (引用来源:对Redis官方文档中数据类型的解读) 服务员把你的命令(set name ‘张三’”)交给了后厨,后厨就是Redis的核心模块,它负责解析和执行命令,Redis之所以能支持字符串(String)、列表(List)、哈希(Hash)、集合(Set)等不同“菜系”(数据类型),是因为它在内部为每种类型设计了不同的“厨具”和“存储方式”。
- 字符串(String):最简单的类型,就像一个小碗,里面直接放上数据,但Redis对它做了优化,比如会根据字符串的长度决定是用一个简单的结构(embstr)还是复杂一点的结构(raw)来存,目的是节省内存。
- 列表(List):相当于一个排队通道,Redis底层用叫“快速链表”(quicklist)的结构实现,可以理解为把很多个小链表像火车车厢一样连接起来,这样在头尾插入删除元素很快,也兼顾了中间部分操作的效率。
- 哈希(Hash):像一个档案柜,里面有很多抽屉(字段),Redis底层用两种结构:当字段少时,用一种类似二维数组的“压缩列表”(ziplist,一种紧凑的、节省内存的结构)来存,查找很快;当字段多了以后,就自动升级成标准的“哈希表”(hashtable),保证即使数据量大,查找速度也依然飞快。
- 集合(Set):像一个不允许重复的储物筐,底层也是两种实现:整数集合(intset)或哈希表,当集合里全是整数且元素不多时,用整数集合非常省地方;否则就用哈希表(只用了key,value设为空)。
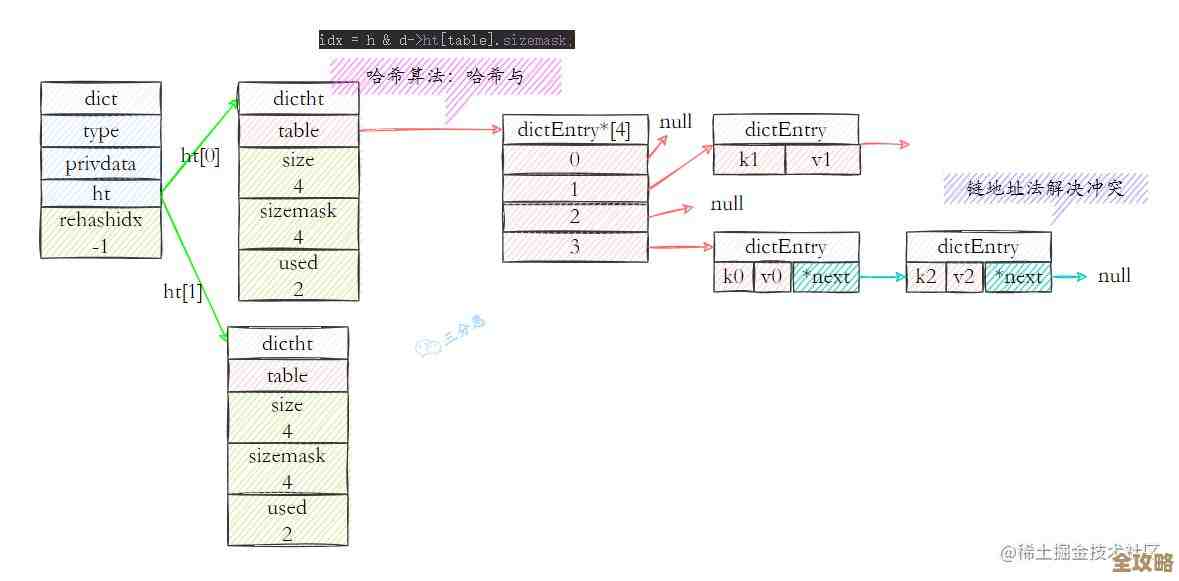
- 有序集合(ZSet):这是Redis的特色功能,像带分数的排行榜,它同时使用了“跳跃表”(skiplist)和“哈希表”两种数据结构,哈希表用于快速根据成员名查找对应的分数(O(1)时间复杂度),而跳跃表则用于维持成员的排序,支持按分数范围快速查找,这相当于你既可以通过名字快速找到一个人的成绩,又可以快速列出成绩在90分到100分之间的所有人。
第三层:持久化层 - 数据如何不丢失 (引用来源:对Redis持久化机制RDB和AOF的常见解析) 内存中的数据一旦断电就会消失,Redis为了防止数据丢失,设计了两个“账本”来把内存中的数据写到硬盘上,这就是持久化。
- RDB(快照):就像给整个仓库的数据拍一张全景照片(Snapshot),然后存盘,这个过程可以定时执行,也可以手动触发,执行时,Redis会fork出一个子进程,由子进程负责将当前数据状态写入一个压缩的二进制文件(dump.rdb),优点是恢复大数据集时速度很快,文件也很紧凑,缺点是可能会丢失最后一次快照之后的数据。
- AOF(追加日志):更像一个流水账本,它会把每一个修改数据的命令都记录下来,写入一个文件(appendonly.aof),当Redis重启时,会重新执行一遍这个文件里的所有命令,从而恢复数据,AOF的持久化更安全,可以配置为每秒同步一次,甚至每条命令都同步,最大限度减少数据丢失,但AOF文件通常比RDB文件大,恢复速度也慢一些。 在实际生产中,通常两者会结合使用,用AOF来保证数据安全,用RDB来做冷备份或快速恢复。
第四层:高可用与扩展层 (引用来源:对Redis主从复制、哨兵、集群模式的普遍描述) 单台Redis服务器能力有限,也会存在单点故障风险,所以Redis提供了集群方案。
- 主从复制(Replication):就是搞一个主仓库(Master)和几个从仓库(Slave),主仓库负责写操作,然后把写命令同步给从仓库,从仓库负责读操作,这样实现了读写分离和数据的备份,如果主仓库坏了,需要手动把某个从仓库切换成主仓库。
- 哨兵(Sentinel):为了解决手动切换的麻烦,Redis提供了“哨兵”机制,哨兵是一个独立的进程,它不提供服务,只负责“盯梢”主从仓库的健康状况,一旦发现主仓库宕机,哨兵们会自动协商,选举出一个新的主仓库,并通知客户端切换连接,实现了高可用。
- 集群(Cluster):当数据量巨大,一台机器内存装不下时,就需要分片(Sharding),Redis集群通过一种叫“哈希槽”(hash slot)的机制,把整个数据空间分成16384个槽位,每个节点负责一部分槽位,客户端请求时,会根据key计算它属于哪个槽,然后被定向到正确的节点上,这样就把数据和压力分散到了多台机器上,实现了横向扩展。
通过这样从外到内的拆解,我们可以看到Redis的架构是一个层层递进、分工明确的整体,从高效的网络处理,到丰富多样的内存数据结构,再到可靠的数据持久化机制,最后是保证服务不宕机、数据存得下的高可用和集群方案,共同构成了Redis这个高性能的键值数据库。

本文由盘雅霜于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73501.html