Redis怎么搞强一致性和幂等,解决重复操作那些事儿

我们需要理解为什么需要解决这两个问题,在分布式系统,比如电商下单、支付、或者任何用户点了按钮可能会因为网络问题重复提交的场景里,经常会出现同一个请求被处理多次的情况,这会导致严重的问题,比如重复扣款、商品超卖等,强一致性和幂等性就是用来对付这些麻烦事儿的。
强一致性 的目标是让系统表现得像单机一样,数据在任何时刻、任何节点上看起来都是一致的,但这在分布式系统中非常难,尤其是对于像Redis这样天生为速度而牺牲部分一致性的内存数据库来说,是个巨大的挑战,而幂等性 的意思更直接一些:无论同一个操作被执行一次还是多次,产生的结果都应该和只执行一次是一样的,支付接口设计成幂等的,用户即使因为网络延迟重复点了付款,也只会成功扣款一次。
Redis自己怎么搞呢?我们分开来说。
用Redis实现幂等性,防止重复操作
这是Redis最擅长也最常用的场景,核心思想是:在执行业务逻辑之前,先设置一个“标记”,如果标记已存在,就说明这个操作已经做过了,直接跳过。
最常用的工具是SETNX命令(SET if Not eXists),它的作用是只有当这个键不存在时,才设置它的值,如果键已经存在,命令就什么都不做。
一个典型的流程是这样的:
- 生成唯一标识符:客户端在发起请求时,需要生成一个全局唯一的请求ID(比如UUID),这个ID要跟着请求一起传到服务端。
- 尝试“占坑”:服务端在处理请求的核心逻辑(比如扣减库存、创建订单)之前,先执行一个Redis命令:
SETNX request_id:你的唯一ID 1,这里的键名可以自定义,idempotent:order:123456。 - 判断结果:
- 如果
SETNX返回1,恭喜你,说明这个请求ID是第一次出现,“坑”占成功了,你可以安心地去执行后续的业务逻辑,比如操作数据库。 - 如果
SETNX返回0,那就说明这个请求ID已经存在了,意味着同一个请求之前已经被处理过,服务端应该直接返回上一次处理的结果,而不再执行任何业务逻辑。
- 如果
- 设置过期时间:为了防止这个“标记”键在Redis中无限期地堆积下去,占用内存,我们通常会在设置成功后给它加一个过期时间,可以用
EXPIRE命令,或者更直接地用SET命令的扩展参数一步到位:SET request_id:你的唯一ID 1 EX 3600 NX,这条命令的意思是,只有键不存在时才设置,并且设置过期时间为3600秒。
通过这个简单的机制,我们就能确保即使客户端因为超时重试等原因发送了多次相同请求,服务端也只会实实在在地处理一次,这是一种非常有效且轻量级的实现幂等性的方法。
挑战Redis的强一致性
如前所述,让Redis自身实现跨数据中心的强一致性非常困难,但我们可以通过一些架构设计和结合其他工具,在特定场景下达到类似强一致的效果,或者满足业务上的强一致需求。
-
使用Redis事务(Multi/Exec): Redis支持简单的事务,通过
MULTI开始,将多个命令打包,然后用EXEC一起执行,这能保证这些命令会按顺序地、不被其他命令打断地执行(隔离性)。这并非真正的ACID事务,它不提供回滚机制——如果在EXEC前命令有语法错误,整个事务会都不执行;但如果在EXEC时发生错误(比如对错误的数据类型进行操作),只有那条命令会失败,其他命令依然会执行,所以它主要用于保证一批命令的原子性执行,对解决复杂的一致性场景帮助有限。 -
使用Redis Lua脚本: 这是比事务更推荐的方式,你可以把一系列复杂的Redis操作写在一个Lua脚本里,Redis会保证这个Lua脚本在执行时是原子性的,在执行过程中不会被其他命令插入,这非常适合用来实现复杂的判断逻辑,比如经典的“秒杀扣库存”场景:
local stock = tonumber(redis.call('GET', KEYS[1])) if stock and stock > 0 then redis.call('DECR', KEYS[1]) return 1 -- 扣减成功 else return 0 -- 库存不足 end这个脚本能确保检查和扣减这两个动作是连续、原子完成的,不会出现超卖,这在单Redis实例下,可以认为是一种“强一致”的操作。
-
结合数据库实现最终一致性: 这是更普适的方案,Redis通常作为缓存,其数据的权威来源(System of Record)还是背后的关系型数据库(如MySQL)或其它持久化数据库,我们可以采用一种“双写”或“基于日志(如MySQL Binlog)同步”的策略。
- 思路:所有数据的写请求都先落到具备强一致性事务能力的数据库中,通过数据库的binlog监听(例如使用Canal、Debezium等工具),近乎实时地将数据变更同步到Redis中。
- 优点:这样保证了数据的权威性在数据库,Redis只是一个高速缓存,即使Redis数据暂时不一致,最终也会通过同步机制变得一致(最终一致性),对于大多数业务,只要保证数据库是强一致的,并且缓存最终会同步,业务上就是可接受的。
-
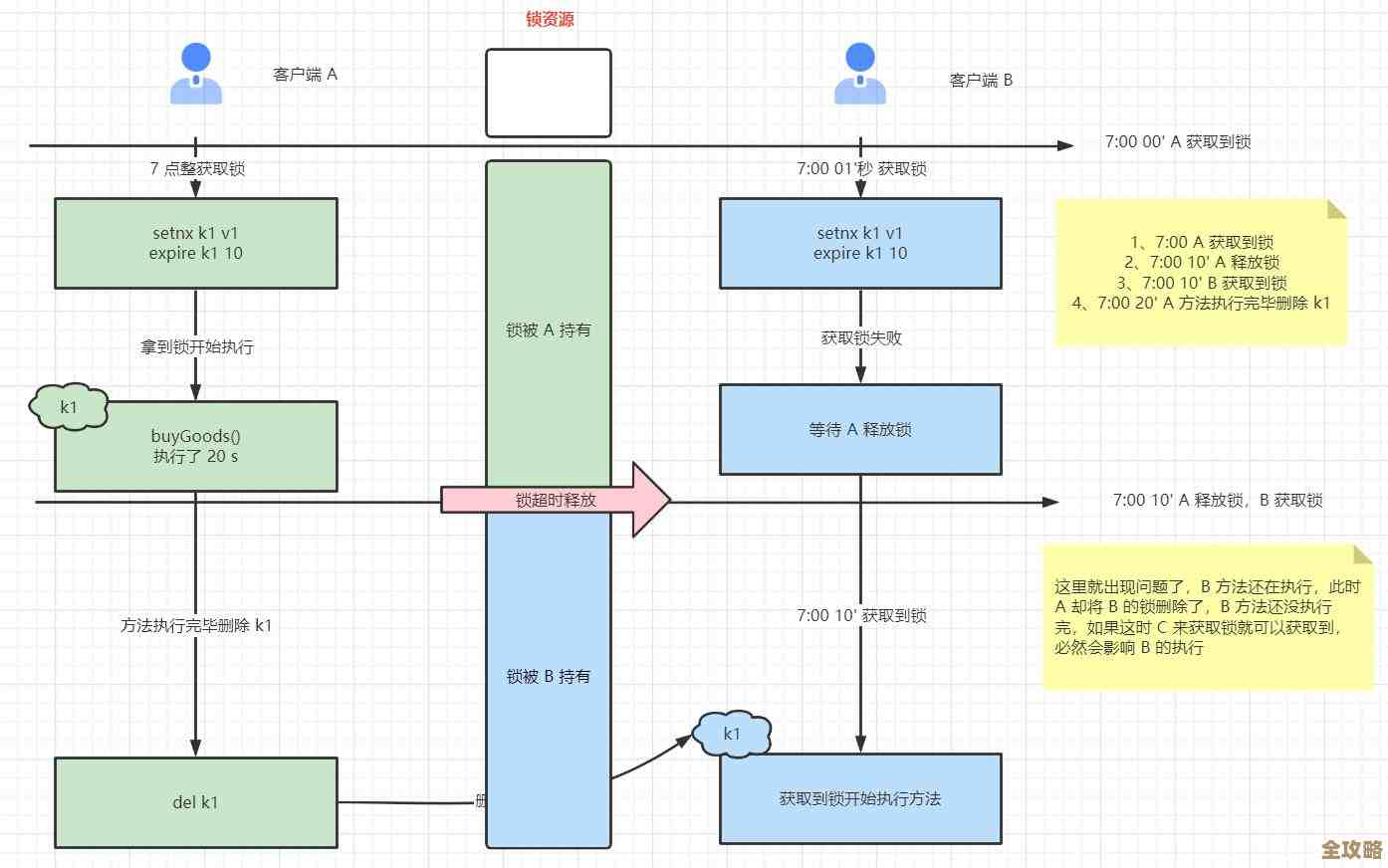
使用Redlock算法实现分布式锁: 当你的操作不仅仅涉及Redis,还需要跨多个服务或数据库时,为了保证在分布式环境下同一时间只有一个服务能执行某段关键代码(库存检查->创建订单->支付”这个完整流程),就需要分布式锁,Redis官方提出了Redlock算法,通过在不同Redis主节点上独立地获取锁,来实现在整个分布式系统中的互斥访问,这为构建更上层的强一致性业务逻辑提供了基础,Redlock本身在学术界有争议,需要谨慎使用并在生产环境中充分测试。
总结一下:
- 解决重复操作(幂等性),用
SETNX加唯一请求ID是简单有效的“银弹”。 - 实现强一致性,对Redis本身是巨大挑战,在单实例内,可以用Lua脚本保证多个命令的原子性,在更大范围的分布式系统中,更务实的做法是承认Redis的定位,将其与具备强一致性能力的数据库(如MySQL)结合,让数据库作为真相的来源,Redis作为性能的加速器,通过数据同步来实现业务的最终一致性目标,试图让Redis在所有场景下都做到强一致性,往往是吃力不讨好的。

本文由歧云亭于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73629.html