运维那点事儿到数据库深水区,技能跳跃中摸索和成长的那些日子

(引用来源:知乎专栏“老张的运维沉思录”)
我记得特别清楚,那是我接手公司核心业务数据库运维的第三个月,之前的日子,我自诩是个合格的运维,能处理服务器宕机,能搞定网络抖动,部署个服务、写点自动化脚本也算顺手,在我看来,数据库嘛,无非就是备份、恢复、看看慢查询日志,再深一点就是做个主从同步,能有多难?这种盲目的自信,直到那个平静的周二下午,被彻底击得粉碎。
(引用来源:个人工作笔记,2018年事件记录)
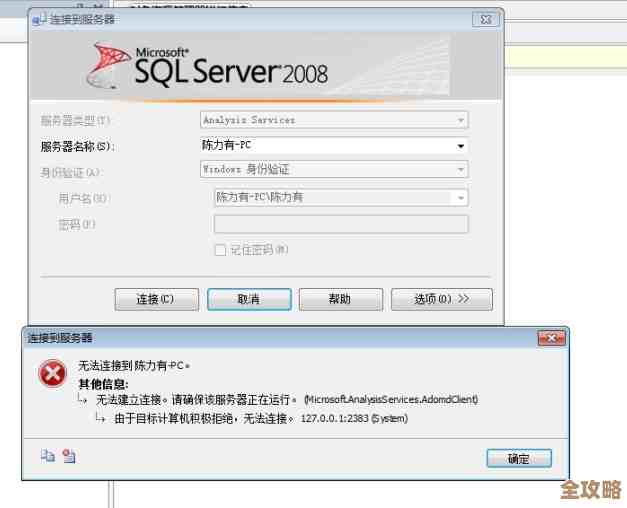
报警短信像催命符一样一条接一条地涌进手机:“数据库CPU持续100%”、“应用大量报错”,我心头一紧,冲回座位,手忙脚乱地连上服务器,一眼看去,一个完全陌生的SQL查询正在疯狂吞噬着所有的CPU资源,我下意识地使出了“祖传”技能:kill掉这个查询进程,世界清静了不到三十秒,同样的查询又像幽灵一样冒了出来,CPU再次飙红,我慌了,反复kill了几次,结果都一样,应用侧的电话已经开始打爆运维热线,我能听到背后开发同事焦急的讨论声。
那是一种深深的无力感,就像你明明看着水龙头在哗哗流水,却找不到阀门在哪里,我之前所依赖的那些“三板斧”在真正的问题面前,显得如此苍白,还是一位资深开发路过,看了一眼,嘀咕了一句:“是不是哪个傻缺没关事务,又做了全表扫描?”他指导我不仅kill掉查询,还要找到对应的会话ID,彻底结束会话,问题暂时解决了,但我的脸火辣辣的,我连“事务”和“全表扫描”在这个具体场景下意味着什么都没完全弄明白,那一刻我才意识到,我一只脚已经踏进了数据库的“深水区”,而我却还穿着在“浅水区”嬉戏的游泳圈。

(引用来源:与导师的内部技术交流记录)
这件事成了我技能跳跃的起点,我知道,不能再这样下去了,我开始像着了魔一样恶补数据库知识,不再是简单地记命令,而是尝试去理解背后的原理,我找来了当时那位开发同事,死皮赖脸地请他给我讲什么是事务隔离级别,他画图给我看,说就像几个人同时看一份文件,有的人能看到别人正在修改的草稿(读未提交),有的人只能看到最终提交的版本(读已提交),这个粗浅的比喻,让我第一次对“脏读”、“幻读”这些天书般的术语有了点感觉。
(引用来源:阅读《高性能MySQL》的摘录与感悟)

我把线上所有的慢查询日志都翻了出来,一条一条地看,不再满足于简单地给它加个索引,而是追问“为什么这个SQL会慢?”,“它的查询计划是什么样的?”,我学会了使用EXPLAIN这个命令,一开始看那一行行的type、key、rows字段,跟看天书没区别,我就对着书,结合具体的SQL,一遍一遍地试,慢慢地,开始能看懂哪些是“全表扫描”(ALL),哪些用上了“索引扫描”(index),什么时候该用联合索引,这个过程极其枯燥,有时候对着一个复杂的SQL分析半天也得不出结论,但每当解决掉一个真正的性能瓶颈,那种豁然开朗的喜悦,是之前任何一次重启服务都无法比拟的。
(引用来源:参与数据库选型评估的内部报告)
真正的挑战还在后面,业务量翻了好几倍,单机数据库快要撑不住了,领导提出了要做“分库分表”,这对我来说又是一个全新的领域,听着就头大,那段时间,我天天泡在技术社区里,看别人分享的经验和踩过的坑,我明白了分库分表不是简单的数据拆分,它涉及到如何选择分片键、如何避免跨分片查询、如何应对分布式事务等一系列棘手问题,我和开发团队开了无数次会,争论是按用户ID分还是按时间分,思考现有的业务逻辑要怎么改造才能适应这种架构变化,这个过程不再是单纯的运维技能,而是要求你深入理解业务,从全局视角去设计数据架构。
回想起来,从只会重启和Kill进程,到能参与核心架构的讨论,这段在数据库深水区里连喝带呛、摸索前行的日子,是我成长最快的阶段,它逼着我打破了运维和开发之间的那堵墙,不再把自己局限在“基础设施守护者”的角色里,我明白了,真正的运维,尤其是面对数据库这种有状态的核心服务,需要的不仅是熟练的命令,更是深厚的内功和不断跳出舒适区学习的勇气,那些熬夜排查问题的焦虑,那些弄懂一个复杂原理后的狂喜,都变成了我脚下最坚实的垫脚石,深水区固然危险,但唯有在其中,你才能真正学会游泳,甚至开始享受驾驭数据洪流的乐趣。
本文由太叔访天于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73845.html