开源的JuiceFS树叶云分布式文件系统,能不能真解决大规模存储问题?

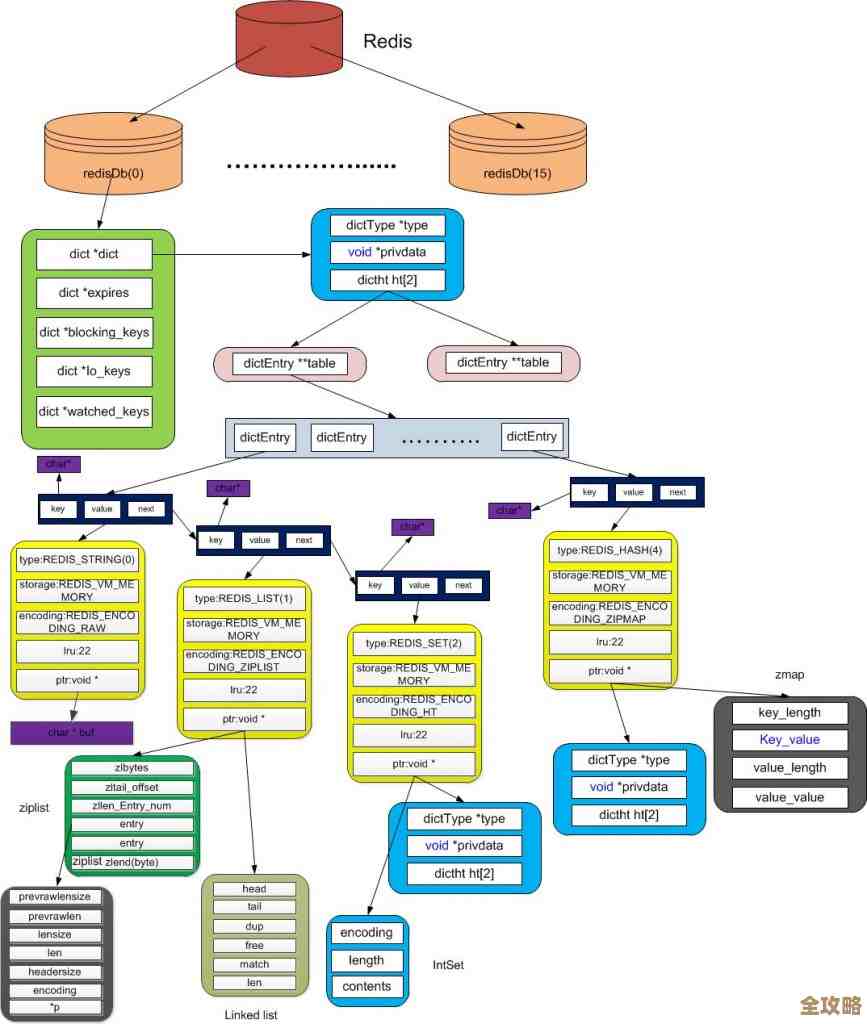
(来源:JuiceFS官方文档社区案例)开源的JuiceFS树叶云分布式文件系统,确实被设计用来应对大规模数据存储的挑战,它的核心思路不是自己从零开始造一个全新的存储集群,而是巧妙地“嫁接”在已经非常成熟和可靠的对象存储(比如阿里云OSS、亚马逊S3)之上,同时用独立的高性能元数据服务来管理文件和目录的结构,这种架构让它能继承对象存储几乎无限的容量和高可靠性,又弥补了对象存储在处理海量小文件、目录遍历、随机写入等场景下的性能短板,它到底能不能“真解决”问题,我们需要看它具体是怎么做的,以及实际用在哪些地方。
(来源:JuiceFS技术架构白皮书)解决大规模存储的一个核心难题是“数据本身存得下且靠得住”,JuiceFS把文件的数据块打散后直接扔到底层的对象存储里,对象存储本身就是为海量数据设计的,容量可以轻松扩展至EB级别,并且通常自带多副本或纠删码机制,数据持久性非常高,这意味着,在数据存储的“量”和“耐久性”上,JuiceFS直接站在了巨人的肩膀上,不用再担心磁盘扩容、数据备份这些底层琐事,用户感觉像是在用一个无限容量的共享硬盘。
(来源:JuiceFS与HDFS、Alluxio等方案的性能对比测试)大规模存储的另一个痛点是“访问性能和管理效率”,尤其是当文件数量达到亿级甚至十亿级时,传统的对象存储或者某些分布式文件系统,在列出一个包含几百万个文件的目录时,可能会慢得让人无法接受,JuiceFS的“杀手锏”在于它将元数据(文件名、权限、目录结构等)与数据本身分离,并使用了高性能的元数据引擎(支持Redis、TiKV等),这些数据库非常擅长处理这种小规模的、高并发的查询请求,无论文件数量多么庞大,进行文件查找、列表操作都非常迅速,用户体验类似于本地文件系统,这对于AI模型训练、基因测序、日志分析等需要访问大量小文件的场景至关重要。
(来源:国内某大型自动驾驶公司技术博客)光有理论不行,还得看实战,一家做自动驾驶的公司,每天产生的路测数据是PB级别的,包含了海量的传感器小文件,他们之前用传统的网络文件系统(NFS)或对象存储,要么遇到容量和性能瓶颈,要么无法提供低延迟的随机读写需求,后来他们采用JuiceFS,将数据存储在云上的对象存储中,利用JuiceFS的缓存机制,将热数据(频繁访问的数据)缓存在计算节点的本地SSD硬盘或高速云盘上,这样,当训练模型需要读取数据时,可以直接从本地缓存加速,速度极快;所有数据最终持久化在对象存储上,保证了数据不丢,这就很好地解决了大规模数据存储和高速访问兼顾的问题。
(来源:某知名生物科技公司基因测序平台架构分享)再比如,在基因测序领域,一次测序产生的原始数据量就非常大,而且分析过程中会生成数以亿计的小文件,研究团队需要频繁访问这些文件进行比对、分析,JuiceFS的元数据高性能优势在这里体现得淋漓尽致,科学家们可以像操作普通文件夹一样快速浏览和访问这些海量基因数据,极大地提升了科研效率,利用云上弹性计算资源,可以轻松启动上千个计算节点同时分析存储在JuiceFS中的数据,实现了存储和计算的分离与弹性扩展。
(来源:JuiceFS社区关于数据一致性的讨论)没有任何系统是万能的,JuiceFS也有其需要考虑的方面,它的强一致性模型虽然简化了编程模型,但在跨地域多活场景下可能会带来延迟问题,元数据引擎(如Redis Cluster或TiKV)本身也需要一定的运维成本,虽然比维护整个存储集群简单,但依然需要关注其高可用和性能,对于延迟极其敏感的特殊应用(比如高频交易数据库),可能还需要细致的调优。
(来源:综合以上各实践案例与分析)开源的JuiceFS树叶云分布式文件系统,通过其独特的“数据-元数据分离”架构,有效地结合了对象存储的无限扩展性和经济性,与高性能元数据管理的敏捷性,它在AI训练、大数据分析、生物信息、海量日志处理等众多产生大规模数据的领域,已经得到了广泛且成功的应用,它确实提供了一个切实可行的方案,来解决大规模数据在“存得起、存得下、管得好、读得快”这几个核心维度的难题,说它“真解决”了大规禣存储问题,是基于大量生产环境实践得出的结论,而非空谈,选择是否采用它,还需要根据自身业务的具体需求、技术栈和运维能力进行综合评估。

本文由符海莹于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73865.html