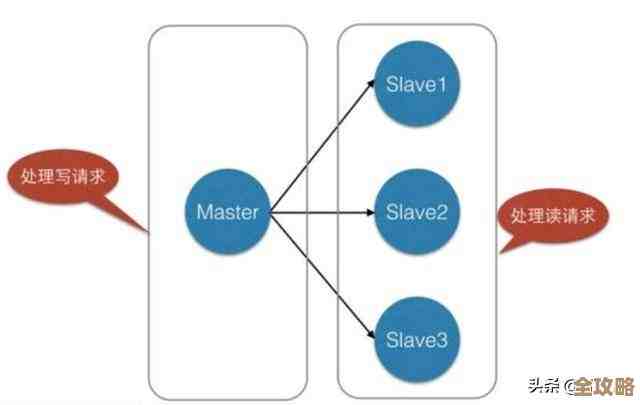
MySQL报错MY-010586,复制从库执行查询出错,远程修复思路分享

MySQL报错MY-010586,通常伴随着类似“Error executing row event”这样的信息,简单来说就是在主从复制架构中,从库在重放(也就是执行)主库传过来的数据变更时,失败了,这就像是一个认真的抄写员,在抄写主本的内容时,发现某个字不会写,或者发现要写的内容和纸上已有的内容对不上,于是卡住了,复制进程就会中断,而“从库执行查询出错”往往是导致这个报错的直接原因,这里的“查询”泛指那些从主库同步过来的INSERT、UPDATE、DELETE等数据变更操作。
当出现这个问题时,从库的数据已经和主库不一致了,由于是远程修复,我们无法直接接触服务器硬件,所有操作都需要通过命令行或者管理工具来完成,核心思路不是简单地“跳过”错误,而是要先搞清楚原因,再选择最安全的方法恢复复制,并尽可能保证数据的最终一致性,以下是一些按部就班的排查和修复思路。
第一步:立即检查复制状态,锁定错误详情
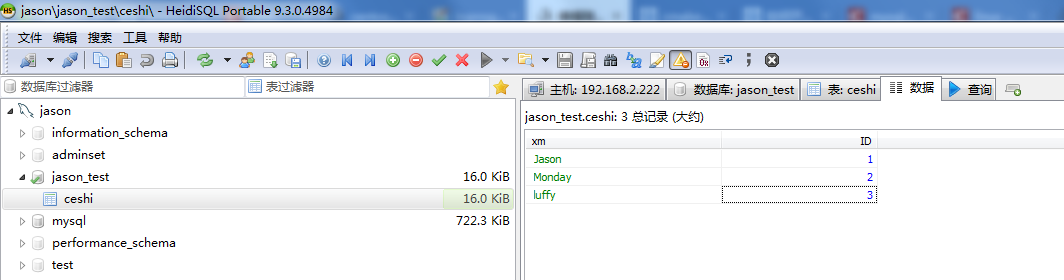
我们需要连接到出问题的从库数据库,执行命令查看详细的复制状态,最关键的SQL命令是 SHOW SLAVE STATUS\G,这个命令会返回非常多的信息,我们需要重点关注以下几项:

Slave_IO_Running:负责从主库读取日志的线程是否在运行,通常是Yes。Slave_SQL_Running:负责执行日志的SQL线程是否在运行,出错时这里很可能是No。Last_Errno:最后一次错误的编号,这里可能就是MY-010586相关的具体错误码。Last_Error:最后一次错误的详细描述信息,这是最重要的线索,它会告诉你具体是哪个SQL语句执行失败了,以及失败的原因,Duplicate entry '123' for key 'PRIMARY'”(主键123重复)或者“Cannot add or update a child row: a foreign key constraint fails”(外键约束失败)。Exec_Master_Log_Pos:当前从库执行到主库二进制日志文件(binlog)的哪个位置。
通过查看 Last_Error,我们就能知道“抄写员”到底卡在了哪里,这是所有后续操作的基石,这个步骤的参考依据是MySQL官方手册中关于复制故障排查的基础部分,任何DBA在遇到复制问题时都会首先执行这个操作。
第二步:根据具体错误原因,选择修复策略
知道了错误详情后,我们就可以对症下药了,常见的错误和应对方法有以下几种:
-
主键或唯一键冲突:错误信息中明确提示数据重复,这通常是因为之前有人为跳过错误或者从库曾被写入过数据导致的。比较谨慎的做法是:根据业务逻辑判断哪边的数据是正确的,如果确认主库的数据是权威的,我们可以选择跳过这条冲突数据,使用命令
STOP SLAVE;停止复制,然后执行SET GLOBAL sql_slave_skip_counter = 1;让从库跳过1个事件,再START SLAVE;重启复制,但这个方法要非常小心,跳过一个事件可能意味着丢失一个数据变更,需要评估业务影响,如果跳过后复制恢复正常,最好记录下跳过的位置,并通知业务方检查相关数据。
-
数据不存在(例如更新或删除时找不到行):这是因为从库缺少了某条记录,导致无法更新或删除,这种情况比数据冲突更麻烦。一种处理思路是:手动在从库上补录这条缺失的数据,我们需要从主库查询出这条记录的完整内容,然后在从库上执行INSERT操作,这要求操作者对表结构很熟悉,并且能通过错误信息定位到具体是哪条记录,手动补全数据后,再尝试重启复制,这个方法在技术社区如阿里云、腾讯云的帮助文档中常有提及,是一种针对性的数据修补方法。
-
外键约束失败:要插入或更新的数据违反了外键关系,这说明从库上关联表的数据已经不一致了。修复起来相对复杂,需要先检查关联表的数据差异,可能也需要手动介入,先在从库上补全被引用的父表记录,然后再处理子表,这种情况下,单纯跳过错误是不可取的,因为会破坏数据的完整性。
第三步:如果错误太多或原因不明,考虑重建从库
如果上述方法尝试后错误依然频繁出现,或者错误的根本原因很难快速定位(比如表结构曾经不一致),那么最彻底、也往往是最高效的远程修复方法就是:重建从库。

虽然听起来很耗时,但对于云上数据库或者有自动化脚本的环境,这其实是一个标准化操作,具体步骤是:
- 在从库上执行
STOP SLAVE;彻底停止复制。 - 使用
mysqldump或更快的物理备份工具(如Percona XtraBackup)从主库创建一个新的完整备份,需要注意的是,备份命令中要带上--master-data参数,这样备份文件里会记录下备份时主库的binlog位置点。 - 将备份文件传输到从库服务器。
- 清空从库上需要重建的数据库数据(操作前务必确认!),然后导入新的备份。
- 导入完成后,利用备份文件中的位置点信息,重新配置复制链路(
CHANGE MASTER TO ...),然后启动复制。
这样,从库就会从一个全新的、与主库一致的状态开始重新同步,这种方法虽然需要一定的停机时间(取决于数据量大小),但它能保证数据的纯净性,避免了因跳过错误可能积累的更多数据差异,许多公司的运维规范都将重建作为处理复杂复制错误的首选方案。
第四步:修复后的验证与预防
无论采用哪种方法修复,重启复制后,都必须持续监控 SHOW SLAVE STATUS 的输出,确保 Slave_SQL_Running 和 Slave_IO_Running 都是Yes,Seconds_Behind_Master(主从延迟)这个指标逐渐变为0,说明从库正在顺利追赶上主库。
修复问题固然重要,但预防更重要,应该建立监控告警,一旦复制发生中断就立即通知,严格规范数据库的访问权限,避免任何人在从库上直接进行写操作,这是导致数据不一致最常见的原因之一,定期检查主从数据的一致性,也可以使用像 pt-table-checksum 这样的工具来防患于未然,这些预防性措施在《高性能MySQL》等经典技术书籍中都被反复强调。
本文由称怜于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/75617.html