Redis缓存参数出错了,分析原因和怎么解决这些烦人的问题

Redis缓存出错,确实让人头疼,它本应是提升速度的利器,一旦闹起脾气,整个系统都可能被拖慢甚至瘫痪,这些问题虽然烦人,但大多有迹可循,下面我们来逐一分析常见错误的原因和解决方法。
最常见的错误:内存不足(Out of Memory)
这是最常碰到的“烦人精”,表现就是Redis突然不响应了,或者直接报错,原因很简单,就是数据把内存塞满了。
-
原因分析:
- 数据只增不减: 如果你的应用不停地往Redis里写数据(比如缓存了用户会话、热门帖子等),却从不删除过期或无用的数据,内存被撑爆是迟早的事。
- 单个Key过大: 比如把一个几十兆的大对象(如巨大的列表或集合)直接塞进一个Key里,当Redis操作这个Key时,可能会长时间阻塞,影响其他请求,而且在持久化或网络传输时也容易出问题。
- 内存碎片化: 频繁地写入和删除不同大小的数据,会导致内存中出现很多小碎片,虽然总内存还有剩余,但无法分配出一块连续的空间来存放新的大数据,也会触发内存不足。
-
解决方法:
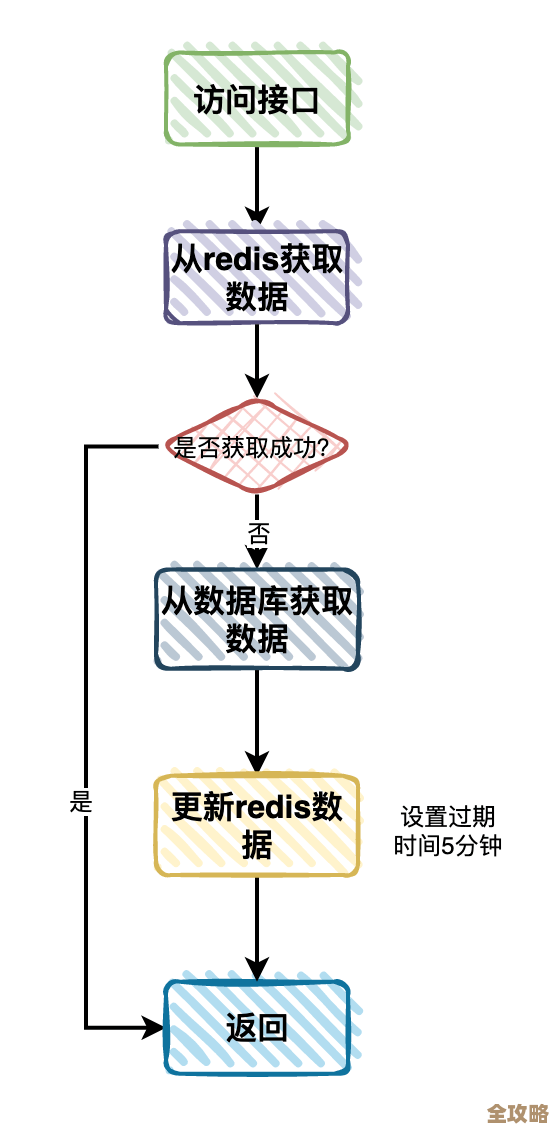
- 设置合理的过期时间(TTL): 这是最重要的预防措施,给绝大多数缓存数据都加上一个过期时间,让Redis可以自动清理,比如短信验证码缓存5分钟,热门文章列表缓存1小时。
- 使用淘汰策略(Eviction Policy): Redis提供了几种内存满时的淘汰策略,通过配置文件(如
redis.conf)中的maxmemory-policy设置,常用的有:volatile-lru:从设置了过期时间的Key中,淘汰最近最少使用的。allkeys-lru:从所有Key中,淘汰最近最少使用的,这是比较通用的选择。volatile-ttl:淘汰剩余过期时间最短的Key。 根据你的业务特点选择合适的策略,这相当于给Redis一个“清理指南”。
- 拆分大Key: 对于过大的单个Key,要把它拆分成多个小Key,比如一个存有百万条用户ID的集合,可以按ID范围拆成10个小的集合,这样可以避免单点阻塞,也利于分布式处理。
- 监控内存使用: 使用
info memory命令或监控工具,持续观察内存使用量和碎片率,如果碎片率(mem_fragmentation_ratio)过高(比如持续大于1.5),可以考虑重启Redis实例来重整内存(这是一剂猛药,需在低峰期进行)。
连接数爆满(Too Many Connections)
错误信息可能是“max number of clients reached”,这意味着Redis无法再接受新的客户端连接了。
-
原因分析:
- 连接池配置不当: 应用端的数据库连接池设置过大,或者连接没有正确释放(比如代码Bug导致连接泄漏),创建了远超Redis处理能力的连接。
- Redis最大连接数设置过低: Redis默认的最大连接数(
maxclients)是10000,但在某些高并发场景下可能不够用,或者被无意中设置了一个很小的值。 - 客户端异常: 大量客户端因为网络问题异常断开,但Redis服务端可能没有立刻感知到,导致一些“僵尸连接”占着名额。
-
解决方法:
- 检查并优化应用代码: 确保所有Redis操作都使用了连接池,并且每次操作后连接都能被正确返还到池中,这是解决连接泄漏的根本。
- 调整Redis最大连接数: 在
redis.conf文件中调整maxclients参数为一个合适的值,但要注意,每个连接都会占用少量内存,不能无限制调大。 - 检查闲置连接: 使用
client list命令查看所有连接的详情,重点关注idle(闲置时间)过长的连接,可以通过配置timeout参数,让Redis自动关闭闲置时间超过指定秒数的客户端连接。 - 使用更高效的命令: 比如用
mget、mset代替多个get、set,减少网络往返次数,间接降低对连接数的需求。
持久化导致的性能问题
Redis为了数据安全,提供了RDB(快照)和AOF(日志)两种持久化方式,但它们如果配置不当,会成为“性能杀手”。
-
原因分析:
- RDB快照阻塞: RDB是fork一个子进程来生成数据快照的,当数据量很大时,fork过程可能会主线程造成短暂的阻塞,如果服务器内存不足,阻塞时间会更长。
- AOF日志拖慢写入: AOF有不同刷盘策略,如果设置为
always(每个写命令都刷盘),数据最安全,但性能最差,每秒写入次数会急剧下降,如果AOF文件过大,重写过程(BGREWRITEAOF)也会消耗大量CPU和内存。
-
解决方法:
- 权衡持久化策略: 对于缓存场景,数据丢失一点可能没关系,可以设置
appendfsync everysec(每秒刷盘一次)甚至appendfsync no(由操作系统决定),这是性能和数据安全的良好折衷。 - 避免在大型实例上做持久化: 如果Redis实例内存占用很大(比如几十GB),fork操作的风险很高,可以考虑搭建Redis集群,将数据分片到多个小实例上,每个实例做持久化的压力就小多了。
- 监控磁盘IO: 确保Redis持久化所在的磁盘有足够的IOPS(每秒读写次数),避免磁盘成为瓶颈。
- 权衡持久化策略: 对于缓存场景,数据丢失一点可能没关系,可以设置
网络问题与慢查询
有时候问题不在Redis本身,而在网络或命令的使用上。
-
原因分析:
- 慢查询: 执行时间过长的命令会阻塞其他命令,常见的慢查询命令包括:对一个大集合进行
keys *操作(绝对禁止在生产环境使用!)、对大的Hash或Sorted Set进行全量读取等。 - 网络延迟或丢包: 应用服务器和Redis服务器之间的网络不稳定,导致超时。
- 慢查询: 执行时间过长的命令会阻塞其他命令,常见的慢查询命令包括:对一个大集合进行
-
解决方法:
- 使用
slowlog排查慢查询: 使用slowlog get命令查看慢查询日志,找到慢查询命令后,优化它,比如用scan命令代替keys,避免一次性获取过大的数据集合。 - 优化命令使用: 检查业务代码,避免在循环中频繁调用Redis,应该使用管道(pipeline)或批量操作命令。
- 检查网络状况: 使用
ping命令检查延迟,或通过系统工具(如traceroute)排查网络链路问题。
- 使用
解决Redis问题的核心思路是:
- 监控先行: 使用
info命令、slowlog命令和外部监控工具(如Prometheus+Grafana)对Redis的关键指标(内存、连接数、命令耗时等)进行持续监控,这样才能在问题发生前预警或快速定位。 - 配置优化: 根据业务场景精心调整
maxmemory-policy、maxclients、持久化策略等参数,而不是一味使用默认值。 - 代码规范: 编写健壮的应用代码,正确使用连接池,避免大Key、慢查询和连接泄漏。
这些烦人的问题虽然看起来五花八门,但只要我们系统地理解其背后的原理,就能化被动为主动,让Redis真正成为得心应手的性能加速器。

本文由帖慧艳于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/75622.html