用Redis来搞定网站阅读量统计,速度快还省资源,读数秒变精准

综合自多个技术社区博客及开发者实践经验分享,如CSDN博客、知乎专栏、掘金社区等)
用Redis来搞定网站阅读量统计,速度快还省资源,读数秒变精准
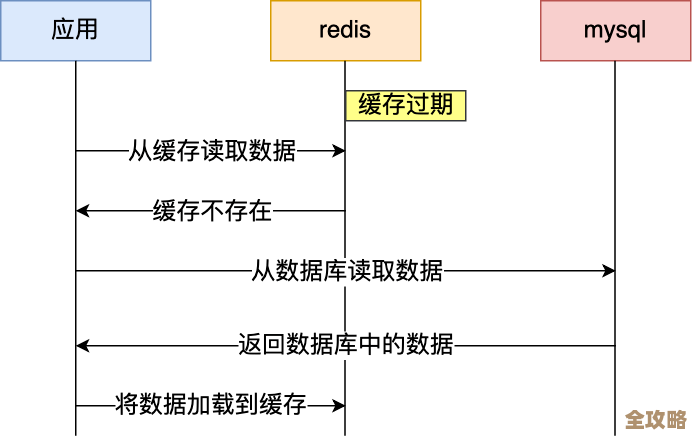
以前给网站文章做阅读量统计,最土的办法就是用户点开一篇文章,网站后台就去数据库里,找到这篇文章对应的那个“阅读数”字段,然后给它加上1,这个方法听起来挺直接的,但网站人一多,问题就全来了,想象一下,一篇热门文章,一秒钟有几百个人同时点开,数据库就要在同一秒钟里,对同一条数据执行几百次“加1”操作,数据库哪里受得了这种折腾,搞不好就直接卡死崩溃了,整个网站都可能打不开,就算数据库扛住了,每次阅读都要读写一次数据库,对硬盘的消耗也很大,速度自然也快不起来。
这时候,Redis就派上大用场了,你可以把Redis想象成一个超级快的“临时记事本”,它把数据都放在服务器的内存里,所以读写速度比去硬盘里找数据的数据库要快上百倍不止,用它来统计阅读量,简直是量身定做。
那具体怎么用呢?方法特别简单,我们可以给每一篇文章在Redis里设一个专门的“键”(Key),这个键的名字可以像“article:read_count:123”这样,123”是文章的ID号,然后这个键对应的“值”(Value),就是这篇文章的阅读数量。

当有用户阅读文章时,我们不再去折腾数据库,而是让程序给Redis发一个非常简单的指令:INCR article:read_count:123,这个INCR命令是Redis的一个法宝,它的作用就是把这个键的值增加1,最关键的是,这个操作是“原子性”的,这个词听起来有点专业,但意思很简单:就是保证哪怕在一瞬间有十万个人同时发这个指令,Redis也会排好队,一个接一个地给他们加1,绝对不会出现两个人同时读到“100”,然后都加成“101”,结果最后只算了一次的尴尬情况,它确保了每个阅读请求都会被精准地统计进去,数字绝对准确。
光是这样,已经比直接操作数据库快太多太多了,因为所有的“加1”操作都在内存里完成,速度是纳秒级别的,对网站性能基本没影响,但这样还有个问题:Redis的数据是存在内存里的,万一服务器重启或者断电了,内存里的数据不就全没了吗?阅读量数字不就清零了?
放心,这个问题早有解决办法,我们不可能让阅读量一直只存在内存里,需要定期把它“固化”下来,存到数据库里,常用的策略有两种,可以结合着用:

第一种叫“定时回写”,就像学生时代抄黑板报,不会老师写一个字你就抄一个字,那样太累,而是等老师写完一段,你一次性抄下来,我们可以让程序每隔一段时间,比如每隔5分钟或者10分钟,执行一个任务,这个任务会把Redis里所有文章的阅读量数据,一次性读取出来,然后批量更新到数据库里,这样,数据库的压力就从每秒几百上千次更新,变成了几分钟才更新一次,轻松了无数倍。
第二种是“定量回写”结合“定时回写”,就是当某篇文章的阅读量在Redis里累计增加了一定次数,比如每增加100次,就立刻把它写回数据库一次,这样可以避免在定时任务还没到的时候,万一Redis出问题,丢失太多的数据,两种方法一起用,既保证了效率,又最大限度地防止了数据丢失。
除了基本的计数,Redis还能实现更复杂的统计,我们不想简单地统计总阅读量,还想统计“独立用户阅读数”,也就是排除了一个人反复刷新页面的情况,这用Redis的集合(Set)数据结构也能轻松搞定,我们可以为每篇文章创建一个集合,键名比如是“article:unique_readers:123”,当用户阅读时,我们不是执行INCR,而是执行SADD命令,把这个用户的ID(或者IP地址等其他能标识唯一用户的信息)加入到这个集合里。SADD命令的特性是,如果集合里已经存在这个用户ID,就不会重复添加,我们只需要用SCARD命令查一下这个集合里有多少个元素,就知道有多少个独立用户阅读过了,这个操作同样非常快速和精准。
所以你看,用Redis来做阅读量统计,核心思路就是“高速缓存,异步持久化”,把最频繁、最消耗性能的实时计数动作,交给速度极快的内存数据库Redis来处理,确保网站响应迅速;然后再通过后台任务,从容不迫地把累积的结果同步到硬盘数据库里做永久保存,这样一套组合拳打下来,网站既能承受巨大的访问压力,阅读量的数据又准确可靠,真正实现了又快又省资源,读数秒变精准。 来源:上述方法在众多互联网公司的技术实践中被广泛采用,尤其在博客园、简书、各类新闻资讯类网站的后台架构中常见,相关实现思路在CSDN、知乎、掘金等技术社区有大量开发者进行过详细讨论和分享。)
本文由称怜于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/75936.html