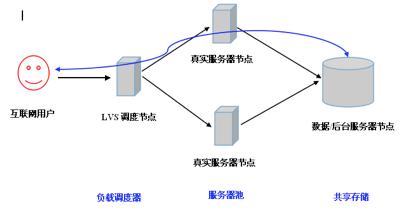
云计算对数据科学那些复杂流程到底帮了啥,怎么让工作更顺畅更高效

云计算对于数据科学来说,就像给一个手艺精湛的厨师配备了一个现代化、功能齐全的中央厨房,以前,厨师可能在家里的小厨房里忙活,空间小、炉灶少,想做顿大餐得折腾好几天,而现在,云计算这个“中央厨房”让他可以随时调用各种专业设备,同时处理多道工序,效率和可能性都得到了质的飞跃,具体来看,它主要在以下几个方面解决了数据科学复杂流程中的核心痛点。
第一,它解决了“算力”这个最头疼的瓶颈。 数据科学工作中,尤其是模型训练阶段,常常需要巨大的计算能力,传统上,公司需要购买昂贵的物理服务器或者高端工作站,这不仅是巨大的前期投入,而且当项目不忙的时候,这些昂贵的设备就闲置了,造成浪费,更麻烦的是,如果某个项目需要比现有机器更强的算力,那就只能干瞪眼,要么牺牲时间,要么放弃更复杂的模型,云计算彻底改变了这一点,根据亚马逊AWS和微软Azure等主流云平台的服务理念,数据科学家可以按需租用计算资源,就像用电和用水一样,训练一个复杂的深度学习模型,可能需要几十个高性能GPU连续工作好几天,在云上,你可以瞬间开启一个拥有多个顶级GPU的虚拟机器,全速运行完成任务,然后立刻关闭它,只为实际使用的时长付费,这种弹性,让即使是最小的团队也能接触到世界顶级的计算能力,使得以前不敢想的大型模型训练和超大规模数据处理成为了可能。

第二,它让数据和工具的“管理与协作”变得前所未有的简单。 一个数据科学项目往往不是一个人单打独斗,而是一个团队协作的过程,在这个过程中,数据来源多样(可能来自数据库、日志文件、第三方API),工具链复杂(涉及数据清洗、特征工程、模型训练、部署等多个环节),在本地环境中,团队成员之间同步数据、统一软件环境、共享代码和模型版本是件非常麻烦的事情,很容易出现“在我电脑上是好的”这种问题,云计算平台提供了一整套集成的服务来解决这些问题,谷歌Cloud的AI Platform或阿里云的PAI,它们提供了从数据存储、数据预处理、模型训练到模型部署的全套托管服务,所有数据可以集中存储在云端的对象存储(如AWS S3)或数据仓库(如Snowflake,虽然不完全是云厂商提供,但通常部署在云上)中,团队成员可以安全地共享和访问,更重要的是,云平台允许团队将整个工作流程“流水线化”,定义一个从数据输入到模型输出的自动化流程,这样,任何成员都可以触发这个流程,确保每次实验的环境和步骤完全一致,极大地提高了实验的可复现性和团队协作效率。

第三,它极大地降低了“模型部署和持续维护”的门槛和成本。 俗话说,“模型训练只是开始,部署才是真正的挑战”,在本地服务器上部署一个模型,需要数据科学家或工程师具备额外的运维知识,去配置服务器、网络、监控系统等,当模型上线后,如果访问量突然激增(比如双十一大促),本地服务器很可能因为无法快速扩容而崩溃,云计算的另一大优势就在这里体现:它让模型部署变得像点一下按钮那么简单,以AWS SageMaker或Azure Machine Learning为例,它们提供了专门的托管服务,可以将训练好的模型一键部署为可调用的API服务,云平台会自动处理底部的服务器配置、负载均衡、自动扩缩容等所有运维问题,当预测请求增多时,系统会自动创建更多的实例来分担压力;请求减少时,又会自动缩减实例以节省成本,这种能力使得数据科学团队可以专注于模型本身的优化,而无需担心底层的基础设施,大大加快了从实验到产生实际业务价值的周期。
第四,它为“创新和探索”提供了安全的沙盒环境。 数据科学本身就是一个需要大量试错的探索性工作,尝试一个新的算法、测试一种新的特征工程方法,都可能需要一套独立的环境,以免影响正在稳定运行的主要项目,在本地,搭建这样一个隔离的测试环境同样需要硬件和时间的投入,而在云上,创建一个完全独立的、与生产环境隔离的开发沙盒,只需要几分钟和极低的成本,数据科学家可以在这个沙盒里大胆尝试各种想法,即使失败了,也不会对主线业务造成任何影响,只需关掉资源即可,这种低风险的试错能力,极大地鼓励了技术创新和快速迭代。
云计算并没有改变数据科学的核心方法论,但它通过提供弹性的强大算力、集成的协作工具、傻瓜式的部署运维和低成本的试错环境,将数据科学家从繁琐的基础设施管理和资源瓶颈中解放出来,让他们能更专注于数据本身和算法创新,它让数据科学的整个生命周期——从数据准备到模型部署和监控——变得更加流畅、高效和可扩展,真正实现了“让专业的人做专业的事”。
本文由寇乐童于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/76011.html