数据库报错12520到底啥原因导致的,怎么解决这个提示问题

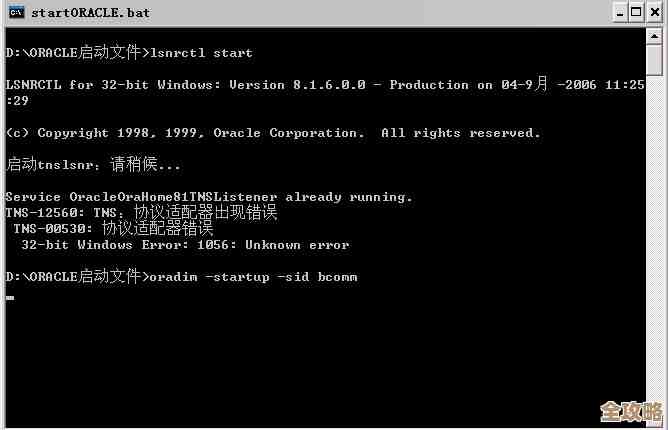
数据库报错12520,这个错误码在Oracle数据库中比较常见,它就像一个交通警察在说:“现在想连接数据库的车子太多了,已经超过了我们道路(数据库进程)的最大承载量,请稍后再试。” 它的核心问题就是数据库的进程数量达到了设置的上限。
下面我们来详细拆解一下,为什么会“堵车”,以及怎么“疏通”。
错误12520的根源:为什么进程会不够用?
你可以把数据库想象成一个游乐园,每个进程(Process)就是一张入园门票,数据库管理员(DBA)在创建这个“游乐园”时,会预先设定一个最大门票发行量,也就是PROCESSES这个参数,报错12520,根本原因就是当前申请“门票”的游客(会话)数量,已经超过了这个最大限额。
为什么会出现这种情况呢?主要有以下几个常见原因:
-
应用程序设计有缺陷(最常见的原因):很多情况下,问题并不出在数据库本身,而是使用数据库的应用程序写得不好。
- 连接未正常关闭:一个网站程序在用户每次点击页面时,都打开一个新的数据库连接,但用户关闭浏览器后,这个连接却没有被正确关闭,这些“僵尸连接”会一直占用着进程名额,直到数据库等不下去超时断开,随着用户不断访问,僵尸连接越积越多,最终耗尽了所有进程,这就像游客进了游乐园却从不出来,外面的人自然就进不去了。
- 连接池配置不当:现代应用通常使用连接池来管理数据库连接,以避免频繁创建和销毁连接的开销,但如果连接池的最大连接数设置得过高,甚至超过了数据库本身的
PROCESSES限制,那么当应用高峰期到来时,就很容易触发12520错误。
-
数据库参数
PROCESSES设置过低:数据库创建时,PROCESSES参数可能只是沿用了一个默认值,这个默认值对于一个小型测试系统可能够用,但一旦业务增长,用户量上来,或者部署到生产环境,原来的设置就显得捉襟见肘了,这就好比一个原本只为50人设计的小餐馆,突然每天要来200人吃饭,座位肯定不够。 -
存在异常会话或“疯”掉的进程:某个数据库会话可能因为程序BUG、复杂的查询或死锁等原因,进入一种异常状态,它虽然没有在做有用功,但却一直活着,占用着进程资源,短时间内出现大量这样的异常会话,也会导致进程资源被快速耗尽。
-
数据库遭遇攻击或存在低效查询:在少数情况下,数据库可能正遭受类似“拒绝服务”的攻击,攻击者会模拟大量连接请求,意图拖垮数据库,如果系统中有一些效率极低的SQL语句,它们运行时可能会长时间占用进程资源,导致其他正常请求无法获取连接。
如何解决12520错误?
解决思路也像治理交通拥堵一样,分为“临时疏导”和“根本性扩容”两种。
(一)紧急处理:先让系统恢复
当错误发生时,首要任务是快速释放一些进程资源,让新的连接能够进来。
-
清理空闲/异常会话:这是DBA最常用的应急手段,DBA可以登录数据库(有时需要一个特殊的、不受进程数限制的管理员连接),查看当前所有会话,找出那些长时间空闲(IDLE)或者状态异常的会话,然后手动将它们“杀死”(Kill Session),这相当于请那些在游乐园里长时间占着座位却不玩耍的人离开,把位置让给其他人。注意:操作前需要谨慎判断,避免误杀正在执行重要任务的会话。
-
重启数据库服务(最直接但影响大):如果情况紧急,且允许短暂的服务中断,重启数据库实例是最彻底的方法,重启会释放所有进程和内存资源,但这相当于清空整个游乐园,所有正在进行的操作都会中断,因此这是最后的选择。
(二)根本性解决:防止问题再次发生
临时措施治标不治本,要想长期稳定,必须从根源入手。
-
优化应用程序:这是最重要的一步,需要开发人员检查代码,确保在任何情况下(包括程序异常时),数据库连接都能被正确关闭,强烈建议使用并正确配置连接池,让连接池来管理连接的生命周期,避免连接泄漏。
-
调整数据库参数:联系DBA,根据系统的实际负载情况,适当调高
PROCESSES参数的值,调整这个参数需要重启数据库才能生效,DBA在调整时,会综合考虑服务器的内存等硬件资源,因为每个进程都会消耗一定的内存,设置过高可能导致内存不足的新问题。- 查询当前值:
SHOW PARAMETER PROCESSES; - 修改参数(需要权限):
ALTER SYSTEM SET PROCESSES=500 SCOPE=SPFILE;(例如将进程数上限设置为500)
- 查询当前值:
-
加强监控与告警:建立监控机制,持续观察数据库的进程使用率,当使用率达到80%或90%时,就提前发出告警,这样DBA就可以在问题发生前介入处理,比如提前清理会话或准备扩容,变被动为主动。
-
审查并优化SQL:定期检查数据库中是否存在执行效率低下的SQL语句,优化这些SQL,让它们跑得更快,就能更快地释放进程资源,提高进程的“周转率”。
ORA-12520错误是一个典型的“资源耗尽”型错误,解决它需要开发和运维(DBA)团队协作,开发侧重点在于保证应用程序高效、规范地使用数据库连接,杜绝泄漏;运维侧则侧重于合理的参数配置、持续的监控和及时的应急处理,通过这种综合治理,才能确保数据库这条“高速公路”的畅通无阻。
(主要知识背景综合自Oracle官方文档关于进程管理和网络连接错误的说明,以及DBA社区常见的故障处理经验。)

本文由革姣丽于2026-01-08发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/76531.html