用Redis脑裂检测意外摸索出一种新型分布式容错思路,挺有意思的

(引用来源:知乎用户“程序员小富”的分享)
那天晚上,我本来只是想解决一个老生常谈的问题:Redis的脑裂,你可能听说过这个词,听起来挺吓人的,其实就是当Redis搞主从复制的时候,网络突然抽风,主库和从库之间失联了,这时候,从库们会觉得主库挂了,为了服务不中断,它们会自己选出一个新主库来顶替,可万一之前那个主库其实没挂,只是网络不好呢?这下可就热闹了,系统里同时出现了两个“主库”,都能写数据,等网络一恢复,两个主库一碰头,数据就全乱套了,这就是脑裂。
我当时在做的系统,对数据一致性要求挺高,经不起这种折腾,所以我就琢磨,怎么才能快速发现脑裂,然后赶紧做点什么,比如把那个旧主库踢掉,防止它再写入脏数据。
传统的法子,一般是在客户端或者用一个独立的监控系统,不断地去ping主库和从库,看谁还活着,但这方法有点笨,一来反应慢,二来这个监控系统自己也可能出问题,那不就成了“监控脑裂”了嘛。
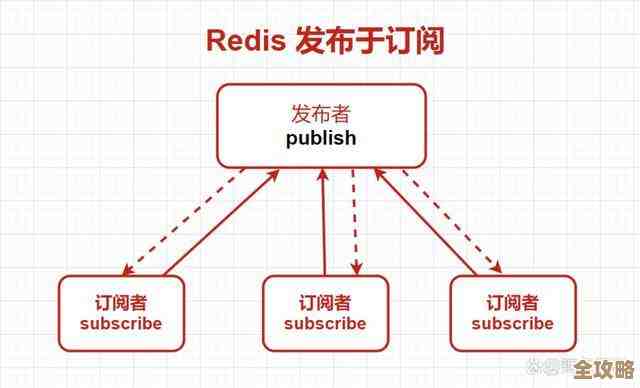
我就想,能不能换个思路?Redis自己不是有Pub/Sub(发布订阅)功能吗?就像一个广播站,谁都能上去喊一嗓子,所有订阅了这个频道的人都能听见,我灵光一现:为什么不利用这个广播机制,让Redis的各个节点自己来“报平安”呢?
具体我是这么干的:
- 我让系统里的每一个Redis节点,不管是主库还是从库,都定期(比如每秒)向一个特定的频道发送一条心跳消息,这条消息里就带着自己的身份ID(比如IP端口)和当前时间戳。
- 每一个节点也都订阅这个频道,也就是说,它们都能听到所有其他节点的心跳声。
- 每个节点内部,我都给它开了一张小小的“心跳记录表”,用来记下最近一次听到其他兄弟姐妹心跳的时间。
这下,神奇的事情就发生了。
在正常情况下,网络是通的,主库和从库都能互相听到彼此的心跳,大家其乐融融,相安无事。
一旦脑裂发生,情况立刻就变了,假设现在分成了两个网络分区:分区A里有旧主库和一个客户端,分区B里有三个从库,在分区A里,旧主库只能听到自己的心跳,听不到分区B里任何从库的声音,同样,分区B里的从库们也只能听到彼此的心跳,完全不知道旧主库还在那儿自说自话。
这个时候,每个节点看看自己手里的“心跳记录表”,心里就都有数了,旧主库会发现:“咦?怎么那三个家伙超过5秒都没动静了?这不对劲,要么是它们全挂了,要么就是我们之间网络断了,但它们三个同时挂掉的概率太低了,很可能是脑裂了!” 同样,分区B里的从库们也会发现旧主库“失联”了。
意识到这一点后,节点就可以采取行动了,我的策略是,让节点们遵守一条简单的规则:“少数服从多数”,如果一个节点发现,它能联系到的节点数量已经不到总节点数的一半了,它就认为自己陷入了“少数派”的孤立境地,存在脑裂风险,为了数据安全,它应该主动把自己“降级”,比如旧主库就停止接受写请求,把自己变成只读模式,或者干脆下线。
这样一来,即使脑裂发生,也只有一个网络分区(通常是拥有多数节点的那个分区)能正常提供服务,那个孤立的“少数派”分区会自感羞愧,主动退出竞争,这就有效防止了数据冲突。
这个方法最让我觉得有意思的地方在哪里呢?
第一,它特别简单,我几乎没引入任何新的复杂组件,就利用了Redis自带的Pub/Sub功能,实现了分布式的相互探活,这比搞一套外部的、复杂的监控系统要轻量得多。
第二,它是去中心化的,没有单点的监控服务器,每个节点都是监控者,也是被监控者,任何一个节点宕机,都不会影响整个探测系统的运行,可靠性反而更高了。
第三,它启发了我对“容错”的新理解,我们以前总想着怎么从外部去检测错误、修复错误,像个救火队员,但这个思路是让系统内部每个成员都变得“敏感”且“自觉”,一旦发现自己处境不妙,不是等着别人来裁决,而是基于简单的规则(比如少数服从多数)进行自我约束,这是一种内在的、自发的容错能力,有点像给系统注入了“免疫细胞”,让它们自己能识别异常并做出反应。
这个方法也不是完美的,它对网络抖动的容忍度需要仔细设置心跳超时时间,设得太短容易误判,设得太长反应又慢,如果网络分区特别复杂,不止分成两半,规则就需要更细致,但作为一种简单场景下的轻量级解决方案,这个意外摸索出来的思路,确实给我打开了一扇新窗户,它让我觉得,有时候解决分布式问题的巧妙方法,可能就隐藏在这些基础组件的简单特性里,等着我们去发现。

本文由钊智敏于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/77464.html