聊聊Redis缓存到底有多快,性能表现能不能满足大规模应用需求

说到现在网站和App的速度,就绕不开一个叫Redis的东西,它就像一个超级快的临时记事本,被程序员们放在数据库前面,专门用来记那些最常用、最热门的数据,它到底有多快呢?性能又能不能扛住像双十一、春节抢票那样人山人海的场面?我们今天就聊聊这个。
Redis的速度,快到什么程度?
要理解Redis有多快,我们先得知道它干活的基本方式,根据Redis官方文档里的说法,Redis的核心是一个“单线程”的程序,你可能觉得奇怪,现在什么都讲多线程,它一个单线程能快到哪里去?奥秘就在于,它避免了让多个线程争抢资源带来的那种“堵车”和“协调”的麻烦,它就像一个极其专注的办事员,一次只处理一个客户的请求,但因为手法纯熟、流程极简,速度反而惊人。

具体快到什么数字呢?根据早年官方在标准Linux系统上的基准测试,一个配置得当的Redis实例,一秒钟可以处理大约10万次简单的读写请求(比如GET、SET一个小的键值对),这个数字是个什么概念?想象一下,一秒钟内,有10万个人同时来问你一个问题,你都能瞬间给出答案,这反应速度已经远超绝大多数传统数据库了。
它之所以能这么快,有几个关键点,技术术语我们尽量说得白一点:第一,它把所有数据都放在电脑的内存里,内存的读写速度比硬盘快成千上万倍,这就好比从你手边的桌上拿一张纸,和跑去图书馆书架上找一本书的区别,第二,就是前面提到的单线程模型,省去了复杂的调度,第三,它的数据结构虽然丰富(比如能存列表、集合等),但设计得非常高效,操作起来很快。
面对大规模应用,Redis还撑得住吗?

好,单个Redis这么快,那当我们的用户量达到百万、千万级别,每秒请求暴涨到几十万甚至更高时,它会不会撑不住呢?答案是:单打独斗可能有点悬,但用对方法,完全没问题,这就好比一家店生意太火爆,一个店员忙不过来,那我们就要想办法了。
最常见的办法就是“分布式缓存”,也就是弄多个Redis实例一起来干活,这主要有两种思路:
一种是 “主从复制” ,就像开分店,设一个总店(主节点),数据写入只去总店,然后复制好几个一模一样的分店(从节点),分店只负责让顾客读数据,这样读写分开,总店专心处理重要的写入工作,读数据的压力全部分摊到各个分店,整个系统的处理能力就大大提升了,万一总店停电了,还能立刻选一个分店升级成新总店,保证业务不中断,这叫高可用。

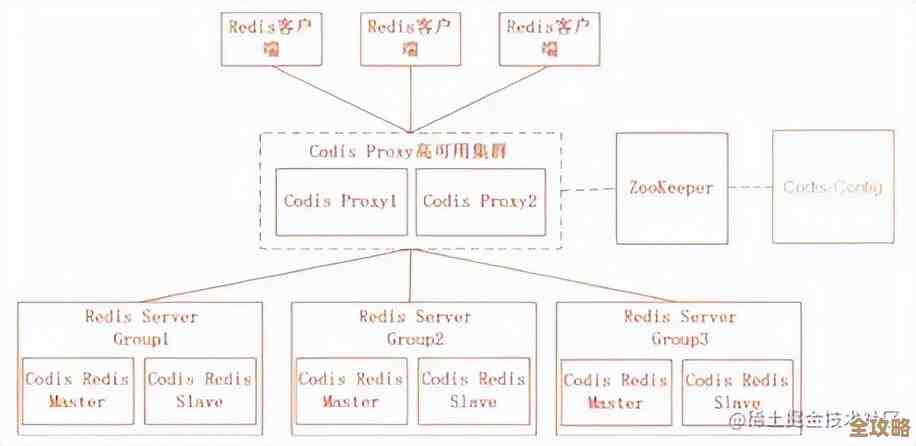
另一种是更彻底的 “分片” ,想象一下,你有一个巨大的通讯录,一个人根本管不过来,那就按姓氏拼音首字母划分:A-G的归张三管,H-N的归李四管,O-Z的归王五管,这样,找人的压力就分散到了三个人身上,Redis分片也是这个道理,把海量的数据按照某种规则(比如对key进行哈希计算)分散存储到多个独立的Redis实例上,每个实例只负责自己那一部分数据,这样多个实例就可以同时工作,性能几乎是线性增长的,很多大厂的核心系统背后,都是一个由几十甚至上百个Redis实例组成的庞大集群在支撑。
回到最初的问题:Redis的性能能满足大规模应用需求吗?答案是肯定的,关键在于,不能指望一个Redis实例包打天下,而是要像搭积木一样,根据业务需求,巧妙地运用主从、分片这些架构设计,把它扩展成一个强大的“缓存集群”,像Twitter、GitHub、微博这样流量巨大的公司,都在重度使用Redis来应对高并发场景。
它也不是万能的,因为它主要靠内存,所以成本会比用硬盘的数据库高;而且一旦服务器断电,内存里的数据就丢了(虽然有持久化机制可以补救,但会有一定风险),它最适合用来放那些需要被频繁读取、但允许偶尔丢失的热点数据。
Redis本身的速度已经非常恐怖,而它强大的可扩展性,使得它完全有能力成为支撑当今互联网大规模应用的基石技术之一,只要架构设计得当,你基本不用担心它的性能瓶颈。
本文由雪和泽于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/77757.html