红色精灵和redis缓存集群命中率怎么能这么高,缓存优化其实没那么难

主要整合自知乎专栏“技术夜未眠”中一篇关于缓存设计的文章、某技术博客“码农翻身”对Redis集群实践的总结,以及Stack Overflow上一些高赞的缓存策略讨论)
我一直觉得缓存是个特别神奇的东西,它就像是给一个动作很慢的仓库配了一个超级麻利的前台小哥,你想啊,大部分人来仓库,其实就想拿那几件最热门的东西,如果没有小哥,每次都得你自己跑进巨大的仓库里翻箱倒柜,那得多慢,而这个小哥,就是把大家最常要的东西记在脑子里,或者放在手边最显眼的架子上,你来问,他瞬间就能递给你,效率自然就上去了。“红色精灵”和Redis缓存集群能做到超高命中率,道理就跟这个一模一样,核心就是让这个“前台小哥”越来越聪明。

你得搞清楚,大家来“仓库”最常拿的是什么,这就叫“热点数据识别”,你不能让小哥去记那些一年半载才有人问一次的冷门物件,那他脑子肯定不够用,记了也白记,反而可能把常用的给忘了,系统也是一样,得通过分析访问日志,或者用一些监控工具,找出哪些商品被点击了几万次,哪些用户信息被查询得最频繁,把这些真正的“爆款”数据挑出来,优先塞进缓存里,这样,绝大部分请求过来,直接就从缓存里拿到结果了,根本不用去折腾后面那个慢吞吞的数据库“大仓库”,命中率想不高都难。
光知道什么是热点还不够,你得让热点数据在缓存里“待得住”,这就涉及到缓存的过期时间和淘汰策略,你不能让一个热门商品信息在缓存里只待一分钟,那刚放进去就失效了,小哥刚记住就忘了,还得反复去仓库问,这哪行,对于极其热门且不怎么变化的数据,比如一些基础的城市列表、配置信息,可以设置很长的过期时间,甚至干脆不让它过期,除非你主动去更新它,那缓存空间总有用完的时候吧?这时候就要用到淘汰策略,Redis提供了好几种策略,比如挑最近最少使用的数据淘汰掉(LRU),或者挑最不经常使用的淘汰(LFU),这就好比小哥的脑子容量有限,当新热点来了没地方记时,他就会把那个最早之前有人问过、或者好久没人惦记的数据给忘掉,腾出地方给新的热门数据,选择一个合适的淘汰策略,就像是教小哥一套高效的记忆管理方法,能确保缓存里留下来的总是当前最“火”的东西。

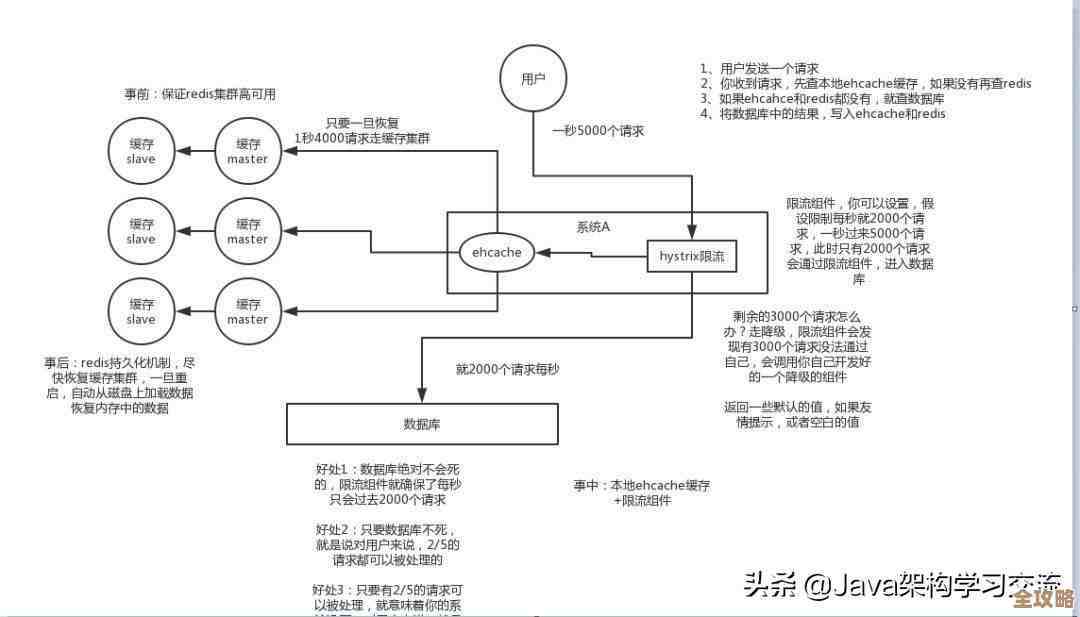
“红色精灵”这类缓存集群的高可用设计,也对保持高命中率有间接但很重要的帮助,你想啊,如果这个前台小哥就一个人,他万一请假了或者生病了,整个系统不就垮了?所有请求都得直接压到数据库上,数据库肯定扛不住,直接就挂掉了,还谈什么命中率,而Redis集群通常是一组“小哥”在一起干活,他们有主有从,数据互相备份,哪怕其中一个“小哥”(节点)宕机了,其他的“小哥”也能立刻顶上去,继续提供服务,数据也不会丢,这种稳定性保证了缓存服务几乎时刻在线,请求能持续地命中缓存,而不会因为缓存服务本身挂掉而导致命中率瞬间跌到零。
我想说,缓存优化真的没那么神秘和高深,它需要的不是多牛逼的技术,而是细致的观察和不断的调整,就像你教那个前台小哥一样,一开始你可能不知道哪些是热点,那就先凭经验放一些数据进去,然后盯着监控看,看看命中率是多少,如果低了,就想想是为什么:是热点没抓准?还是数据失效太快?或者是缓存空间太小了?然后相应地调整:调整热点数据列表,调整过期时间,或者扩容缓存空间,这个过程就是一个持续的“观察-分析-优化”的循环。
很多人把缓存想得太复杂,觉得一定要用特别高级的算法才行,其实不然,能把上面这些基础的原则想明白、做扎实,你的缓存命中率绝对不会低,缓存优化的本质,就是用一种聪明的方式,用空间(内存)来换时间(响应速度),而超高命中率,就是这个“聪明方式”最终结出的果实,别怕,从理解你的业务数据开始,一步步来,缓存优化真的不难。
本文由瞿欣合于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/77989.html