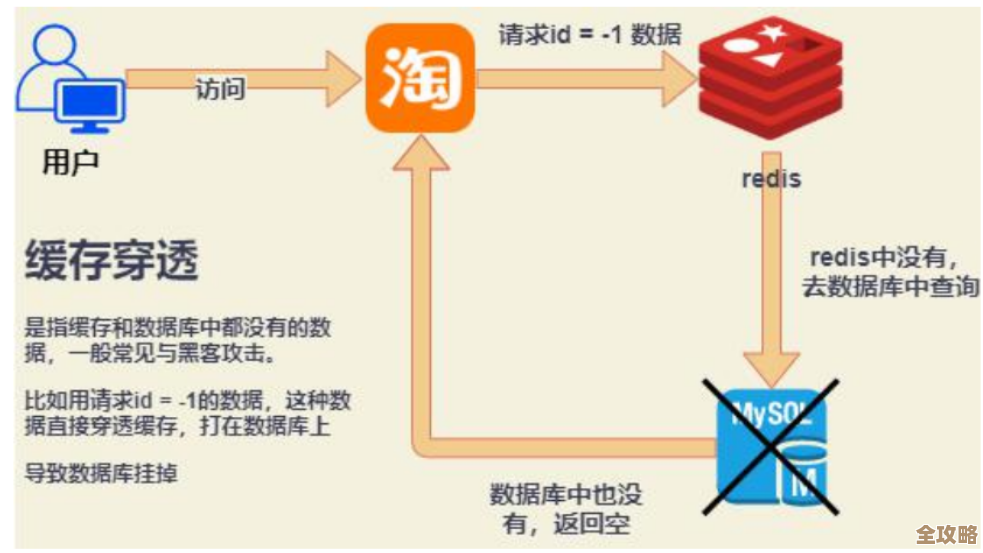
Redis到底怎么保证稳健运行,这些运行逻辑你得知道一点

Redis为了保证自己能稳定、高效地运行,不像我们平时写个简单的程序那样随意,它内部有一套相当周全的“自我保护”机制,就像一个精密的机器,既有主动的保养策略,也有被动的应急方案,理解这些逻辑,对于用好Redis至关重要。
Redis最怕的就是突然断电或者进程意外崩溃,导致内存里的数据全部丢失,为了解决这个问题,它设计了两种主要的“持久化”方式,相当于给内存数据拍照片或者记日记,以便在重启后能恢复回来。
第一种方式叫RDB,你可以把它想象成“拍快照”,Redis会按照你设定的时间规则(比如每隔5分钟,或者至少有1000个键被改变时),把当前内存中所有数据的完整状态压缩后保存到一个二进制文件里(默认叫dump.rdb),这个过程是通过fork出一个子进程来完成的,父进程继续处理客户端的请求,子进程专心致志地生成快照,这样就不会阻塞主进程的服务,RDB的优点是恢复速度快,文件体积小,非常适合做灾难恢复和备份,但缺点是可能会丢失最后一次快照之后的数据(比如刚拍完快照,过了4分钟服务器宕机了,这4分钟的数据就没了)。
第二种方式叫AOF,这更像是“写日记”,它会把Redis服务器执行的每一个写命令(比如set、sadd)都记录在一个日志文件里,当Redis重启时,它会从头到尾重新执行一遍这个日记里的所有命令,从而还原数据,为了平衡性能和安全性,AOF提供了几种刷盘策略:比如可以每秒钟让操作系统把日记内容写入磁盘一次(可能会丢失1秒数据),或者每次写命令都强制刷盘(最安全,但性能损耗最大),AOF的优点是数据安全性极高,最多丢失1秒数据,甚至可以不丢失,缺点是日志文件会越来越大,恢复速度比RDB慢,所以Redis还提供了AOF重写机制,定期根据当前数据状态生成一个更精简的日志,去掉中间过程的无用命令。
在实际生产中,通常会将RDB和AOF结合使用,用AOF来保证数据不丢失,用RDB来做冷备和快速恢复。
光保证数据不丢还不够,Redis还得保证服务不能轻易中断,这就需要“高可用”方案,最常见的方案就是主从复制,你可以配置多个Redis实例,其中一个作为主节点,其他作为从节点,主节点负责处理写请求,然后自动将数据的变化同步给所有的从节点,这样一来,从节点就有了和主节点几乎一模一样的数据副本。
这样做有几个好处:一是读写分离,读请求可以分摊到各个从节点上,减轻主节点的压力;二是数据备份,即使主节点挂了,从节点上还有完整的数据;三是为故障转移做准备,如果主节点真的宕机了,管理员(或者自动化工具)可以手动(或自动)选择一个健康的从节点,“扶正”它成为新的主节点,让应用连接到新的主节点上继续服务,这样就实现了服务的快速恢复,保证了高可用性,更完善的方案是使用Redis Sentinel(哨兵)或者Redis Cluster(集群),它们能自动监控节点状态并完成故障转移,无需人工干预。
Redis是单线程处理命令的,这意味着它非常怕遇到一些耗时很长的操作,因为一个命令卡住,后面所有的请求都得等着,整个服务就停滞了,为了保证运行的稳健,Redis自己会进行一些“内部控制”,它会监控客户端的连接时长和命令执行前的空闲时间,如果超过配置的阈值,它会主动断开这个连接,防止某个慢客户端拖死整个服务器,当执行一些像keys *这样的危险命令时,如果返回的数据集非常大,也会占用大量CPU时间和网络带宽,导致服务不稳定,所以生产环境通常要禁用这类命令。
任何系统资源都是有限的,Redis也不例外,如果内存用满了,新的数据就写不进去了,Redis提供了几种“内存淘汰策略”来应对这种情况,你可以配置当内存不足时,Redis该如何处理,比如可以随机删除一些键,或者删除最近最少使用的键,或者直接拒绝所有写请求并返回错误,选择合适的淘汰策略,可以保证在内存压力下,服务还能以可控的方式运行,而不是直接崩溃。
Redis通过持久化(RDB和AOF) 来解决数据可靠性问题,通过主从复制和高可用架构(哨兵/集群) 来解决服务连续性问题,再辅以内部的慢查询控制、连接管理和内存淘汰策略等细粒度的自我保护机制,共同构成了一套保证其稳健运行的完整逻辑体系,理解这些,才能更好地驾驭Redis。 参考和整合了Redis官方文档的核心概念以及《Redis设计与实现》等常见技术资料中对持久化、复制、高可用等机制的阐述)

本文由钊智敏于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78234.html