Redis集群和主从复制结合用,效率提升其实没那么难理解

综合自互联网技术社区关于Redis架构的常见讨论与实践经验分享)
Redis这个东西,咱们可以把它想象成一个超级快的临时记事本,专门用来记那些需要频繁读写但又不必永久保存的数据,比如网站用户的登录状态、购物车里的商品、或者秒杀活动时那个不断减少的库存数量,当你的网站用户很少,读写操作不多的时候,一个Redis记事本(也就是单实例)就完全够用了,又快又简单。
如果你的网站做大了,比如像淘宝、京东那样,每秒钟有几十万、上百万人同时访问,所有操作都挤在同一个记事本上,那这个记事本再快也忙不过来,肯定会卡顿,这就好比一个超级收银员,面对一条望不到头的长队,最终也会累垮,更危险的是,如果这个唯一的收银员(Redis实例)生病请假了(服务器宕机),整个超市的结算系统就瘫痪了。
那怎么办呢?Redis提供了两种主要的“扩容”和“保命”的方法:主从复制和集群,很多人觉得这两个概念放在一起很复杂,其实把它们拆开看,再合起来想,就很容易明白是怎么提升效率的了。

先说说主从复制,它的核心目标是“保命”和“读提速”。
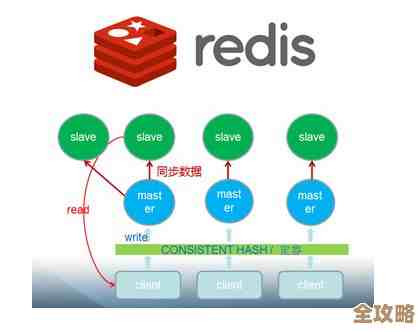
你可以把它想象成“复印机”或者“备份秘书”,你设置一个主要的记事本(主节点),这个主记事本负责处理所有写操作(比如用户往购物车里新加了个商品),你配好几台复印机(从节点),这些复印机会实时地、一字不差地把主记事本上写的内容全部抄录一遍,这样,你就有了一个主本和多个完全一样的副本。
这样做有两个巨大的好处: 第一是数据安全有保障了,万一主记事本丢了或者坏了,你可以立刻从几个副本里选一个顶上去当新的主记事本,服务几乎不中断,数据也基本不丢失,这叫高可用。 第二是读操作可以分流了,像用户浏览商品详情、查询购物车这种只读的操作,没必要全都去麻烦那个日理万机的主记事本,可以把这些读的请求,分散到那几台复印机(从节点)上去,主节点专心负责写,读的压力被分摊了,整个系统的处理能力自然就上去了,这就好比总经理只负责签字拍板(写),而查阅文件、回答咨询的工作都交给了秘书(读),效率更高。

那集群又是干什么的呢?它的核心目标是“写扩容”。
主从复制解决了读的压力和备份的问题,但写的压力还在那个唯一的主节点身上,无论你有多少个从节点,最终所有写入的数据都得经过那一个主节点,当数据量巨大(比如你的记事本写了一百万条记录),或者写的请求高到离谱(每秒要处理十万次写操作)时,一个主节点终究会达到极限。
这时候,就需要集群出场了,集群的本质是“分而治之”,它把海量的数据分成很多个小份(叫做分片或槽位),然后每一份数据都由一个独立的“小团队”来负责,这个“小团队”本身,就是一套完整的主从复制结构——包含一个主节点和几个从节点。

举个例子,假设原来你有一个能存1亿个键值对的主从结构,现在你用集群模式,把它分成0到16383一共16384个槽位,然后准备三套主从结构(三个小团队),团队A的主节点负责管理0-5460号槽位的数据,团队B负责5461-10922号槽位,团队C负责10923-16383号槽位。
这样一来:
- 写的压力被分摊了,当一个写请求过来(比如设置某个键的值),集群会根据这个键的名字算一下它属于哪个槽位,然后把这个请求精准地发送给管理那个槽位的“小团队”的主节点,写请求不再集中到一个主节点,而是由三个(或者更多)主节点共同承担,写的总容量和性能就成倍增加了。
- 数据存储也分摊了,每个主节点只存储整个数据集的一部分,所以单台机器的内存压力也变小了。
为什么说“集群和主从复制结合用,效率提升不难理解”?
因为它们是各司其职、相辅相成的。
- 主从复制是基础单元,它在每个“小团队”内部解决了数据冗余备份和读写分离(读扩展)的问题。
- 集群是宏观架构,它通过把多个这样的“小团队”(主从复制单元)组织起来,解决了数据分片和写操作扩展的问题。
你得到的是一个既强壮又能伸缩的系统:数据被安全地复制了多份,不用担心单点故障;读请求可以分散到众多从节点上,响应飞快;写请求和大量数据也被均匀分布到多个主节点上,突破了单机性能的瓶颈。
简单总结就是:主从复制让每个“点”变得更可靠、读得更快;集群把多个“点”连成“面”,让整个系统写得更猛、存得更多,两者一结合,效率的提升就是水到渠成的事情了。 这种设计思想不仅在Redis里,在很多大型分布式系统中都能看到类似的影子。
本文由酒紫萱于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78345.html