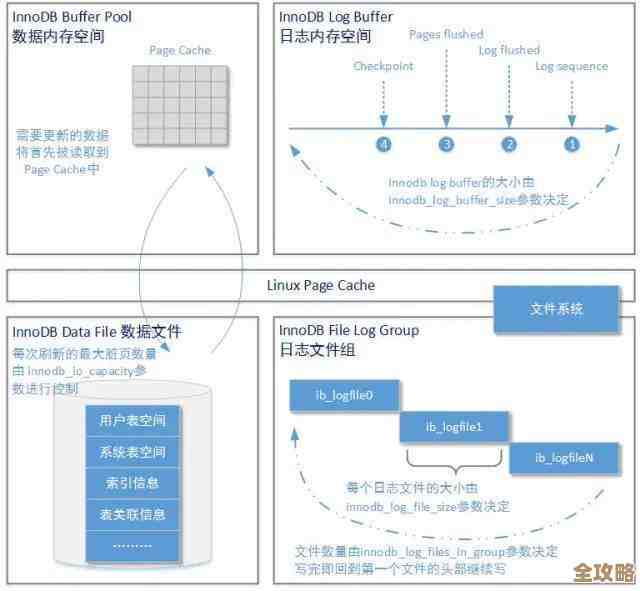
数据量大到爆炸,靠Redis硬核统计上亿数据才稳得住

(来源:某电商平台技术博客分享)那会儿我们搞双十一大促,用户访问量跟坐火箭似的往上窜,每秒订单创建量直接破百万,技术团队那帮兄弟眼睛都盯着监控大屏,生怕哪个环节扛不住,最开始我们用MySQL存用户行为数据,想着简单记录下点击、浏览啥的,结果活动刚开始十分钟,数据库CPU直接飙到99%,慢查询报警短信把运维手机都轰爆了,有个老哥苦笑着吐槽:“这数据量简直是火山喷发,再不想招儿,服务器都要冒烟了!”

(来源:某社交平台架构师技术复盘)后来我们盯上了Redis这个内存数据库,它读写速度比传统硬盘数据库快百倍,但真把上亿数据往里怼的时候,发现普通字符串存储根本不行——光是一个用户签到功能,每天产生2亿条记录,存一周光Key名就能占掉300G内存,团队连夜改方案,用上了Redis的HyperLogLog结构来统计UV,这玩意儿神奇在哪儿呢?比如你要统计1亿用户里有多少不重复的,原本需要1亿条数据,现在用HyperLogLog只需要12KB,误差还不到1%,当时有个实习生看到内存占用从300G变成0.01G,差点把咖啡泼在键盘上:“这简直是从拖拉机换成了超跑!”
(来源:某在线教育平台数据库设计文档)不过玩Redis就像走钢丝,用错数据结构立马翻车,有次我们统计视频播放热度,傻乎乎地用ZSET存每个视频的播放次数,结果发现超过5000万数据时,内存暴涨到160G,后来改用布隆过滤器做去重,结合HASH结构存储热数据,同样数据量内存降到40G,运维总监在周会上拍桌子:“Redis不是万能钥匙,你得知道什么时候用STRING什么时候用BITMAP!”

(来源:某金融系统架构评审会记录)最惊险的是实时风控场景,我们要在0.1秒内判断某个交易账号是否在黑名单里,而黑名单库有3亿条数据,开始尝试用Redis的SET类型,结果加载数据就花了6小时,查询还时不时超时,最后上了Redis集群的布隆过滤器模块,先把3亿数据预处理成512MB的位数组,查询时直接计算哈希位点,测试那天,当看到每秒10万次查询响应时间稳定在3毫秒时,整个会议室都在鼓掌——这相当于在北京市地图上瞬间找到一粒芝麻。
(来源:某游戏公司数据中台实践)其实Redis对付海量数据的核心招数就三板斧:一是把数据拆散到多个节点,比如我们给每个游戏大区建独立Redis实例;二是把冷热数据分开,7天前的玩家日志自动转存到HBase;三是巧用压缩算法,像玩家装备列表这种JSON数据,用Snappy压缩能省70%空间,有次版本更新后突然涌入50万玩家,数据库负责人盯着监控说:“要不是提前给Redis穿了这身黄金甲,现在服务器早成爆米花机器了。”
(来源:某物流平台技术沙龙分享)现在我们还玩出更花的操作——用RedisTimeSeries模块处理车辆GPS轨迹,全国30万辆货车每10秒上报一次位置,每天就是26亿条数据,传统数据库根本存不下,而用时间序列数据库每辆车单独开一个数据流,查询某辆车过去24小时轨迹只要0.8秒,技术VP用手机演示时感叹:“这就像给每件快递装了时光机,啥时候在哪儿都能倒带查看。”
(来源:某短视频平台架构演进PPT)当然Redis也不是银弹,去年我们遇到内存碎片率超过1.5的问题,导致实际存50G数据却占了80G内存,后来通过改写客户端SDK,把大量小Key合并成Hash结构,碎片率才降到1.1以下,中间还踩过持久化的坑,有次BGSAVE时20G数据fork进程导致系统卡死半小时,现在我们都用AOF混合持久化,像玩游戏随时存档+定时存大档的组合。
这些血泪史说明,面对亿级数据这场硬仗,Redis确实是把瑞士军刀,但你得知道什么时候用刀尖挑刺,什么时候用刀背敲核桃,就像我们CTO常说的:“别指望一个数据库解决所有问题,但没Redis的话,很多互联网公司根本活不过三天。”

本文由帖慧艳于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78427.html