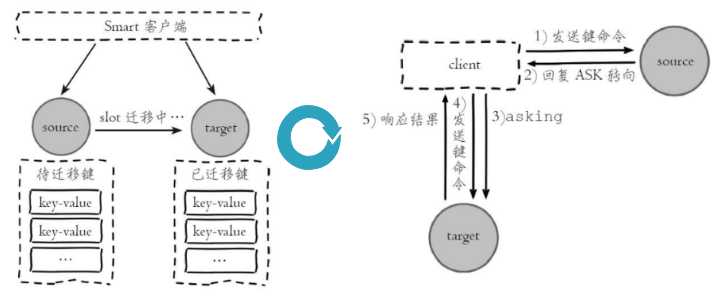
多级索引到底有多重要,数据库里它是怎么帮我们提速的?

多级索引,你可以把它想象成一本超级详细的百科全书不是只有一个总目录,而是每一章、每一节甚至每个小节都有自己独立的、更精细的目录,在数据库的世界里,它就是帮助我们快速找到数据的神兵利器,其重要性怎么强调都不过分,尤其是在处理海量数据的时候。
想象一下,如果没有索引会怎样?这就好比你要在一座巨大的、书籍完全乱放的图书馆里找一本特定的书,你唯一的办法就是从第一个书架开始,一本一本地翻看,这就是数据库中的“全表扫描”,当数据量只有几百几千条时,可能感觉不到慢,但当数据达到百万、千万甚至上亿级别时,这种查找方式就会慢得像大海捞针,根本无法满足现代应用的需求。
单级索引是怎么工作的呢?它就像图书馆里只有一个按照书名拼音排序的目录卡,你想找《红楼梦》,直接去“H”开头的区域就能快速定位,避免了遍历所有书架,在数据库中,单级索引(比如在“姓名”字段上建立索引)也是类似的原理,数据库会维护一个排序好的列表(类似于目录卡),里面记录了每个姓名和其对应数据在硬盘上的位置,查找时,数据库先在这个有序列表里快速定位(比如用二分法),然后直接去对应位置读取数据,速度极快。
单级索引有它的局限性,现在你想找“所有在2023年购买了手机的用户”,如果你的数据库里只有“用户姓名”的索引,那么这个查询就用不上这个索引,因为它无法帮你筛选“2023年”和“手机”这两个条件,最终还是得进行全表扫描,这时候,多级索引的价值就凸显出来了。
多级索引,顾名思义,就是像复合目录一样,有多层排序,我们可以创建一个基于“购买年份”和“商品类别”的多级索引,这个索引会首先按照“购买年份”进行排序,在同一个年份内,再按照“商品类别”进行排序。
这样一来,当数据库执行“查找2023年购买手机的用户”这个查询时,它的操作就变得非常高效:
- 它直接跳到多级索引中“2023年”这个分区,由于索引是有序的,这一步可以瞬间完成。
- 在“2023年”这个分区内部,它又快速定位到“手机”这个子分区。
- 它只需要读取这个非常小的、精确的“2023年-手机”子分区里的数据指针,然后去硬盘上把对应的少量数据取出来就行了。
这个过程避免了扫描2022年、2021年等其他无关年份的数据,也避免了在2023年内部扫描“书籍”、“服装”等其他无关商品的数据,扫描的数据量呈指数级下降,查询速度自然得到巨大提升。
这个原理在谷歌学术的“如何实现现代搜索引擎”的相关技术讨论中被类比为使用“倒排索引”的组合来高效处理多维度查询,虽然具体技术不同,但核心思想一致:通过预先组织数据(建立索引),将查询时需要检查的数据范围最小化。
除了这种多列组合查询,多级索引在数据库的排序和分组操作中也能发挥巨大作用,如果查询要求“按照年份和类别分组统计销售总额”,如果已经存在(年份,类别)的多级索引,数据库根本不需要临时对海量数据进行排序和分组,因为它可以直接按顺序读取已经排好序的索引数据,统计效率极高,在数据库管理系统教材中,这通常被描述为索引对于 ORDER BY 和 GROUP BY 子句的优化作用。
多级索引并非没有代价,就像图书馆制作越多的目录卡就需要越多的柜子来存放一样,每个索引都会占用额外的磁盘空间,每当图书馆新增、删除或修改一本书的信息时,它也需要更新所有相关的目录卡,这会增加数据写入(增、删、改)的时间开销,数据库管理员需要权衡读写比例,明智地选择在哪些列上建立单级或多级索引,通常的原则是“为最常用的、最能缩小查询范围的查询条件组合创建索引”。
多级索引是数据库性能优化的核心手段之一,它通过构建一个多层次、有序的“快捷路径”系统,将原本需要遍历整个数据集的、耗时漫长的查询,变成了精准的、跳跃式的数据定位,从而在面对复杂查询和海量数据时,保证了系统的响应速度和应用的用户体验,可以说,没有高效的索引技术,我们今天使用的许多需要即时处理大量数据的互联网服务都将难以实现。

本文由度秀梅于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78477.html