Oracle SQL语句到底是怎么一步步执行的,搞清楚这过程其实挺重要的

当我们打开一个像SQL Plus、SQL Developer这样的工具,或者通过一个应用程序(比如一个网站的后台程序)连接到Oracle数据库,然后输入一条简单的SQL语句,SELECT * FROM employees WHERE department_id = 10; 并按下回车后,数据库内部其实一点也“不简单”,它为了返回我们想要的结果,默默地进行了许多复杂且精妙的步骤,这个过程就像是把一道复杂的加工指令(SQL语句)交给一个庞大的智能工厂(Oracle数据库),工厂需要理解指令、制定生产计划、调配资源、最后产出成品,搞清楚这个过程非常重要,因为它能帮助我们写出更好的SQL语句,当语句运行缓慢时,我们也能够快速定位问题出在哪个环节。
这个过程大致可以分为解析(Parsing)、优化(Optimization)和执行(Execution)三大阶段。
第一步:解析(Parsing)—— 理解你的指令
工厂拿到订单后,首先要确认订单写的是什么意思,是不是符合规范,以及要生产的东西是否存在,数据库也一样,解析阶段就是数据库“读懂”SQL语句的过程,这个阶段又细分为几个小步:
-
语法检查(Syntax Check): 数据库首先会像个严格的语法老师,检查你写的SQL语句在“拼写”和“语法结构”上是否正确。
SELECT有没有拼错成SELECCT?FROM关键字有没有漏写?括号是否成对出现?如果这里出错,你就会立刻收到一个语法错误提示,过程就此中断。
-
语义检查(Semantic Check): 语法正确不代表语句就有意义,接下来数据库会进行语义检查,确保语句所涉及的对象(比如表名、列名)是真实存在的,并且你是否有权限访问它们,它会去查询数据库的“户口本”(数据字典),确认
employees表是否存在,里面是否有department_id这个列,如果你试图查询一个不存在的表,或者你没有权限查看这个表,此时就会报出语义错误。 -
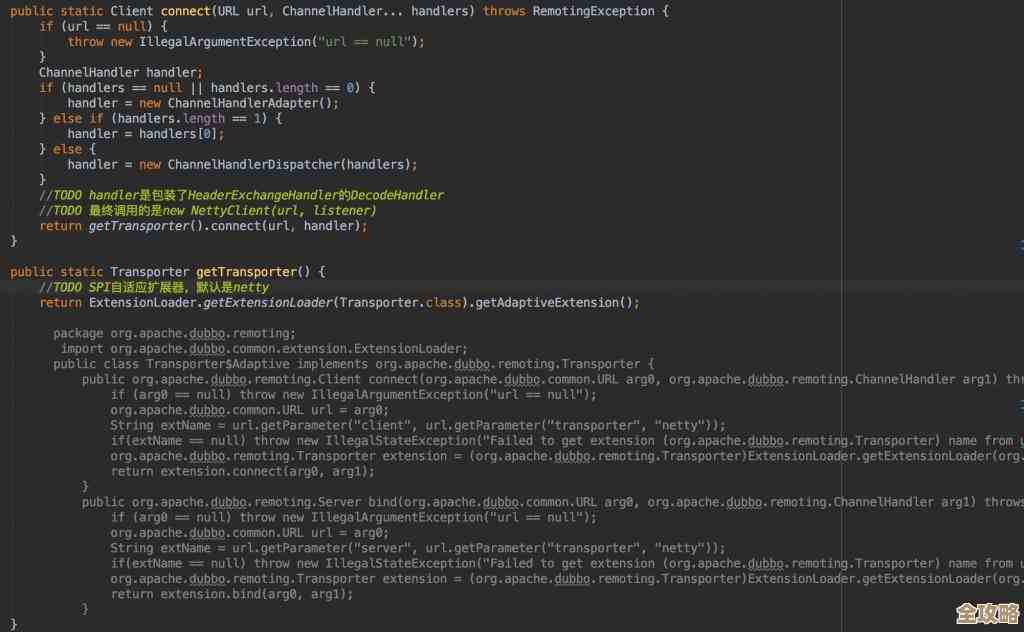
共享池检查(Library Cache Check): 这是为了提升效率的关键一步,想象一下,如果工厂每次接到一模一样的订单都重新从头开始制定生产计划,那会非常浪费时间和资源,Oracle数据库也有一个叫“共享池”的内存区域,专门用来缓存最近执行过的SQL语句以及它们的执行计划,在硬解析之前,数据库会对你提交的SQL语句做一个“指纹”计算(哈希运算),然后拿着这个指纹去共享池里查找,看有没有一模一样的语句最近刚被执行过,如果找到了,并且相关的表结构等都没变化,那么数据库就可以跳过最耗时的优化阶段,直接复用缓存中的执行计划,这个过程叫做“软解析”,这能极大地降低系统开销,如果没找到,那就不得不进行“硬解析”。
第二步:优化(Optimization)—— 制定最佳生产计划
如果解析阶段确认了指令是合法且需要新制定计划的(即硬解析),那么就进入了核心的优化阶段,优化器是Oracle数据库里最聪明的组件,它的任务就是为SQL语句找出一个它认为“成本”最低、速度最快的执行方案。

对于我们的例子 SELECT * FROM employees WHERE department_id = 10;,优化器会思考多种可能性:
- 方案A: 对
employees表进行全表扫描,一行一行地检查department_id是否等于10。 - 方案B:
department_id列上刚好有一个索引,那么可以先快速扫描这个索引,找到所有department_id=10对应的数据行在磁盘上的位置(ROWID),然后再根据这些位置去表中把整行数据取出来。
优化器会根据表的统计数据(比如表有多大、数据分布情况等)来估算每种方案的代价(主要是需要读取多少数据块、消耗多少CPU),它可能认为表很小,全表扫描更快;或者表很大,但满足条件的记录很少,用索引更快,它选择一个自认为最优的执行计划,这个计划就像工厂的流水线图纸,明确规定了先做什么、后做什么、用什么方法做。
第三步:执行(Execution)—— 按照计划开工生产
一旦执行计划确定下来(无论是新生成的还是从共享池里找到的),执行引擎就会登场,它严格遵循执行计划中的步骤去操作数据。

继续我们的例子,假设优化器决定使用方案B(索引扫描):
- 执行引擎首先会去访问
department_id索引,在索引树结构中快速定位到所有值为10的索引条目。 - 每个索引条目都包含了对应数据行的物理地址(ROWID)。
- 执行引擎根据这些ROWID,准确地到
employees表所在的数据块中去把完整的行数据读取出来。 - 将这些符合条件的数据行组装成结果集的形式。
如果执行的是UPDATE、DELETE或INSERT语句,步骤会更为复杂,还需要涉及锁的获取、生成重做日志(Redo Log)以确保数据安全等操作。
总结与重要性
一条SQL语句的执行之旅可以简要概括为:连接数据库 -> 提交SQL -> 解析(语法、语义、共享池检查)-> 优化(生成执行计划)-> 执行(数据访问与返回)。
理解这个过程为什么重要呢?
- 指导SQL编写: 知道了优化器依赖统计数据,我们就会明白及时更新统计信息的重要性,知道了软解析能提升性能,我们就会在编程中倾向于使用绑定变量(
WHERE department_id = :dept_id),而不是将值直接拼接到SQL字符串中,这样可以极大增加软解析的几率,避免硬解析带来的高昂开销。 - 性能问题诊断: 当一条SQL跑得慢时,我们可以系统地排查,是解析时间太长(可能共享池太小或没使用绑定变量)?还是执行计划不好(可能统计数据过时,导致优化器选错了索引)?或者是执行阶段本身就很慢(需要处理的数据量太大)?通过查看SQL的执行计划,我们就能像看诊断报告一样,知道时间主要耗在了哪一步,从而有针对性地进行优化。
把Oracle处理SQL的过程想象成一个智能工厂的流水线,理解每个环节的职责和瓶颈,对于我们高效地使用数据库至关重要。 综合了Oracle官方文档的核心概念、以及如《Oracle Database Concepts》手册、AskTOM网站的技术问答、和众多资深DBA(如盖国强、谭怀远先生)在《深入解析Oracle》等著作中阐述的普遍共识。)
本文由雪和泽于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78663.html