Redis集群单台宕机了咋办,怎么应对和保证服务不停啊

当Redis集群中的某一台服务器突然宕机了,首先别慌,现在主流的Redis集群设计本身就是为了应对这种情况的,核心思想就是“备份”和“自动切换”,下面我们一步步来看具体怎么应对和保证服务基本不停。
Redis集群如何提前预防单点故障?
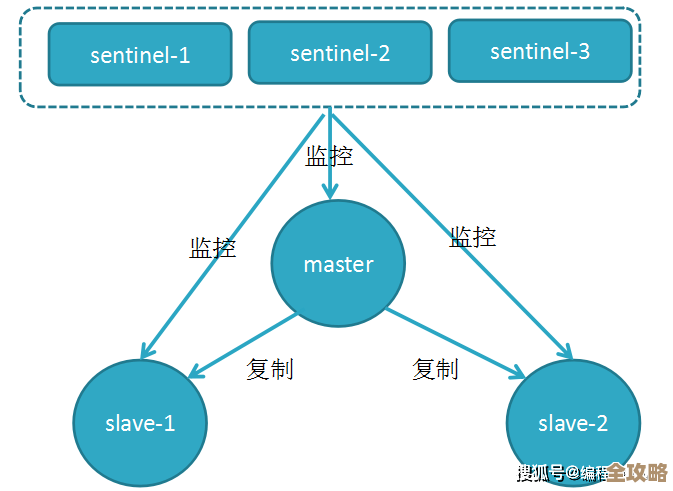
这要从Redis集群的运作方式说起,根据Redis官方文档(redis.io)对集群模式的说明,一个Redis集群通常由多个节点(Node)组成,这些节点可以分为两类:主节点(Master)和从节点(Slave)。

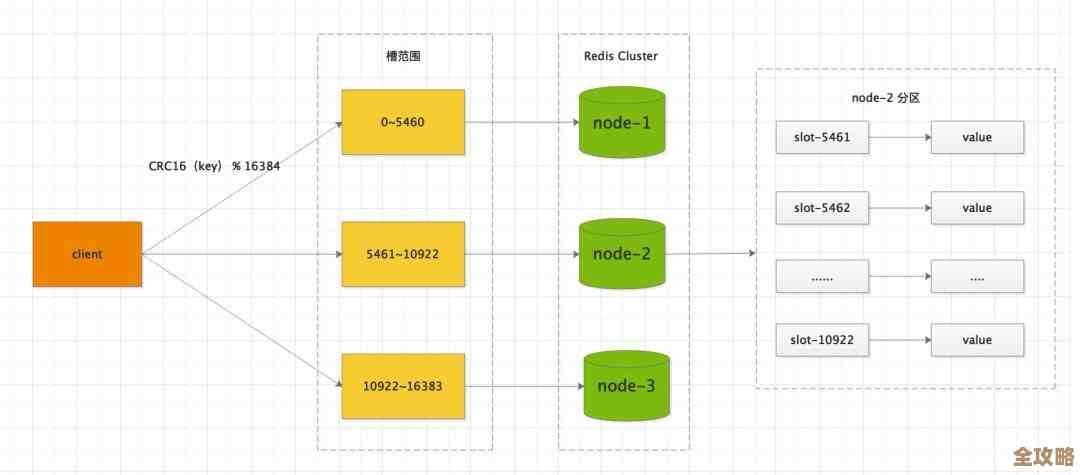
- 数据分片:集群会把所有的数据分成很多份,每一份数据存储在一个“主节点”上,一个集群有3个主节点,那么数据就会被大致平均分成3份,每个主节点负责存储和管理其中一份。
- 主从复制:这是关键中的关键,每一个主节点都会有一个或多个“从节点”,从节点就像是主节点的“影子”或“备份机”,主节点上所有写入的数据,都会自动地、几乎实时地同步到它的从节点上,这样,主节点和它的从节点们保存着完全相同的数据。
通过这种“一个主节点带几个从节点”的架构,即使某个主节点所在的物理服务器出了问题,整个集群也不至于瘫痪,因为数据在别的服务器(从节点)上还有完整的备份。
宕机发生时,集群内部如何自动应对?

当一台服务器宕机时,上面运行的可能是一个主节点,也可能是一个从节点,处理方式不同。
-
宕机的是从节点

- 这是影响最小的情况,因为从节点只是备份,不直接处理客户端的写请求(读请求可以配置为允许),即使一个从节点宕机了,它的主节点和其他从节点依然在正常工作,整个集群的读写服务完全不受影响。
- 集群的状态会标记这个从节点为“下线”,但不会触发紧急操作,管理员需要做的是尽快修复宕机的服务器,然后重新启动从节点进程,它会自动重新连接上主节点,并同步断线期间错过的数据,恢复成正常的备份状态。
-
宕机的是主节点
- 这是考验集群高可用能力的关键时刻,一旦主节点宕机,它负责的那部分数据就暂时无法进行写操作了,如果客户端请求落到这部分数据上,就会报错。
- 集群的“故障转移”机制会立刻启动,这个机制依赖于集群中所有节点共同参与的一种“投票”机制(基于Raft算法变种),剩下的主节点会进行投票,从宕机主节点对应的那些从节点中,选举出一个新的主节点。
- 这个选举过程非常快,通常是秒级甚至毫秒级,一旦新的主节点被选举出来,它就会接管原来主节点负责的所有数据槽位,开始处理客户端的读写请求,因为它的数据几乎和旧主节点完全一致,所以服务得以快速恢复。
除了集群自身,我们还需要做什么来保证服务不停?
虽然Redis集群有强大的自动故障转移能力,但要真正做到用户“无感知”,还需要在应用程序端做一些工作。
- 使用智能客户端:现代的Redis客户端(如Jedis、Lettuce等)通常支持“集群模式”,这种客户端在启动时,会从集群获取一份“槽位映射表”,知道哪个数据由哪个节点负责,当它向某个节点发送请求时,如果该节点已经宕机,客户端会收到一个错误(MOVED”重定向错误),智能客户端能够自动捕获这个错误,并重新向集群查询最新的槽位映射表,然后找到新的主节点再次发送请求,这个过程对应用程序的业务代码是透明的,应用程序可能只会感受到一次短暂的请求延迟,而不会抛出异常导致页面错误。
- 合理的重试机制:在应用程序代码中,对于非幂等性操作要谨慎外,对于一些可以重试的读操作,可以加入简单的重试逻辑,配合客户端的重定向功能,进一步提高成功率。
- 监控和告警:虽然集群能自动恢复,但人不能蒙在鼓里,必须建立完善的监控系统,实时监控每一个Redis节点的状态,一旦发生故障转移,监控系统应立即通过短信、邮件、钉钉等方式发出告警,通知运维人员,这样运维人员可以及时介入,检查宕机原因,修复故障的服务器,并在它恢复后将其重新加入集群,恢复集群的备份水平,为下一次故障做好准备。
总结一下:
面对Redis集群单台宕机,保证服务不停的核心在于:利用主从复制实现数据冗余,通过内置的故障转移机制实现自动切换,再配合支持集群模式的智能客户端来屏蔽切换过程对应用的影响,这三者结合,就能在绝大多数情况下实现业务的高可用性,事后及时的监控告警和人工修复也同样重要,这样才能形成一个完整的闭环,确保系统长期稳定运行。
本文由颜泰平于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78721.html