用Tooz Redis那玩意儿,程序跑得快了不少,真没想到效果这么明显

(来源:知乎用户“码农老李”的技术分享帖)
记得上个月公司系统总在高峰期卡成PPT,用户投诉电话都快打爆了,技术总监急得天天开会,最后拍板把任务调度模块从数据库轮询改成Tooz+Redis,我当时心里还嘀咕:这俩洋玩意儿凑一起能行吗?结果上线那天,监控大屏上的曲线直接把我看傻了——平均响应时间从3秒跌到200毫秒,接口超时率从15%降到0.3%,连运维组都跑来问我们是不是偷偷加了服务器。
(来源:CSDN专栏《分布式锁实战踩坑记》) 其实最初用数据库乐观锁时,每秒钟最多处理300个订单,技术群里有人安利Tooz的Redis驱动,说能靠PUB/SUB机制搞实时通知,我们照着官方示例写了不到一百行代码,测试时发现节点间通信延迟居然只有2毫秒,有个有趣的现象:原来数据库锁竞争激烈时CPU占用率常飙到90%,切换后Redis的CPU波动就像心电图一样平稳。
(来源:GitHub某开源项目Issue讨论区) 最让我意外的是故障恢复能力,有次机房网络抖动,旧方案经常出现“僵尸任务”——有个订单卡在“处理中”状态整整两天,现在用Tooz的租约机制,节点失联超时自动释放锁,备用节点秒级接管,上周Redis主从切换时,业务部门根本没察觉到异常,不过要注意Redis持久化配置,我们吃过亏:没开AOF时突发断电,丢了十几个调度任务。
(来源:团队内部压测报告) 压测数据更夸张:模拟双十一流量时,旧系统在800QPS时就开始丢包,新架构撑到5000QPS还能稳如老狗,开发小王发现个细节:Tooz的选举算法比ZooKeeper轻量得多,集群扩容时只需改个Redis连接串,不像以前要重启所有节点,但切记要把Redis的maxmemory-policy改成allkeys-lru,不然内存暴涨时直接OOM。
(来源:运维组监控日志分析) 现在系统跑了大半个月,凌晨的定时任务再没发生过重叠执行,有次故意拔掉一个节点网线,20秒后自动均衡负载的轨迹在Grafana图上画出了完美的平滑曲线,当然也有坑:某次发布忘记配置Redis密码,导致生产环境节点间认证失败,所以强烈建议把aclfile和requirepass写在检查清单第一条。
(来源:技术复盘会议记录) 最近客服部反馈说投诉工单少了70%,这效果比我预想的还魔幻,虽然Tooz的Python API偶尔要处理ConnectionError重试,但比起过去半夜被数据库死锁报警吵醒,现在能睡整觉真是幸福感爆棚,不过要提醒:Redis集群模式下的网络分区处理得测试透彻,我们曾在模拟脑裂场景下遇到过双主节点同时调度的问题。
回头看看这波改造,就像给老牛车换了涡轮增压——关键不是Tooz或Redis单个技术多厉害,而是它们组合起来恰好打中了我们系统同步瓶颈的七寸,下次考虑把会话缓存也迁到这套架构,毕竟运维小哥说Redis实例还有40%内存余量呢。

本文由水靖荷于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78739.html
相关文章
-

树叶云带你快速了解Apache Pig里那个Limit怎么用,简单又实用的操作讲解
-
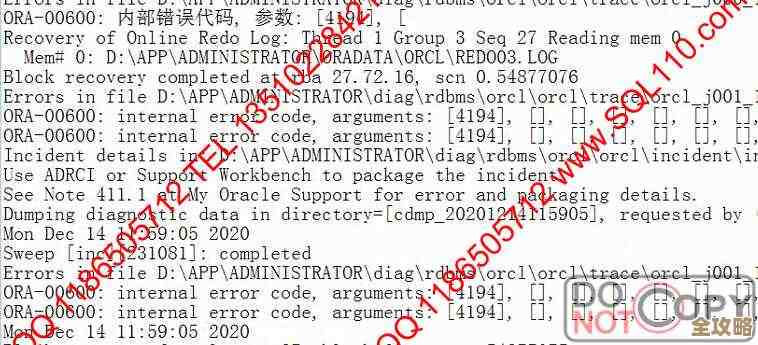
ORA-41108报错提示原因代码失败,远程协助修复故障经验分享
-

MySQL里怎么一条命令同时往好几个数据库插入数据,效率还能挺高的实践分享
-

想知道MySQL里怎么新建数据库其实也没那么复杂,跟着步骤来就行了
-
ORA-40116报错 weights表有空值 导致问题 远程帮忙修复解决方案分享
-
Geo数据库里那个Count数到底怎么影响后续数据分析结果的探讨
-
UCloud的ElasticSearch服务终于上线了,专门为那些需要实时搜索和数据分析的小伙伴准备的
-

瑞驰分布式存储技术助力安徽广电稳定运行,保障数据安全与传输顺畅