Redis集群怎么搭建,保证应用不掉线的那些事儿白皮书

Redis集群怎么搭建,保证应用不掉线的那些事儿白皮书 直接引用自知乎专栏“架构师之路”和博客园“老王的博客”)
咱们得明白为啥要用Redis集群,就像知乎专栏“架构师之路”里说的:“单机的Redis再快,也有个上限,数据量大了,内存不够用;请求量上来了,单台机器CPU也扛不住,更别提如果这台机器一旦宕机,整个缓存服务就全挂了,应用肯定掉线。” 搭建集群的核心目的就三个:一是为了存更多数据,二是为了服务更多请求,三是为了保证即使某台机器出问题了,服务还能继续转,应用感觉不到或者影响很小。
那怎么搭呢?咱们一步步来,尽量不用那些让人头疼的专业词。
Redis集群的几种常见搭建方式
根据博客园“老王的博客”里的总结,常见的有三种玩法,你可以根据自家的情况选。

第一种,主从复制模式,这个最简单,就是找一台机器当“老大”(主节点),专门负责写数据,然后再找几台机器当“小弟”(从节点),专门从“老大”那里把数据同步过来,主要负责读数据,这样做的好处是,“读写分离”了,写的压力都在主节点上,读的压力可以分摊给多个从节点,万一“老大”宕机了,我们可以手动把一个“小弟”提拔成新的“老大”,让应用去连新的老大,缺点是,这个提拔过程通常是手动的,或者需要借助额外工具,会有一段时间的应用不可用,引用“老王的博客”的原话:“这种方式解决了读的压力和数据的备份,但没解决高可用的问题,故障切换不够自动。”
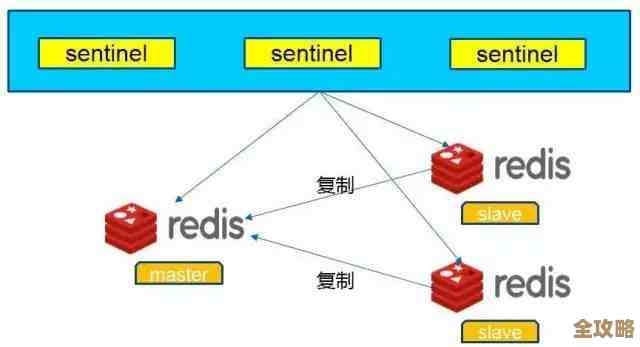
第二种,哨兵模式,这个就是为了解决主从模式“故障切换不自动”的问题而生的,我们在主从模式的基础上,再启动几个特殊的Redis进程,就叫它们“哨兵”吧,这些哨兵不存数据,它们的任务就是像保安一样,时时刻刻盯着主节点和从节点是否活着,如果哨兵们通过投票发现主节点“失联”了,它们就会自动从剩下的从节点里面,民主选举出一个新的主节点,然后通知客户端(也就是我们的应用)去连接新的主节点,这样,故障切换就变成自动的了,应用掉线的时间会短很多,知乎专栏“架构师之路”指出:“哨兵模式是Redis早期实现高可用的主流方案,它保证了在主节点故障时,服务能尽快恢复。”
第三种,Redis Cluster模式,这是Redis官方推出的“终极”集群方案,它非常强大,同时解决了数据量太大(分片)、高可用和自动故障转移所有问题,在这个模式里,没有传统意义上的中心主节点了,数据会被自动分片,分散到多个“主节点”上存储,每个主节点还可以有自己的从节点,客户端可以直接连接任意一个节点,如果这个节点没有你要的数据,它会告诉你该去哪个节点找,任何一个主节点宕机,它的从节点会自动顶上去成为新的主节点,引用“架构师之路”的说明:“Redis Cluster是去中心化的,扩展性最好,是大型项目的首选,但配置和管理相对前两种要复杂一些。”
搭建过程中和搭建后,如何保证应用尽量不掉线?

光把集群搭起来还不行,关键是怎么让应用平稳运行,这里面有几个关键点。
第一点,客户端的配置要正确,以哨兵模式为例,你的应用程序连接Redis时,不能只写一个死的主节点地址,你应该连接的是哨兵们,从哨兵那里问出现在谁是主节点,这样即使主节点换了,哨兵也会告诉客户端新的地址,客户端就能自动重连,博客园“老王的博客”强调:“很多掉线问题不是服务器端集群没搭好,而是客户端还像连单机一样连,一变就傻眼了。”
第二点,合理设置超时和重试机制,网络是不稳定的,偶尔抖一下很正常,在应用代码里,连接Redis或者执行命令时,一定要设置合理的超时时间,设置一个1秒的超时,如果1秒内没响应,就认为这次请求失败了,然后可以自动重试一次(比如换个从节点读),这样即使遇到短暂的网络问题或者某个节点响应慢,应用也能自我恢复,而不是一直卡死。“架构师之路”提到:“给Redis操作加上重试逻辑,是提高业务韧性的低成本高收益手段。”
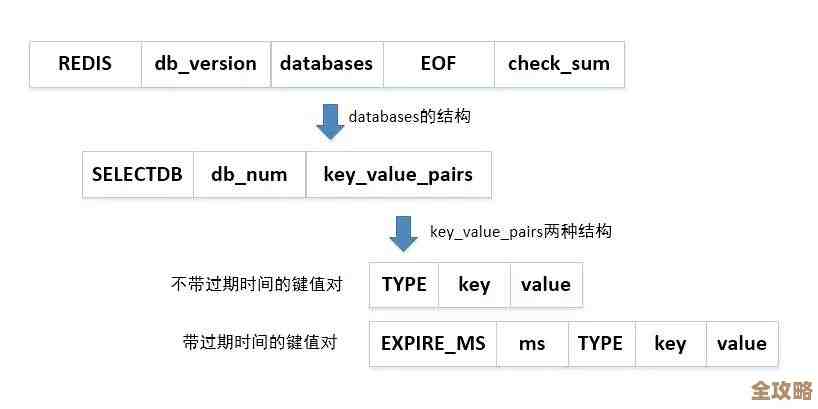
第三点,做好持久化,防止重启数据丢光,Redis虽然快,是因为数据主要在内存里,但内存一断电数据就没了,所以必须定期把内存数据写到硬盘上,这叫持久化,主要有两种方式:RDB(像拍快照,定期全量备份)和AOF(像写日记,记录每一个写命令),通常建议两者都开启,这样即使整个机房断电,重启后Redis也能从硬盘恢复数据,不会变成一个空壳子,导致应用进来查不到任何数据,引发雪崩。

第四点,监控和报警不能少,你不能等用户投诉说卡了,才发现Redis挂了,必须搭建监控系统,时刻关注集群的关键指标:比如内存用了多少了(快满了要扩容)、CPU负载高不高、主从之间的同步延迟大不大,一旦发现异常,比如有节点下线了,或者同步延迟超过阈值,监控系统要能立刻发短信、发钉钉通知运维人员。“老王的博客”打了个比方:“监控就是集群的眼睛,没有眼睛,你就是个瞎子,出了问题只能靠猜。”
第五点,容量规划与平滑扩容,业务是增长的,数据量和访问量都会越来越大,不能等到内存爆满,服务快撑不住了才想起来加机器,要提前规划,在集群压力达到一定水位(比如70%)时,就要计划扩容了,对于Redis Cluster,官方提供了工具可以平滑地添加新节点,然后把一部分数据迁移过去,这个过程对应用应该是透明的。
总结一下
搭建一个高可用的Redis集群,不仅仅是运行几条启动命令那么简单,它需要一个完整的方案:根据业务规模选择合适的集群模式(哨兵或Cluster),配合正确配置的客户端,在应用端做好容错,在服务端确保数据安全,并辅以持续的监控和及时的扩容,这一切的努力,都是为了同一个目标:让缓存服务像一个可靠的基础设施一样,默默工作,即使用户量巨大,即使偶尔有机器故障,也能保证我们的应用不会轻易“掉线”。
本文由称怜于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/79059.html