Redis集群数据丢失问题严重,运维陷入一片混乱和无奈之中

根据多位运维工程师在技术社区分享的真实经历整理,为保护隐私,具体人名与公司名已隐去。)
“那天早上刚到公司,就看见监控大屏上一片红。”一位在某电商平台负责缓存系统的工程师回忆道,“Redis集群的几个节点连接超时,一开始以为是网络波动,重启一下就能好。”这种想法在当时很普遍,因为Redis素以高性能和稳定性著称,偶尔的节点故障在集群模式下理应自动恢复,但这一次,情况完全不同。
根据这位工程师在技术论坛的帖子描述,他们首先尝试重启失联的节点,但节点起来后,数据并没有像预期那样从其他主节点同步过来,反而变成了一个空实例,紧接着,集群的故障转移机制似乎被触发,但过程极其混乱。“就像一群无头苍蝇,”他写道,“原本是主节点的实例,在重启后有的自称是从节点,有的甚至状态显示为‘失败’,整个集群的拓扑结构乱成一锅粥。”更糟糕的是,应用服务开始大面积报错,因为大量的请求无法找到正确的数据,用户界面要么显示空白,要么提示系统错误,客服电话瞬间被打爆,技术团队的压力陡增。
另一位来自一家在线教育公司的运维人员分享了类似的遭遇,他们的集群部署在云上,使用了Redis的官方集群方案,事故起源于一次常规的云平台硬件维护,导致一个主节点所在物理机被迁移,按照设计,该主节点的从节点应该晋升为新的主节点,但悲剧发生了。“晋升是成功了,但我们很快发现,刚刚晋升的主节点里,缺失了近半个小时的数据。”他在博客中无奈地写道,这丢失的半小时数据,包含了大量用户的上课记录、答题进度和实时互动消息。“用户反馈像雪片一样飞来,我们却无能为力,你不可能对着一个学生说‘系统把你刚才的答题记录弄丢了,你能再答一遍吗?’”

问题的严重性在于,这种数据丢失并非个案,且原因复杂多样,远非简单的“节点宕机”可以解释,综合多位一线运维人员的反馈,问题根源主要集中在几个方面:
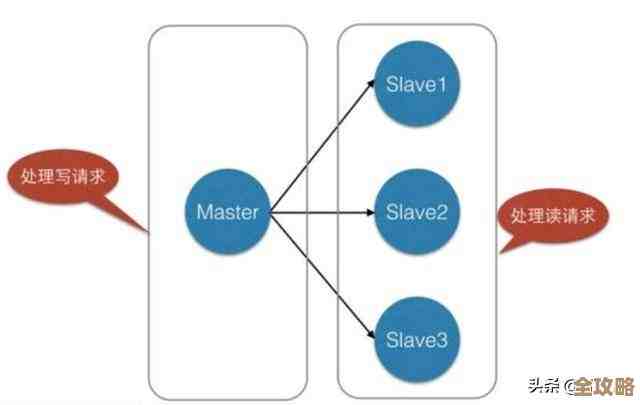
第一,脑裂问题(Split-brain)是元凶之一,当集群内部的网络出现分区,比如因为交换机故障或网络延迟陡增,可能导致集群被分割成两个或多个无法通信的小团体,每个小团体都可能认为其他团体的节点已经下线,从而自行选举出新的主节点继续提供服务,当网络恢复时,两个都拥有“主节点”身份的数据分区相遇,就会导致数据冲突和混乱,Redis集群的处理策略可能无法完美合并所有数据,最终会根据配置强制某个分区降级,并丢弃其在此期间写入的数据。“我们那次就是遇到了短暂的网络分区,”一位金融行业的工程师补充道,“虽然只持续了十几秒,但已经足够让集群‘精神分裂’,最终我们损失了部分交易风控数据,排查过程苦不堪言。”
第二,异步复制带来的固有风险,在Redis集群中,主节点将数据复制到从节点是异步进行的,这意味着,当主节点接收到一个写请求并确认成功后,它可能还没来得及将这份数据同步给它的从节点就突然宕机了,即使从节点迅速晋升为主节点,它上面也没有那份最新的数据,之前确认成功的写操作,对于客户端来说就“凭空消失”了。“我们严格测试过故障转移时间,能控制在秒级,”一位资深DBA在技术沙龙上坦言,“但数据丢失就发生在那毫秒之间,你无法要求异步复制变成同步,那会极大牺牲性能,这几乎是一个无解的矛盾。”

第三,运维操作中的陷阱,一些看似安全的运维指令,在特定场景下可能成为灾难的导火索,在某些早期版本中,如果误操作执行了CLUSTER FAILOVER命令,或者在进行集群扩容、缩容(resharding)时发生意外中断,都可能引发不可预知的数据一致性问题,一位运维工程师提到,他们曾因为在业务高峰期间尝试迁移一个巨大的Key,导致集群响应激增,最终触发了某个节点的OOM(内存溢出)而被系统杀死,连锁反应导致小范围的数据丢失。
第四,配置与监控的不足,很多团队在部署集群时,可能并未充分理解所有配置参数的含义。min-replicas-to-write(要求至少有多少个从节点同步成功,主节点才可写)这类可以增强数据耐久性的配置,往往因为担心影响性能而未被启用,对于集群状态的监控往往停留在“节点是否存活”的层面,而对复制延迟(replication lag)、集群配置纪元(config epoch)的一致性等更深层次的指标监控不足,导致无法在问题萌芽阶段发出预警。
当数据丢失真的发生后,运维团队面临的局面是绝望的。“你看着那些丢失的键,一点办法都没有,”一位工程师形容道,“从节点的数据是旧的,持久化文件(AOF/RDB)也是旧的,你能做的只有从备份恢复,但这意味着要回滚整个集群到几小时甚至前一天的状态,期间的所有新数据全都得舍弃,业务根本不可能接受。”这种两难的境地,让运维人员陷入了巨大的无奈和压力之中。
这些真实的案例表明,Redis集群并非一个“设置好就高枕无忧”的系统,它虽然提供了分布式能力和一定程度的可用性,但在数据的强一致性保证上存在短板,对于不能接受任何数据丢失的业务场景,运维团队必须投入巨大的精力进行深度监控、制定精细的容灾预案,并承受着性能和数据安全之间艰难权衡所带来的持续压力,正如一位总结者所说:“用了集群,只是把单点故障的风险,转换成了更复杂、更隐蔽的分布式故障风险,运维的挑战,不是变小了,而是换了一种更磨人的方式出现了。”
本文由寇乐童于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/79376.html