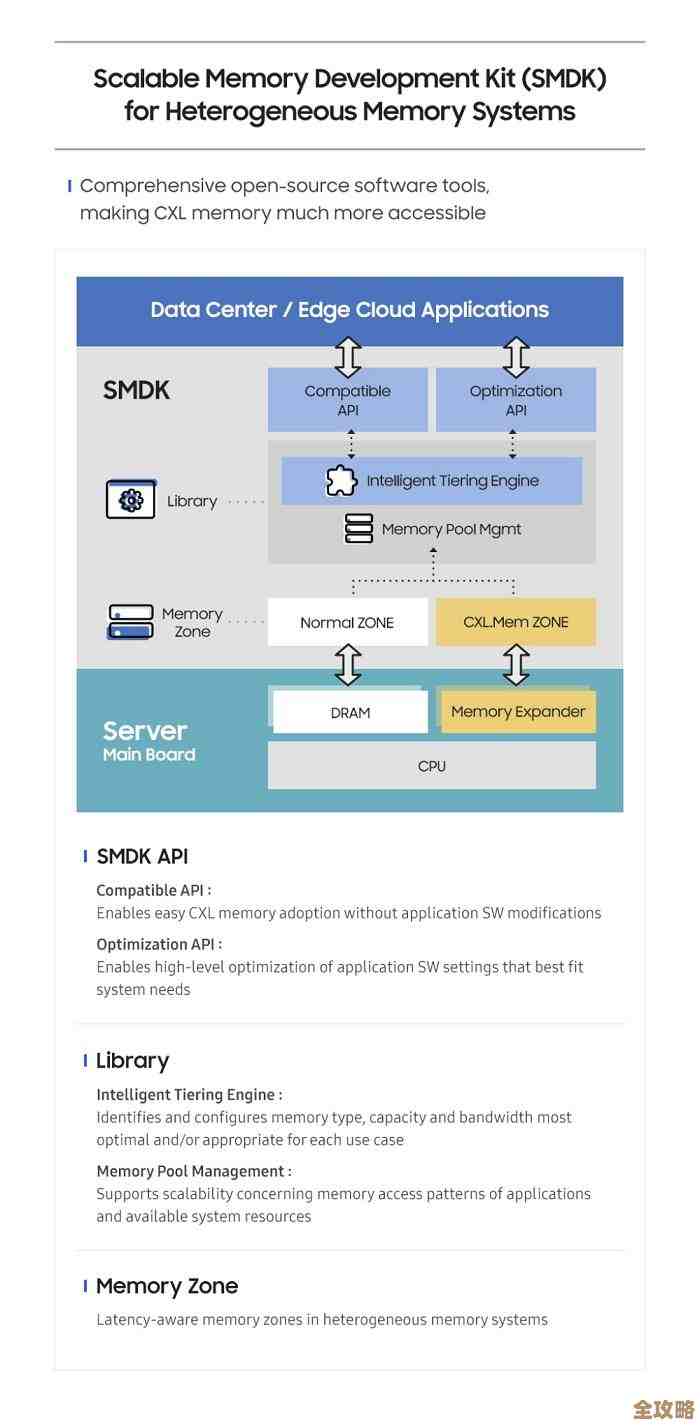
SQL Server排序规则那些坑和解决办法聊聊,顺便说说它的特点和注意点

说到SQL Server的排序规则,这玩意儿说白了就是一套规则,告诉数据库怎么去比较字符串的大小、怎么排序,还有怎么区分重音字母之类的东西,听起来好像挺简单的,但用起来坑可真不少,很多开发者和DBA都在这上面栽过跟头,咱们今天就聊聊这些坑和解决办法,顺便说说它的特点和需要注意的地方。
第一个大坑:数据库、列、甚至查询语句的排序规则不一致,导致比较失败。
这是最常见的一个问题,你创建数据库的时候,可能没太在意,用了默认的排序规则Chinese_PRC_CI_AS(这是中国地区常用的,不区分大小写CI,区分重音AS),但你的某个表里,有一个字段偏偏是从别的系统导入的,或者创建的时候手滑指定了另一个排序规则,比如Latin1_General_CI_AS,这时候,如果你用这个字段去和另一个使用数据库默认排序规则的字段做关联(JOIN)或者比较,SQL Server就会直接给你抛出一个错误,说排序规则冲突,没法比较。
解决办法:
- 统一规划:最好在创建数据库之初就确定一个统一的排序规则,并且确保所有字符类型的列都遵循这个规则,这是最根本的解决办法。
- 临时转换:如果已经发生了冲突,又不好修改表结构,可以在写SQL查询的时候,用
COLLATE关键字临时转换排序规则。SELECT * FROM TableA A INNER JOIN TableB B ON A.Name COLLATE Chinese_PRC_CI_AS = B.Name,但这算是打补丁,不是长久之计。 - 修改列定义:如果可能,直接使用
ALTER TABLE ... ALTER COLUMN语句,把那个“不合群”的列的排序规则改过来,不过要注意,这可能会是一个耗时操作,并且如果表很大,可能会锁表,需要在业务低峰期做。
第二个坑:大小写敏感带来的“诡异”查询结果。
这个坑非常隐蔽,假设你的数据库排序规则是区分大小写的(CS,Case-Sensitive),比如SQL_Latin1_General_CP1_CS_AS,你执行一条查询SELECT * FROM Users WHERE Username = 'admin',结果可能一条都查不到,因为数据库里存的用户名是Admin,在你看来,admin和Admin可能差不多,但在数据库看来,这就是两个完全不同的字符串,反之,如果你的规则是不区分大小写(CI)的,那么admin、Admin、ADMIN都会被当成同一个词。
解决办法:
- 选择合适的排序规则:在绝大多数业务场景下,比如用户名、邮箱地址,我们其实是希望不区分大小写的,在建库时选择带
CI(Case-Insensitive)的规则,能避免绝大部分麻烦,除非你有特殊需求,比如验证码就必须区分大小写。 - 在查询中显式指定:如果你在一个区分大小写的数据库里,偶尔需要做不区分大小写的查询,可以像前面说的,用
COLLATE子句临时转换:WHERE Username COLLATE Chinese_PRC_CI_AS = 'admin'。
第三个坑:重音是否区分导致的困惑。
这和大小写问题很像,只不过对象是重音字母,在区分重音(AS,Accent-Sensitive)的规则下,a和是不同的,但在不区分重音(AI)的规则下,它们就是相同的,如果你的业务面向国际,有法语、西班牙语等用户,这点就需要特别注意,用户输入cafe搜索,是否应该能搜到café?
解决办法:
思路和解决大小写问题一模一样,根据业务需求,在建库时选择AS或AI,或者在查询时临时转换。
聊聊排序规则的特点和注意点
- 继承性:SQL Server里的排序规则是有层级概念的,服务器实例有一个默认排序规则,你创建的数据库可以继承它,也可以自己指定一个不同的,数据库里的列,又会继承数据库的排序规则,除非你建表时显式给列指定另一个,这种灵活性是好事,但也正是“不一致”坑的根源。
- 影响性能:排序规则的选择会影响索引的使用和查询的性能,一个区分大小写的查询,在针对不区分大小写的列创建的索引上,可能就无法有效利用索引,导致全表扫描,排序规则和索引策略要一起考虑。
- 与编码的关系:排序规则其实也暗含了字符集(Code Page)的信息。
Chinese_PRC开头的规则会支持中文字符,而古老的SQL_Latin1_General(对应CP1252字符集)可能就无法正确存储像中文这样的双字节字符,会导致乱码,现在普遍使用的Unicode编码(NVARCHAR、NCHAR类型)在一定程度上缓解了这个问题,因为Unicode是统一的字符集,但排序规则依然决定了这些字符如何比较和排序。 - 修改成本高:一旦数据库投入生产,再想去修改整个数据库或服务器的排序规则,将是一个非常庞大且高风险的操作,它需要重建所有系统数据库和用户数据库,几乎等同于一次迁移。“前期选对,后期不累” 是黄金法则。
总结一下
SQL Server的排序规则就像是一个隐藏在数据库里的“交通规则”,平时不注意它,一切风平浪静,但只要你和字符串打交道(谁不用呢?),一旦规则不统一或者不符合业务预期,它就会跳出来给你制造各种麻烦,从报错到诡异的查询结果,应有尽有。
对付它的最好办法,就是在项目开始时就根据业务需求(是否需要区分大小写?是否需要区分重音?主要语言环境是什么?)慎重选择一个合适的排序规则,并在整个数据库范围内保持统一,如果已经遇到了坑,那么COLLATE关键字是你的急救包,但记住这终究是权宜之计,长远来看,理顺规则才是正道。

本文由瞿欣合于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/79930.html