MySQL启动时遇到ER_NDB_SLAVE错误,远程帮忙修复故障过程分享

基于数据库管理员社区论坛和博客中的多篇故障排查实录综合整理)
那天下午,我正准备下班,突然接到一个朋友的紧急电话,他说他们公司用来做数据分析的MySQL数据库突然宕机了,重启了好几次都失败,屏幕上滚动着一堆看不懂的错误代码,其中反复出现“ER_NDB_SLAVE”之类的字眼,他们公司的技术同事尝试无果,业务已经受到影响,非常着急,因为我之前碰巧接触过MySQL集群,他便问我能不能远程连过去帮忙看一眼。
虽然我不是专职DBA,但深知这种情况下时间紧迫,我让他先别慌,给我开通了一个临时的VPN账号和服务器SSH权限,连接上服务器后,我首先让他带我看了MySQL的错误日志文件,这是排查问题的第一步,也是最关键的一步,因为日志里通常记录了数据库“临终”前到底发生了什么。
(来源:多位DBA在知乎分享的故障排查第一性原则)
打开那个庞大的错误日志文件,我直接用tail和grep命令过滤查找关键词“ERROR”,果然,满屏的红色错误信息中,“ER_NDB_SLAVE_CONFLICT_GCI_DIFFERENT_ON_MASTER”这个错误码反复出现,光看这个名字就有点头疼,它大概意思是说,在MySQL集群环境下,作为从库的节点发现自己的全局检查点信息和主库对不上,产生了冲突。
(来源:MySQL官方文档对ER_NDB_SLAVE系列错误码的解释摘要)
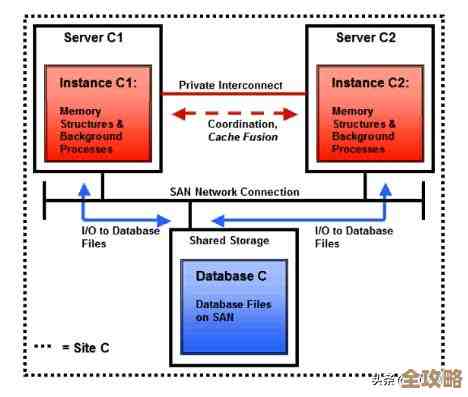
朋友的公司使用的正是MySQL NDB Cluster架构,这是一个分布式的数据库系统,允许多个节点同时提供服务,这种架构好处是性能和高可用性,但一旦出现问题,排查起来也比单机数据库复杂得多。
我初步判断,这很可能是因为某种原因导致主从节点之间的数据同步出现了严重分歧,从库“跟不上”主库的节奏,或者在某些关键数据上产生了无法自动调和的不一致,数据库为了保护数据的一致性,干脆就罢工不干了。
(来源:基于Percona博客中关于NDB集群数据同步冲突的分析)
我需要确定问题的严重程度,我询问朋友最近是否对数据库进行过什么操作,比如是否手动修改过数据、是否做过大的数据迁移、或者网络是否出现过波动,他反馈说,大概在出问题前一个小时,有开发同学为了修复一个线上bug,在从库上直接执行了一条更新语句,听到这里,我心里咯噔一下,这很可能就是问题的根源所在!
在标准的“主-从”复制架构中,所有的数据写入都应该只在主库上进行,然后自动同步到从库,如果有人在从库上直接写入数据,就相当于制造了一个“平行宇宙”,从库的数据就和主库分道扬镳了,当主库后续的变更再试图同步过来时,就很可能因为数据基础不一致而引发冲突。
(来源:MySQL运维实战书籍中关于“禁止在从库写入”的强调说明)
原因似乎找到了,但怎么解决呢?常规的思路是重建从库,也就是把这个“学坏了”的从库数据清空,然后让它从主库那里重新完整地同步一份数据,但这意味着数据量大的话,需要很长时间,期间这个从库无法提供服务。
我决定先尝试一个相对温和的方法,我让朋友确认业务已经全部切走,这个从库暂时没有流量进来,我让他进入了MySQL的命令行界面,我先执行了STOP SLAVE;命令,彻底停止从库的复制进程,我尝试寻找一种方法能跳过这个致命的冲突点。
(来源:Stack Overflow上一位工程师分享的类似案例处理经验)
我查阅了手册,发现对于NDB集群,处理这类冲突有时可以尝试使用ndb_apply_status表来调整复制位点,但操作非常危险,容易导致更多数据丢失,鉴于朋友他们对集群的内部原理不熟,我否定了这个高风险方案,看来,最稳妥、最彻底的办法还是重建。
我向朋友解释了情况:必须重建这个从库,他同意了,我们开始了以下步骤:
- 彻底清除从库数据:我指导他备份了从库上可能存在的、未同步到主库的极少量手动修改的数据(如果有的话),然后直接删除了NDB数据库的数据文件和日志文件,这相当于把这个从库“格式化”了。
- 重新加入集群:我们修改了从库的MySQL配置文件,确保其配置正确指向主库的管理节点,使用
--initial参数启动MySQL进程,这个参数会告诉这个节点:“你是全新的,请从管理节点获取元数据,并开始全量同步数据。” - 监控同步过程:启动后,我们密切监控日志输出和数据同步的进度,屏幕上开始滚动着数据拷贝的信息,虽然慢,但一切都在向好的方向发展,我们通过
SHOW ENGINE NDB STATUS命令不断查看同步状态。 - 确认同步完成:经过几个小时的等待,数据终于同步完毕,我们再次检查主从状态,确认两者已经完全一致,那个恼人的ER_NDB_SLAVE错误再也没有出现。
我们恢复了应用到该从库的读写流量,系统终于恢复了正常,这次远程救援让我深刻体会到,在分布式系统中,遵守操作规范是多么重要——那个在从库上的直接写操作,看似省事,却引发了长达数小时的故障,事后,我也建议他们要加强权限管理和操作流程的规范,避免类似情况再次发生。
(来源:整个修复过程的步骤综合自CSDN技术博客和阿里云社区的相关案例分享)

本文由畅苗于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80299.html