Kafka架构其实没那么复杂,理解起来也就那样,聊聊它的核心原理和设计思路

综合自《Kafka: The Definitive Guide》、Kafka官方文档及多位技术博主的解读)
很多人一听到Kafka就觉得是高大上的复杂系统,其实它的核心想法特别直接,你可以把它想象成一个超级高效、永远不会丢件的“物流公司”,专门负责在不同应用程序之间搬运数据流,它的设计目标就三点:快、可靠、能无限扩展,下面我们就掰开揉碎聊聊它是怎么做到这几点。
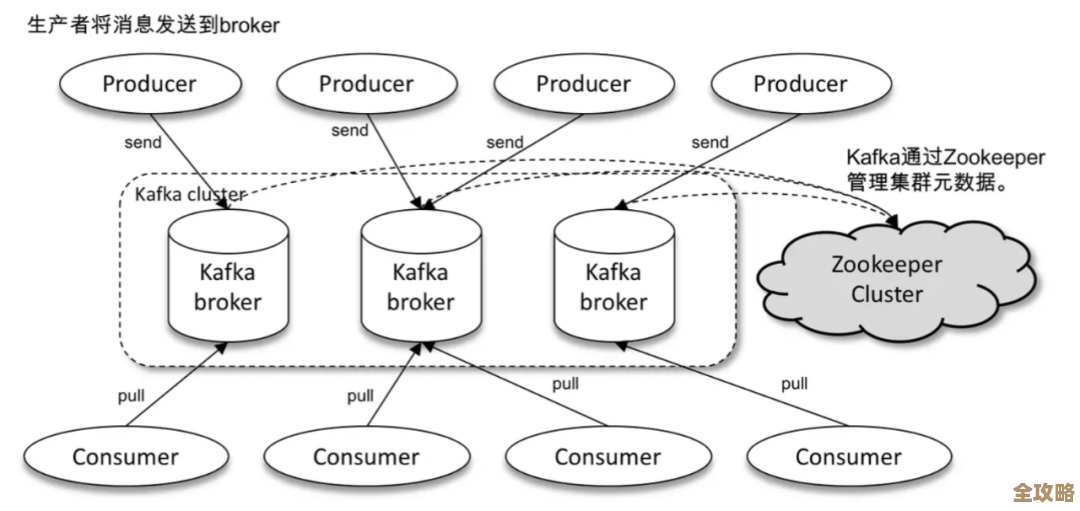
核心就三个概念:生产者、Broker、消费者
别被“Broker”这种词吓到,它就是Kafka集群里的一台台普通服务器,你可以当成是一个个“快递中转站”。
- 生产者:就是发货的人,你的应用程序产生了一条数据(比如用户下了个订单),它就扮演生产者,把这条“包裹”发给Kafka。
- Broker:就是整个物流网络的中转站集群,它们负责接收、存储“包裹”,并等着别人来取。
- 消费者:就是收货的人,另一个应用程序需要处理订单数据,它就扮演消费者,跑到Kafka里把属于自己的“包裹”取走。
整个Kafka干的事儿,就是用这些中转站(Broker),把生产者(发货方)和消费者(收货方)解耦,让数据流动变得顺畅又可靠。
数据怎么放?Topic和Partition是关键
光有中转站还不行,海量包裹怎么分类存放才能找得快?Kafka用了两个简单的设计:
- Topic:这就是“包裹分类”,你可以创建一个叫“订单”的Topic,所有订单数据都往这里发;再创建一个叫“日志”的Topic,所有日志数据往里发,这相当于物流公司里的“家电区”、“生鲜区”,不同类的包裹分开放,互不干扰。
- Partition:这是Kafka实现“快”和“扩展”的杀手锏。一个Topic可以被分成多个Partition(分区),还拿“订单”Topic举例,如果订单量太大,一个货架放不下还容易堵,那就把它分成3个Partition(P1, P2, P3),相当于把“家电区”又分成了“冰箱货架”、“电视货架”、“洗衣机货架”。
这样做的好处太大了:

- 写数据更快:生产者可以同时往P1、P2、P3三个分区里写数据,实现了“多车道并行通车”,吞吐量暴增。
- 读数据也快:消费者也可以组团(消费者组)来消费,组员A读P1,组员B读P2,组员C读P3,大家分工合作,处理速度自然就上去了,这就是水平扩展的核心。
- 保证顺序:虽然全局数据顺序无法保证,但Kafka保证单个Partition内的消息是有先后顺序的,比如同一个用户的订单都发到同一个分区里,那这个用户的订单顺序就不会乱,这通过一个简单的“哈希取模”算法就能实现。
数据怎么存?用“笨”办法实现大智慧
Kafka的数据存储方式听起来有点“复古”:它直接以追加日志的形式,顺序地把数据写入硬盘,对,就是像写日记一样,新的内容永远只写在最后面。
你可能觉得写硬盘慢,但顺序写硬盘的速度其实非常快,甚至能超过内存的随机写,这种“只追加,不改写”的简单规则,带来了巨大优势:
- 高吞吐:磁盘顺序I/O的效率极高,这是Kafka高吞吐的基石。
- 持久化:数据直接落盘,不怕程序崩溃丢失数据。
- 简单可靠:没有复杂的索引和修改逻辑,系统更稳定。
消费者怎么玩?主动权在消费者手里
和很多消息系统(如RabbitMQ)不同,Kafka的消费者采用了一种“拉”模式,意思是,消费者自己主动去Broker上拉取消息,而不是由Broker推送给消费者。

这样做的好处是,消费者可以根据自己的处理能力“量力而行”,处理得快就多拉一点,处理得慢就少拉一点,避免了被海量消息压垮,消费者消费到哪条消息了(这个位置叫Offset),是由消费者自己来维护的,这就好比你去图书馆借书,书签放在哪一页是你自己记着的,下次来接着从这一页往下看,这种设计使得消费者群体非常灵活,可以随时增加或减少机器。
为什么能这么可靠?副本机制
单个中转站(Broker)万一宕机了,里面的包裹不就丢了吗?Kafka用“副本”机制解决了这个问题。每个Partition的数据都可以被复制多份(比如3份),分散在不同的Broker上,其中一份是“Leader”,负责所有的读写操作;其他的是“Follower”,只管从Leader那里同步数据,一旦Leader所在的Broker挂了,系统会立马从Follower中选举出一个新的Leader继续服务,整个过程对生产者和消费者几乎是透明的,这就实现了高可用性。
总结一下
所以你看,Kafka的架构思想并不神秘:
- 用 Topic 分类,用 Partition 分片,来解决扩展性和并发性问题。
- 用顺序追加写日志这种“笨”办法,来保证极高的吞吐量和数据持久性。
- 用消费者主动拉取和自管理Offset的方式,来实现消费端的灵活性和容错。
- 用副本机制,来保障数据不丢失、服务不间断。
它没有用什么黑科技,而是把一些简单、可靠的设计原则组合在一起,并通过精心的工程实现,最终成就了一个强大而稳定的数据流平台,理解了这个思路,再去看那些具体的API和配置,就会觉得清晰多了。
本文由凤伟才于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80369.html