Redis怎么精准对接神通数据库,适配细节和实现思路聊聊

把Redis当作神通数据库的“超级缓存”
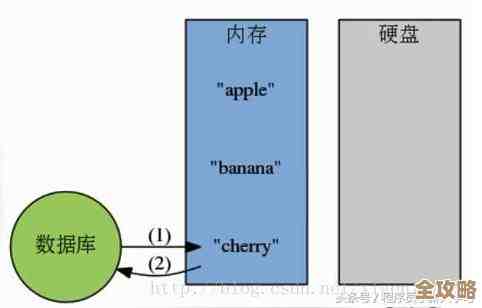
最常用、也是最根本的思路,就是把Redis放在神通数据库的前面,当作一个缓存层来用,这样,应用程序在读取数据的时候,不是每次都直接去敲神通数据库的门,而是先问问Redis:“你这儿有我要的东西吗?”如果Redis有(这叫做缓存命中),就直接从内存里高速返回数据,又快又省力,如果Redis没有(这叫做缓存未命中),应用程序再去神通数据库里把数据取出来,一方面返回给用户,顺手在Redis里也存一份,下次再来问就直接从Redis拿了。
这个思路听起来简单,但里面有几个关键的细节需要处理好,否则不但帮不上忙,还可能添乱。
关键细节一:数据同步,保证两边数据一致
这是最核心的挑战,你想想,如果应用程序在神通数据库里修改了某条数据(比如把商品库存从100改成了90),但Redis里存的还是旧的100,那下次有用户来查询,看到库存还是100,这不就出问题了吗?我们必须想办法让Redis里的数据和神通数据库里的数据保持一致。
这里有几种常见的做法:
-
主动更新(写后更新):这是最直接的办法,只要应用程序对神通数据库执行了写操作(增、删、改),在操作成功之后,立刻、马上也去更新一下Redis里对应的数据,更新了数据库的用户信息,紧接着就执行一条Redis命令,把缓存里的旧用户信息覆盖掉,这种做法能最大程度保证数据的实时一致性。
- 注意事项:这个“立刻更新”的操作必须放在同一个事务里,或者至少保证数据库更新成功了再去更新Redis,如果数据库更新失败了,那肯定不能去动Redis,反过来,如果数据库更新成功,但更新Redis失败了,就会导致数据不一致,所以这里需要一些错误处理和重试机制。
-
主动删除(写后删除):要更新的数据可能很复杂,重新从数据库查一遍再写入Redis的成本比较高,这时候可以采用一种更“偷懒”但同样有效的方法:在写完数据库后,不更新Redis,而是直接把Redis里对应的旧数据删掉,这样,下一个请求来读取这个数据时,发现Redis里没有(缓存未命中),就会自己去数据库里取最新的数据,然后重新塞回Redis,这种方法保证了下次读取一定能拿到最新数据,但代价是会增加一次缓存未命中的请求。

-
设置过期时间:这是一种被动的兜底策略,我们在往Redis里存数据的时候,就给每一条数据设置一个合理的过期时间(TTL),比如5分钟或30分钟,这样,即使因为某些极端情况导致数据不一致,这条旧数据最多也只在Redis里“存活”几分钟,时间一到就会被自动清理掉,下一个请求又会从数据库拉取最新数据,这个方法不能解决实时一致性问题,但能防止数据长时间不一致。
在实际项目中,我们往往会混合使用几种策略,对一致性要求极高的核心数据,采用“写后立即更新或删除”;对一致性要求不那么高的数据,可以只设置一个较短的过期时间。
关键细节二:缓存哪些数据?怎么设计键名?
不是神通数据库里所有数据都适合放进Redis,我们会把那些读多写少、计算成本高、且相对稳定的数据放进去。
- 用户的基本信息(除非用户正在修改)。
- 商品的分类列表、热门商品信息。
- 网站的系统配置、公告等。
在设计存到Redis里的键名时,要有一套清晰的规则,避免混乱,存用户信息可以用 user:用户ID 这样的格式,存商品信息用 product:商品ID,这样一目了然,也便于管理和批量操作。

关键细节三:如何防止缓存被“击穿”和“雪崩”?
这都是高并发场景下可能会遇到的问题。
- 缓存击穿:指的是某个非常热点的数据突然过期了,此时有海量请求同时涌来,都发现缓存失效,于是全部直接打到神通数据库上,数据库压力陡增,解决办法可以是设置“永不过期”(但需配合主动更新策略),或者使用互斥锁,只让一个请求去数据库加载数据,其他请求等待。
- 缓存雪崩:指的是同一时间有大量的缓存数据过期,导致所有对这些数据的请求都涌向数据库,解决办法是给不同的数据设置一个随机的过期时间,避免它们在同一时刻集体失效。
实现上的技术选择
在代码层面实现上述思路,主要有两个方向:
- 在应用层代码中手动实现:这是最灵活的方式,程序员在写业务逻辑的时候,在每一个需要读写数据的地方,都显式地加上操作Redis和神通数据库的代码,先查Redis -> 没有 -> 查神通数据库 -> 写入Redis -> 返回数据,这种方式对代码侵入性强,但控制粒度最细。
- 使用第三方缓存框架(如Spring Cache):如果你用的是Java生态(神通数据库常应用于国产化Java项目),Spring框架提供的缓存抽象(
@Cacheable,@CacheEvict等注解)可以大大简化工作,你可以通过配置,告诉框架哪些方法的结果需要缓存到Redis里,什么时候该清除缓存,框架会自动帮你完成“查缓存-查数据库-回填缓存”的流程,代码会干净很多,你需要做的就是把神通数据库的数据源和Redis的客户端配置好。
总结一下
精准对接Redis和神通数据库,本质上是一个架构设计问题,你需要根据自己业务的数据一致性要求、读写比例、性能瓶颈来选择合适的策略组合,核心是牢记Redis的缓存定位,精心设计数据同步方案,并预防好高并发下的潜在风险,通过这种“内存+磁盘”的混合架构,你的应用既能享受到Redis带来的飞速响应,又能拥有神通数据库提供的稳定可靠的数据持久化能力。
本文由度秀梅于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80560.html