Redis模型那些事儿,深入挖掘背后的原理和细节分析

Redis之所以能如此快速,其核心在于它是一个基于内存的、单线程架构的键值数据库,我们先从最根本的“单线程”模型说起,很多人一听到单线程,可能会觉得性能瓶颈会很大,但Redis恰恰利用这一点实现了极高的性能,根据Redis官方文档《Redis持久化》和《Redis内部实现》部分的解释,Redis的单线程指的是其网络I/O和执行命令的核心模块(通常指的是主线程)是单个线程处理的,这意味着,在任何一个瞬间,Redis只会做一件事,而不是同时做多件事。
单线程为什么快呢?关键在于它完全避免了多线程环境中常见的竞争条件和不必要的上下文切换带来的性能损耗,上下文切换是操作系统为了模拟多任务而进行的操作,当CPU从一个线程切换到另一个线程时,需要保存当前线程的状态并加载下一个线程的状态,这个过程是有成本的,线程越多,竞争共享资源(比如内存中的数据)就越激烈,为了保证数据正确性而引入的锁机制也会让性能下降,Redis的单线程模型从根本上杜绝了这些问题,使得代码更简单,执行路径更直接。
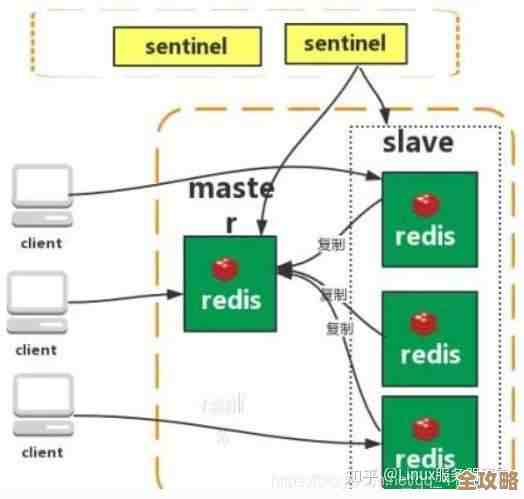
但这引出了一个新问题:单线程如何应对海量的并发连接?这里的秘密在于,Redis使用了I/O多路复用技术,根据《Redis设计与实现》一书中的描述,I/O多路复用机制(在Linux下通常是epoll)允许单个线程监视多个网络连接 socket,当某个socket有数据到达(比如一个新的客户端命令请求)时,epoll会通知Redis的主线程,主线程再去读取和处理这个请求,这样,这个单线程就不会傻傻地阻塞在某个连接的等待上,而是高效地轮询哪些连接已经准备好了数据,从而实现了用少量资源处理大量并发连接的能力,这就像是一个高效的餐厅服务员,他不是一直站在一个等菜的客人旁边,而是在后厨和大厅之间巡视,哪桌的菜好了就立刻端上去。
我们深入看看Redis是如何存储数据的,Redis的键值对存储在一个巨大的“字典”(哈希表)中,但为了平衡性能和内存占用,这个字典底层使用了两种数据结构:哈希表和跳表,对于普通的键值对,哈希表提供了平均O(1)时间复杂度的查找效率,而对于需要排序的集合(Sorted Set)这类数据,Redis则使用了跳表(SkipList)和哈希表结合的方式,跳表是一种通过建立多级索引来加速查找的数据结构,它使得范围查询等操作变得非常高效。
Redis作为一个内存数据库,最让人担心的就是数据丢失问题,为此,它提供了两种主要的持久化机制:RDB和AOF,根据《Redis持久化》文档,RDB可以理解为给内存中的数据拍一张快照,然后保存到一个压缩的二进制文件中(dump.rdb),这个过程可以定期执行,它的优点是文件紧凑,恢复速度快,缺点是可能会丢失最后一次快照之后的数据。
AOF(Append Only File)则是另一种思路,它会把Redis服务器执行的每一个写命令都记录到一个日志文件中,当服务器重启时,会重新执行一遍AOF文件中的所有命令来恢复数据,AOF的优点是数据安全性高,通常最多丢失一秒的数据(如果配置为每秒同步一次),缺点是文件体积会比RDB大,而且恢复速度慢,在实际生产中,通常会同时开启RDB和AOF,用RDB做冷备份,用AOF保证数据安全性。
不得不提的是Redis丰富的数据类型,它不仅仅是简单的字符串键值对,还提供了列表(List)、集合(Set)、有序集合(Sorted Set)、哈希(Hash)等,这些数据类型并非凭空想象,而是为了满足不同的应用场景,列表可以用于实现消息队列,集合可以用于存储用户标签并进行交集、并集运算(比如共同好友),有序集合则是排行榜功能的天然实现,每一种数据类型在Redis内部都有其特定的编码方式,Redis会根据存储数据的数量和大小,自动选择最节省内存的编码格式,这个细节充分体现了Redis在内存优化上的匠心独运。
Redis的高性能并非偶然,而是其简洁的单线程模型、高效的I/O多路复用、精心设计的数据结构以及灵活的持久化策略共同作用的结果,理解这些背后的原理,能帮助我们更好地使用Redis,并在出现问题时进行有效的排查和优化。

本文由水靖荷于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80646.html