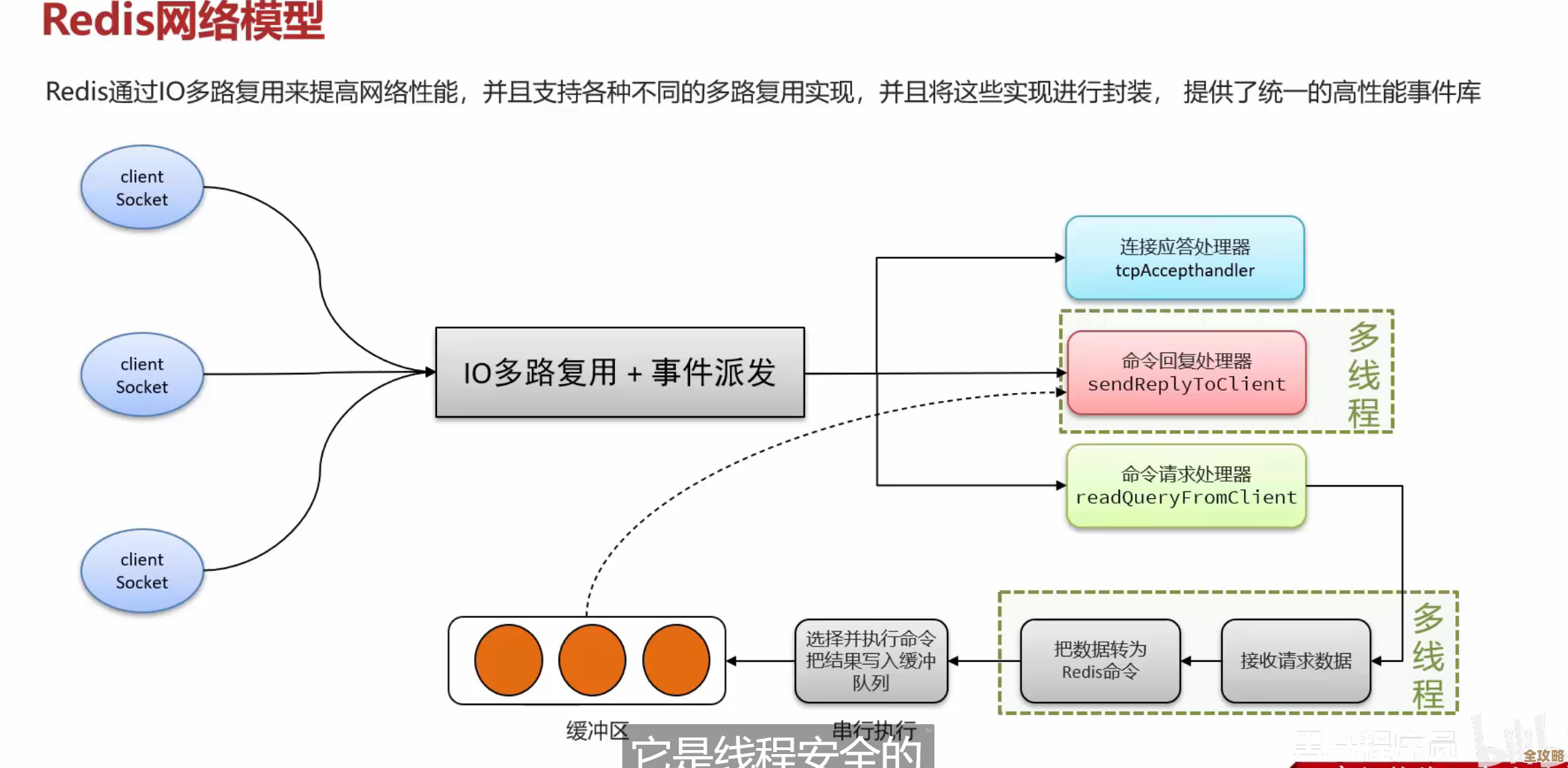
用PHP抓取新浪微博内容然后存数据库,怎么弄比较简单实用

要搞一个用PHP抓取新浪微博内容存进数据库的东西,说简单也简单,说复杂也复杂,因为微博的反爬虫很厉害,完全不走弯路的话,不太现实,但我们可以找一个相对简单实用的路子,核心思路就是:不直接硬刚微博的网页或APP接口,而是利用一些现成的、能间接获取数据的方法。
最省事的办法,可能就是去找第三方工具或者聚合数据平台,聚合数据”这类网站,它们已经帮我们把各种API整合好了,其中可能就包括微博的,你只需要去它们网站注册个账号,然后购买或者试用它们提供的微博API服务,这样做最大的好处是,你完全不用去研究微博那套复杂的登录、加密、签名机制,那些反爬虫的关卡平台已经替你搞定了,你拿到的一般就是一个简单的HTTP请求接口,用PHP的cURL或者file_get_contents函数就能调用了,返回的数据通常是整理好的JSON格式,非常规整,你只需要写个循环,把里面你要的字段,比如微博正文、发布时间、发布人昵称等等,解析出来,然后拼装成SQL的INSERT语句,插到你的MySQL数据库里就行了,这种方法可以说是最简单实用的,因为你付出的主要就是一点可能有的费用,但节省了大量的开发时间和被反爬虫折磨的精力,缺点是数据可能不是百分百实时,或者有调用次数的限制,但对于很多要求不极致的项目来说,完全够用了。
如果不想花钱,或者想自己掌控整个过程,那就得走另一条路:模拟移动端APP请求,这个方法技术含量高一些,但比直接抓网页要稳定,核心是你要想办法拿到一个能正常访问微博API的访问凭证,也就是access_token,有了它,你的请求就相当于一个“合法”的APP在操作,怎么拿这个token呢?通常需要你先去微博开放平台创建一个应用,但个人应用权限很低,几乎拿不到读取微博内容的关键接口权限,所以实际操作中,很多人会研究一些非官方的手段,比如通过抓包工具分析手机微博APP的通信,找到它登录和获取token的流程,然后在PHP代码里模拟这个流程,这个过程非常繁琐,涉及到模拟登录、处理加密密码、解析跳转、获取授权码code、最后再用code换token,每一步都可能遇到坑,一旦你成功拿到了一个可用的access_token,后面的事情就简单多了,你可以用这个token去调用微博提供的某些API,获取用户发布的微博”接口,调用方法和上面说的类似,也是用PHP发起HTTP GET请求,带上token参数,接口返回的也是JSON数据,解析、入库的步骤就和第一种方法一样了。
还有一种比较古老但现在很难行得通的方法是直接抓取手机版或PC版网页,就是直接用PHP的cURL去访问某个人的微博主页,比如https://weibo.com/u/1234567890,然后把返回的HTML代码下载下来,你需要用DOM解析工具,比如PHP Simple HTML DOM Parser这个库,去分析HTML结构,像剥洋葱一样一层层找到包含微博内容的那个DIV标签,再把里面的文字、图片链接等信息提取出来,这个方法听起来直接,但现在是难度最高的,因为微博网页的结构非常复杂且经常变动,你今天写好的解析规则,可能下个星期微博前端一改版就完全失效了,更重要的是,网页的反爬虫机制非常完善,会对频繁访问的IP进行封禁,或者弹出验证码,你需要处理Cookie、User-Agent伪装,甚至代理IP池来应对封禁,这会让整个项目变得非常庞大和复杂,除非是练手学习,否则对于想要“简单实用”非常不推荐这种方法。
如果你追求的是“简单实用”,那么优先级应该是:第一,优先考虑付费的第三方数据平台API,用金钱换时间和稳定性,第二,如果非要自己动手,那就去研究如何模拟APP获取access_token,然后调用官方(或类官方)API,虽然前期折腾,但一旦打通后期相对稳定,最下策才是去直接抓取解析网页,那会是一个无底洞。
无论用哪种方法,把数据存到数据库的环节是共通的,你需要在MySQL里建一张表,表里的字段根据你要存的信息来定,通常会有:id(自增主键)、weibo_id(微博自身的ID,唯一标识)、content(微博正文)、publish_time(发布时间)、user_name(发布者)等等,PHP这边,就是用PDO或者mysqli扩展连接数据库,然后把解析好的数据通过参数化查询的方式插入进去,这样做是为了防止SQL注入攻击,整个流程可以写成一个PHP脚本,然后用服务器的定时任务cron来定期执行,比如每隔十分钟跑一次,实现自动化的抓取和存储。

本文由凤伟才于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80973.html