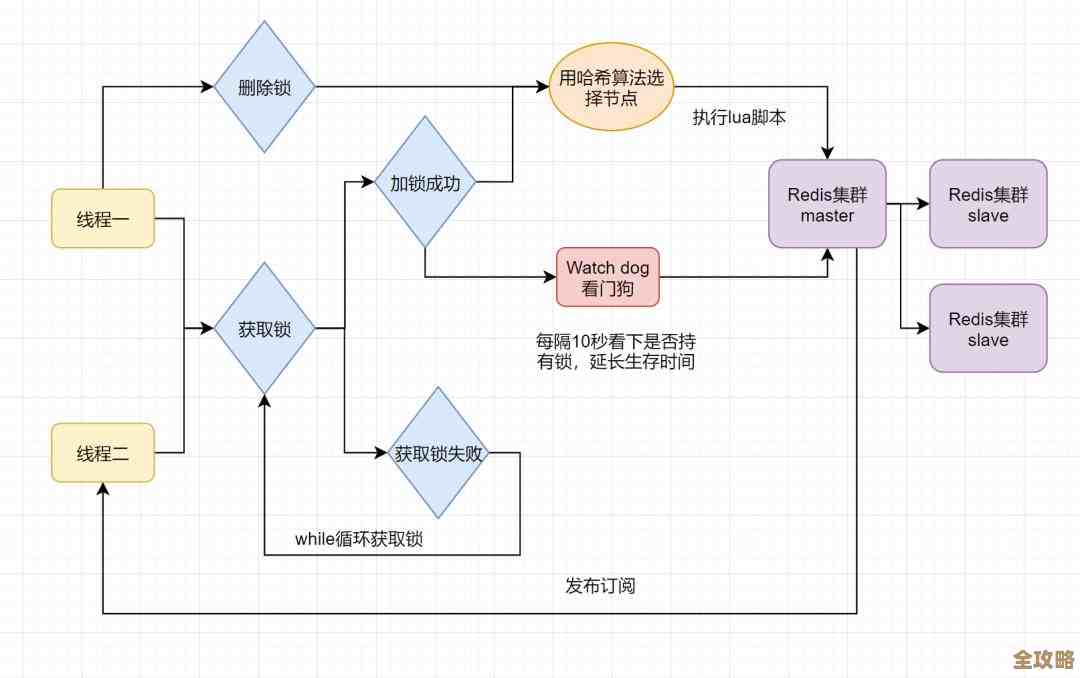
说说那些常用的人脸数据库,特别是lfw和它的来头与用途

说到人脸识别技术,我们经常在手机解锁、支付验证甚至小区门禁上用到它,感觉既方便又神奇,但这项技术可不是凭空变出来的,它的发展离不开大量“教材”的训练,这些“教材”就是人脸数据库,你可以把人脸数据库想象成一本巨大的、包含成千上万张人脸照片的相册,每张照片都带有详细的标签,比如这个人的名字、性别、年龄、拍照时的光线角度等等,研究人员就用这些相册来“教”电脑如何认人。

在众多人脸数据库中,有一些是元老级别的,非常常用,比如Yale人脸数据库,它历史很悠久,主要特点是包含了同一个人在不同光照条件和不同表情下的照片,用来训练算法应对光线变化和做鬼脸的情况,再比如FERET数据库,它是由美国国防部高级研究计划局推动创建的,规模在当时算很大了,包含了大量不同姿态、不同光照下的人脸图像,对人脸识别研究的标准化起到了关键作用,还有CASIA-WebFace,这是中国科学院自动化研究所收集的,从网络上抓取并标注了超过一万个人的照片,因为数据量巨大且来自真实网络环境,对推动深度学习在人脸识别中的应用功不可没。

在这些数据库中,有一个名字几乎是人脸识别领域无人不知、无人不晓的,那就是LFW,LFW是“Labeled Faces in the Wild”的缩写,直译过来就是“野外标注人脸”,这个名字起得非常形象,因为它里面的照片都不是在摄影棚里规规矩矩拍的,而是完全“野生”的——全部从网络上抓取而来,来源是各种新闻图片,这意味着照片里的人脸处于真实、复杂、不受控制的环境中。

LFW的来头可不小,它由美国马萨诸塞大学阿默斯特分校的研究团队在2007年创建并发布,根据马萨诸塞大学阿默斯特分校计算机视觉实验室公开的项目介绍,创建LFW的初衷就是为了解决当时人脸识别研究面临的一个核心瓶颈:实验室里开发的算法,在精心控制的灯光、均匀的背景、端正的姿势下表现完美,但一到现实世界——比如从一张混乱的新闻图片里认人——就立刻“抓瞎”,性能急剧下降,研究者们意识到,必须用一个更接近真实世界挑战的数据集来推动技术进步,LFW便应运而生。
LFW具体是什么样的呢?根据其官方文档,LFW数据集包含了超过13000张从网络上收集的名人人脸图像,每张图像都标注了对应人物的姓名,总共有5749个不同的人,其中大约1680人有两张或两张以上的图像,这些图片的“野”体现在方方面面:光照千差万别,有的过曝有的昏暗;姿势五花八门,有正脸、侧脸、抬头、低头;表情丰富,有笑有怒;甚至还有遮挡,比如有人戴着眼镜、帽子,或者被东西挡住一部分脸,图片的分辨率、清晰度也各不相同,这一切都完美复现了我们在现实生活中会遇到的各种情况。
正因为LFW的这种“野性”,它的主要用途非常明确:作为衡量人脸识别算法在非受限条件下性能的基准,在LFW出现之前,各个研究团队都在自己的小数据集上测试,结果没有可比性,LFW提供了一个公共的、公认的“考场”,研究人员开发出新的算法后,都会拿到LFW这个考场上来跑一跑,看看它的“考试成绩”如何,这个成绩通常用识别准确率来表示,我们的算法在LFW上达到了99.2%的准确率”,一时间,LFW的排行榜成了衡量人脸识别技术水平的黄金标准,极大地促进了全球范围内的技术竞争和快速发展。
可以说,LFW的出现是人脸识别研究的一个分水岭,它迫使整个领域从“温室”走向“野外”,催生了一大批能够应对现实世界复杂性的鲁棒算法,我们今天能够享受到如此便捷和准确的人脸识别技术,LFW这个“功臣”数据库在背后起到了不可磨灭的推动作用,虽然随着技术发展,出现了更大、更难的数据库,但LFW作为经典基准和历史见证者的地位,依然非常重要。
本文由度秀梅于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/81019.html